 Alexander Reelsen
Alexander ReelsenElasticsearch - Securing a search engine while maintaining usability
TLDR; This is a rather long blog post from one of my talks, that I started giving in 2018 and have been doing until 2020. We will dive into how Elasticsearch ensures security using the Java Security Manager and seccomp. Please grab a coffee and take all the time to read it. Also, ping me, when you have any questions. Happy to discuss!
Even though this talk can be found on YouTube, I think that that reading simplifies things a lot (and allows embedding links all the time), as you can go with your own pace, skip parts of it and it is easier to resume. If you still prefer the video, check out my presentations page and follow the links.
Also, I have removed a few slides, and replaced them with a couple of paragraphs in some cases, should you be wondering why it does not align with a presentation.
Lastly, one of my main goals of this post is to make you think of your own application and how you can improve its security and usability.
If you do not run as a service, it is very likely that customers will download your product and run it on their own infrastructure, which means you do not have any influence on the execution environment, yet you want to make sure, that your service runs in the most optimal requirement.
Introduction

Keeping software secure is not easy. It’s often claimed that secure software is hard to use. Folks try to back this with weird triangles of something. You should not buy into that. Keep thinking about a problem, talk to your users, and see if you can find solutions that does not make a software necessarily harder to use, just because you have to secure it in a certain way. We will see a couple of examples during this talk.
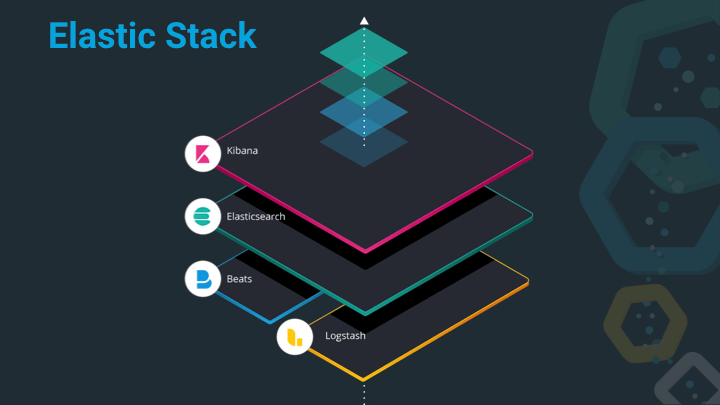
The Elastic Stack consists of Elasticsearch, Kibana, Beats and Logstash. Each of those serve a different purpose, with Elasticsearch being the heart of the stack, responsible for storing, querying and aggregating data. Kibana is the window into the stack and much more than a dashboarding tool nowadays, it also has a ton of management and monitoring functionality built-in, that ensure, you don’t need to be a wizard with the Elasticsearch API. In order to index data into Elasticsearch you can either roll your own tooling or use either Beats or Logstash. Logstash being a very generic ETL tool (to me it’s more of a very versatile Swiss army knife), while Beats are small and concise programs for a single use-case, for example to tail a logfile and sent it over to Elasticsearch, you would use filebeat, whereas for gathering system or service statistics you would go with metricbeat.
In order to cover certain use cases, solutions are basically vertical slides across the stack, for example Observability with APM, Infrastructure and Service Monitoring that reuse parts of the stack like Machine Learning.

Let’s do a quick dive into Elasticsearch. On the outside, Elasticsearch is a
search engine, that can be used for classic full-text search (show me all
documents that contain brown shoes), analytics (group all documents found
by their category_id and return counts per category) or geo search (show
me all cars I can buy in a radius of fifty kilometers) - of course you can combine all
three together as well. All of this happens near real-time, so the time
between indexing data and making it available for search is usually less
than a second.
Elasticsearch is distributed, so you can run it on a single node, or hundreds of instances together as a cluster.
Elasticsearch is scalable, you can scale it up (buy faster hardware) or scale it out by adding more nodes.
Elasticsearch is highly available and resilient. So, what does this mean? If you add more nodes to a cluster, the likelihood of a single node failure increases. However, Elasticsearch will figure out a node failure by itself and also take the proper measures to ensure that your data is available as configured (more than one copy somewhere in the cluster), and thus you should not need to do any maintenance in case a node goes down.
The interface of Elasticsearch is HTTP & JSON - a protocol and a object notation that every developer should feel good with.
The following is a fully uneducated non-scientific based guess: Elasticsearch is a popular tool, so I assume, that there are hundreds of thousands of instances worldwide. This makes security a permanent concern.

This will be the agenda for most the article, with a few extras before the end, that I usually leave out due to time constraints.
- Security: Feature or non-functional requirement?
- The Java Security Manager
- Production mode vs. Development mode
- Plugins
- Scripting languages

This is a tricky one, as the answer about security as a non-functional requirement is very dependent, on whom you ask. Everyone will tell you that software needs to be secure (if that’s the case, do you have a specific budget for this, or maybe even just a specific training budget?).
Asking a developer, you will get told, that you can do things like defensive programming, check the OWASP top 10, etc.
Asking a business person, they might tell you not to store or deal with credentials or credit card numbers in order to not need expensive audits or certifications.
Asking someone non-technical, they might claim their software is not exploitable. This is where you can stop the conversation :-)
Coming back to a more technical perspective you will hear things like preventing unintended resource access. There is a famous CVE entry about a dishwasher directory traversal bug in a Miele dishwasher. Fixing this issue could be done in several ways. One could try and write a fix to prevent this kind of attack, or one could think about this a little different and just fully deactivate that web server in a frigging dishwasher! What would be the better solution?
Also, security best practices[TM] like the least privilege principle or reducing the impact surface in case of a compromise are often labeled as non-functional requirements - but are they really? I guess, as often in live, it depends…

Integrations with other security tools like Kerberos, or adding Authorization/Authentication are usually functional requirements. This post will not cover any of those, despite all of these are available in the Elastic Stack.

This is a special one for my German readers. If you use
dict.leo.org to
translate security or
safety you will end up with
the same German noun Sicherheit. Even though the Germans have a word for
everything, it’s usually about crazy compound words (which is another
fascinating challenge for full text search), but sometimes words just don’t
translate well. This makes borders and definitions blurry sometimes and even
harder to express.
- Integrity checks: Depending on the use-case you need integrity to ensure that no one has maliciously changed your data (for example checking a TLS packet) vs. check summing the data written on disk to ensure that no bits have been flipped. Depending on the use-case this could be more a security or a safety use-case.
- Preventing
OutOfMemoryError: A famous exception in java, telling the application that no more memory could be allocated (let’s disregard for a moment that this is more subtle due to different kinds of memory that cannot be allocated any more). Preventing this, keeps your service up and running. Many Java based services prefer to kill the whole process instead of being in a ghost state as it is an unrecoverable error. - Preventing deep pagination: A regular search will run into memory pressure, when you page really deep or/and when your search is hitting a lot of shards in order to return the top-k documents. See the definitive guide for some more information. Memory pressure will slow down your system and thus this can prevent a DoS attack, but also keeps your service fast and alive. We will revisit this later.
- Not exposing credentials in APIs: This is clearly a security issue. Whenever you need to provide APIs to expose configuration, make sure sensitive settings do not get exposed. Elasticsearch has a marker for all settings, if they are considered sensitive or not.
- Do you know what application is doing, when running out of disk space? What happens when you try to write more data? Will it fail gracefully? Will it lose data? This is less of a security, but more of a resiliency/safety feature, which every code base should have a test for, that is writing data to a local disk. I’m not a fan of network based logging, so I suppose most applications still do :-)
- Calling
System.exitstops the currently running JVM in Java. Elasticsearch being a service running in the background, it should ensure that no one is able to call this method, not even if there is a security issue in the scripting engine. How does your application handle this?

This is a nice grouping criteria for security issues as well
Known knowns: Things that you know and should be fixed immediately on your side. Telling your customers in a lengthy doc how to secure your product by setting certain permissions is a classic for this case. Instead of doing so, just provide a distribution with the correctly set permissions and solve this problem for others.Known Unknowns: Security issues that you would have fixed when you had figured them out before others. An exploit your code leading to privilege escalation or a classic buffer overflow.Unknown unknowns: Security issues that you will be affected from, but have no chance of fixing yourself. This does not refer to security issues like third party dependency problems, but rather broader problems like Spectre, which are hard to fix on the application, especially on a high level language.

Let’s dive into the Java Security Manager. Have you ever called
System.setSecurityManager() in your code or enabled the security manager
on the command line?
It is surprisingly hard to find any code of documentation for most of the JVM based software out there, with some notable exceptions (Apache Lucene, Apache Solr, Elasticsearch, some tomcat documentation, and Cassandra seems to use it in a more lightweight fashion).

Imagine the following system calls in your application (let’s imagine this is Elasticsearch):
connect(192.168.1.1:9300), a network connection to another Elasticsearch node - that is a perfectly valid thing to do and I’d encourage this with Elasticsearch being a distributed systemwrite('/var/log/elasticsearch.log'), logging things into a file in order to debug them later. Sounds like a good plan to me!unlink('/var/lib/elasticsearch/...'), deleting files that are not needed any more within the Elasticsearch data directory, is a valid and good thing!

Now, look at these system calls. They are very similar to the ones above from the perspective of the operating system
open('/etc/passwd'): Elasticsearch does not need to open any files in/etc/except its own configuration files. However, this is just opening a file description, and maybe just read only…- `connect(‘gopher://bit.coin/miner.tgz’): This is just a network connection initiation, what can be evil about that? Oh, a bitcoin miner?! Maybe I don’t want that to happen.
unlink /var/lib/elasticearch: Well, just another cleanup, right? A cleanup of all my data is probably not what I wanted
As you can see, from the perspective of the application (or the application developer) these calls should never be issued by Elasticsearch. In that case we can consider the application compromised.

And this is where a sandbox comes in. Imagine a sandbox has the knowledge about good and bad system calls, and can just reject the bad ones…

Java has a built-in sandbox mechanism dubbed the Java Security Manager,
preventing accesses for certain things by default, that can be granted by
being explicitly specified via a list of Permissions in a Policy.
These permissions could be the ability to read or write files, to connect, listen or accept a socket, to retrieve certain URL scheme or set/retrieve properties.
So, why does this piece of software exist in the JVM, even though it is not used a lot nowadays? It’s basically a protection against running untrusted code - what every one of us nowadays is doing all day long in our browser. A browser is also making sure, that code from a third party website cannot open a file or scan your hard disk. Many moons ago Java Applets were used for this kind of functionality, where one could run (well, at least start) java code in the browser.
In order to secure this code, a user configured policy was used to ensure that the downloaded code could do no harm. You could set the ability to read configuration files, but disallow sending data over the network.

Imagine the Java Security Manager as a shell around your own java code (is it really your own code?) that uses the policy as a configuration to decide which code is allowed to run.
Let’s look how this is implemented in the JDK. This is
java.io.File.exists() - a method that checks if the file exists. Of course
all of us have migrated to NIO2 nowadays, so that we would usually never see
this piece of code :-)
You can see, that there is a small piece of code, that retrieves the configured security manager, and executes an additional check, if the security manager is set.
public boolean exists() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(path);
}
if (isInvalid()) {
return false;
}
return ((fs.getBooleanAttributes(this) & FileSystem.BA_EXISTS) != 0);
}
Following the checkRead method we see the following code snippet
public void checkRead(String file) {
checkPermission(new FilePermission(file,
SecurityConstants.FILE_READ_ACTION));
}

Let’s go for a few examples. You can find those on a GitHub repository as well.
We will start the security manager programmatically in all cases, so we do not have to fiddle with command line arguments
Let’s imagine the following POJO
package de.spinscale.security.samples;
public class MyPojo {
private static final Boolean FOO = Boolean.TRUE;
private final String value;
MyPojo(String value) {
this.value = value;
}
@Override
public String toString() {
return "value=[" + value + "], FOO=[" + FOO + "]";
}
}
We can use reflection to retrieve a fields value, even though it was marked as private.
package de.spinscale.security.samples;
import java.lang.reflect.Field;
public class Sample01 {
// Simple reflection example, accessing a private field
public static void main(String[] args) throws Exception {
MyPojo pojo = new MyPojo("my_value");
Field f = pojo.getClass().getDeclaredField("value");
f.setAccessible(true);
String value = (String) f.get(pojo);
System.out.println("value = " + value + "");
}
}
Reflection also allows you to change private fields
package de.spinscale.security.samples;
import java.lang.reflect.Field;
public class Sample02 {
// Reflection example, changing private field
public static void main(String[] args) throws Exception {
MyPojo pojo = new MyPojo("my_value");
System.out.println(pojo);
Field f = pojo.getClass().getDeclaredField("value");
f.setAccessible(true);
f.set(pojo, "my_new_value");
System.out.println(pojo);
}
}
You saw the MyPojoo.FOO field above? It’s private and static and final, so
it should not be changed, right? Well..
package de.spinscale.security.samples;
import sun.misc.Unsafe;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class Sample03 {
// changing a private static final field, WTF?!
public static void main(String[] args) throws Exception {
MyPojo pojo = new MyPojo("my_value");
System.out.println(pojo);
Field field = pojo.getClass().getDeclaredField("FOO");
setStaticFinalField(field, Boolean.FALSE);
System.out.println(pojo);
}
// courtesy Heinz Kabutz https://www.javaspecialists.eu/archive/Issue272.html
// this requires RuntimePermission accessClassInPackage.sun.misc
private final static Unsafe UNSAFE;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (ReflectiveOperationException e) {
throw new IllegalStateException(e);
}
}
public static void setStaticFinalField(Field field, Object value) throws ReflectiveOperationException {
if (!Modifier.isStatic(field.getModifiers()) || !Modifier.isFinal(field.getModifiers())) {
throw new IllegalArgumentException("field should be final static");
}
Object fieldBase = UNSAFE.staticFieldBase(field);
long fieldOffset = UNSAFE.staticFieldOffset(field);
UNSAFE.putObject(fieldBase, fieldOffset, value);
}
}
The next example reads /etc/passwd and dumps it via the network to
localhost:9999 - the easiest way to run an app there would be the
invocation of netcat via nc -l 9999 and then run this app. This is a
classic exfiltration use-case (albeit a rather dumb one).
package de.spinscale.security.samples;
import java.net.Socket;
import java.nio.file.Files;
import java.nio.file.Paths;
public class Sample04 {
// open a network socket to exfiltrate some data
// start nc -l 9999 on another console
public static void main(String[] args) throws Exception {
try (Socket socket = new Socket("localhost", 9999)) {
byte[] bytes = Files.readAllBytes(Paths.get("/etc/passwd"));
socket.getOutputStream().write(bytes);
}
}
}
And lastly executing a shell command
package de.spinscale.security.samples;
import com.google.common.io.CharStreams;
import java.io.InputStreamReader;
public class Sample05 {
// execute arbitrary commands
public static void main(String[] args) throws Exception {
Process process = Runtime.getRuntime().exec("/bin/ls -l");
process.waitFor();
String output = CharStreams.toString(new InputStreamReader(process.getInputStream()));
System.out.println(output);
}
}
All of the above examples are allowed by default, when you start an application. This means you have to be sure that your code does not do such a thing, that any of your dependencies do not do any of those things and that there is absolutely no possibility to inject code into your application that gets executed (custom templates being uploaded, script engines, etc). This means a lot of work and validation and responsibility on your side!
Enabling the security manager would reject all of those operations. However, you still would need to allow some. Let’s take a look how to set the proper permissions to allow all of the above examples again.
package de.spinscale.security.samples;
import java.io.FilePermission;
import java.lang.reflect.ReflectPermission;
import java.net.SocketPermission;
import java.security.Permission;
import java.security.Policy;
import java.security.ProtectionDomain;
public class SecurityManagerSamples {
public static void main(String[] args) throws Exception {
Policy.setPolicy(new CustomPolicy(
// samples 1-3
new ReflectPermission("suppressAccessChecks"),
new RuntimePermission("accessDeclaredMembers"),
// Sample 3
new RuntimePermission("accessClassInPackage.sun.misc"),
// sample 4
new SocketPermission("localhost", "resolve,connect"),
new SocketPermission("127.0.0.1:9999", "resolve,connect"),
new FilePermission("/etc/passwd", "read"),
// sample 5
new FilePermission( "/bin/ls", "execute")
));
System.setSecurityManager(new SecurityManager());
Sample01.main(new String[0]);
Sample02.main(new String[0]);
Sample03.main(new String[0]);
Sample04.main(new String[0]);
Sample05.main(new String[0]);
}
public static final class CustomPolicy extends Policy {
private final Permission[] permissions;
CustomPolicy(Permission ... permissions) {
this.permissions = permissions;
}
@Override
public boolean implies(final ProtectionDomain domain, final Permission permission) {
for (Permission p : permissions) {
if (p.getName().equals(permission.getName()) &&
p.getClass().getName().equals(permission.getClass().getName())) {
return true;
}
}
return false;
}
}
}
Imagine for the above code, someone could have the ability to modify
state of your application that you considered absolutely unchangeable by
setting it static, final and private. That ability could mean, someone
changes the hard coded conversion ratio between EUR and another currency, that
could result in a very financial issue.
Quick reminder, that there are other ways to mitigate this and that there are also possibilities that this is not a problem in production due to inlining or usage of java modules and thus resulting in the inability to change such classes, so consider this a demo use-case.
Also, in case you are wondering, if this is supposed to work like that, it is! The JLS (Java Language Specification) mentions the ability to change final fields.
In some cases, such as deserialization, the system will need to change the final fields of an object after construction. final fields can be changed via reflection and other implementation-dependent means.

The above examples already show a few drawbacks of using the Java Security Manager.
- Policies are hard-coded, either during start up with a policy file or before setting the security manager programmatically. This is a good thing, you just need to be aware of it, especially if you have dynamic applications.
- By default, DNS lookups are cached forever. You can disable this behavior (this has been done in Elasticsearch as well), but it is important to be aware of that default, especially in cloud environments where names and IP addresses tend to change more often.
- Dependencies! You need to know about them, more than the version. Do you know which of your dependencies are actually using reflection on startup?
- Many libraries are not even tested with the security manager, because it is so uncommon to enable the security manager. This poses a problem, as there is a probability that a completely different code path (even within your dependencies) may be run, compared to the non security manager activated code path. This means, you need to have proper and enough CI in place, to catch these things, and you also need proper integration tests.
- Granularity is an issue, as you need to figure out what all of your dependencies are doing. This can take a lot of time!
- The security manager is not a protection against everything, things like
stack overflows or
OutOfMemoryErrorexceptions can still occur. The same applies for java agents, as those have the ability to change the bytecode to whatever they want.

So let’s dive into a few examples, what is done in the Elasticsearch code base to reduce impact.

How do Elasticsearch and the security manager work together? Basically Elasticsearch needs to read its configuration files, for example to figure out the different file paths to read and write files (configuration, log files, data files), executes some native code (we’ll get to that) and then starts the security manager when everything is in place.
Also, a custom security manager is used. One of the advantages of the whole
security manager framework in the JVM is the fact, that it’s pretty
extensible. The reason for the custom security manager is the fact, that the
default one is still somewhat optimized for the applet use-case. For example
allows the JVM to call System.exit(), which in an applet based environment
makes a lot of sense to just exit the JVM (and thus not suffer and future
security issues), but for a long-running service like Elasticsearch this is
not a good idea.
The custom security manager also enforces thread group security and allows
only a few classes to call System.exit(). See the SecureSM
class in Elasticsearch.
The Policy class, which by default reads from a single configuration file,
is extended to take the elasticsearch.yml file based configuration into
account (allowing for static and dynamic configurations) and can be seen
at
ESPolicy.
You can also implement custom permissions, as done with the SpecialPermission that is an additional check that needs to be called to ensure that unprivileged code runs in the right place.
Next, let’s take a closer look at how Elasticsearch initializes and starts up.

JVM Startup
When Elasticsearch starts up, it first starts a small JVM with parse and figure out some options and configurations and then starts the JVM with the probably much bigger amount of heap configured.
As soon as the JVM starts up, it is doing all the JVM work, finding the
main method, executing that, which then is doing the initialization of
Elasticsearch, like getting a logger up and running to see error messages as
early as possible.
Read configuration file
Before Elasticsearch can do anything else, it always needs to read the configuration files, figuring out where certain file paths are and take action based on this information.
Native system calls
The next step is executing native system calls, and this is where things get interesting, as Java is considered a high level language, but Elasticsearch is doing some rather low level things in here.
One of the native system calls is done, in order to figure out, if Elasticsearch is running as the root user. Well, more exact, if Elasticsearch is running as UID 0, which in turn is usually the user with the most capabilities under Linux.
This is all the code needed for such a check.
/** Returns true if user is root, false if not, or if we don't know */
static boolean definitelyRunningAsRoot() {
if (Constants.WINDOWS) {
return false; // don't know
}
try {
return JNACLibrary.geteuid() == 0;
} catch (UnsatisfiedLinkError e) {
// this will have already been logged by Kernel32Library, no need to repeat it
return false;
}
}
This way, we can check on start up if we run as root and throw an exception should that be the case (only if we’re not on windows though)
// check if the user is running as root, and bail
if (Natives.definitelyRunningAsRoot()) {
throw new RuntimeException("can not run elasticsearch as root");
}
The dependency above is the JNA library, allowing you to execute native calls in Java - just what is needed.
There are more native calls that are executed on start up. And one of the most important is the setting of native system call filters, called seccomp under Linux.
One of the assumptions here is the fact that the security manager could fail, and (possibly due to historic reasons) Elasticsearch should still not be able to fork any processes, as this would clearly indicate an illegal and malicious activity.
seccomp is a way for a process to tell the operating system to never allow
a set of system calls. You can go far more granular, but this is sufficient
in Elasticsearch. When starting up, the Elasticsearch process tells the
operating system to deny all execve, fork, vfork or execveat system
calls, that all indicate another process start.
Even though this model is called seccomp only under Linux, Windows, Solaris, BSD and osx all have similar mechanism to prevent forking of processes. The following code samples exclusively focus on Linux, though.
// BPF installed to check arch, limit, then syscall.
// See https://www.kernel.org/doc/Documentation/prctl/seccomp_filter.txt for details.
SockFilter insns[] = {
/* 1 */ BPF_STMT(BPF_LD + BPF_W + BPF_ABS, SECCOMP_DATA_ARCH_OFFSET),
/* 2 */ BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch.audit, 0, 7),
/* 3 */ BPF_STMT(BPF_LD + BPF_W + BPF_ABS, SECCOMP_DATA_NR_OFFSET),
/* 4 */ BPF_JUMP(BPF_JMP + BPF_JGT + BPF_K, arch.limit, 5, 0),
/* 5 */ BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch.fork, 4, 0),
/* 6 */ BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch.vfork, 3, 0),
/* 7 */ BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch.execve, 2, 0),
/* 8 */ BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch.execveat, 1, 0),
/* 9 */ BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ALLOW),
/* 10 */ BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ERRNO | (EACCES & SECCOMP_RET_DATA)),
};
// seccomp takes a long, so we pass it one explicitly to keep the JNA simple
SockFProg prog = new SockFProg(insns);
prog.write();
long pointer = Pointer.nativeValue(prog.getPointer());
The above code snippet looks a bit weird at first. The reason for this is, that
it is written in BPF, which you might know when writing a tcpdump or
wireshark filter. BPF stands for Berkeley Packet Filter.
BPF programs have a couple of properties, that are important for fast and reliable execution. For example, there is a defined end and you cannot have loop structures (which is one of the reasons, why the above may look a little weird at first). You can see the above mentioned system calls in the snippet, that will be aborted due to this seccomp policy, in case they get called. You could also kill the thread or even the whole process, but in the case of Elasticsearch aborting it, but keeping the process up and running sounds like a good idea.
if (linux_syscall(arch.seccomp, SECCOMP_SET_MODE_FILTER, SECCOMP_FILTER_FLAG_TSYNC, new NativeLong(pointer)) != 0) {
method = 0;
int errno1 = Native.getLastError();
if (logger.isDebugEnabled()) {
logger.debug("seccomp(SECCOMP_SET_MODE_FILTER): {}, falling back to prctl(PR_SET_SECCOMP)...",
JNACLibrary.strerror(errno1));
}
if (linux_prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, pointer, 0, 0) != 0) {
int errno2 = Native.getLastError();
throw new UnsupportedOperationException("seccomp(SECCOMP_SET_MODE_FILTER): " + JNACLibrary.strerror(errno1) +
", prctl(PR_SET_SECCOMP): " + JNACLibrary.strerror(errno2));
}
}
// now check that the filter was really installed, we should be in filter mode.
if (linux_prctl(PR_GET_SECCOMP, 0, 0, 0, 0) != 2) {
throw new UnsupportedOperationException("seccomp filter installation did not really succeed. seccomp(PR_GET_SECCOMP): "
+ JNACLibrary.strerror(Native.getLastError()));
}
logger.debug("Linux seccomp filter installation successful, threads: [{}]", method == 1 ? "all" : "app" );
The above snippet is doing the initialization. You can see the methods
linux_syscall(arch.seccomp, ...), linux_prctl(PR_SET_SECCOMP, ...) and
linux_prctl(PR_GET_SECCOMP, ...). The reason why there are two system
calls to install a seccomp policy is the fact, that newer kernels have a
dedicated seccomp syscall, whereas older kernels use prctl with some
special parameters.
In case you are wondering, this kind of seccomp support has been in the Linux kernel for a long time, in kernel 3.17. And to complete the history, there was a much simpler seccomp implementation already in kernel 2.6.12, so the idea has been around for a long time.
There are two more native calls executed on startup. The first configures
the handler, when someone types ctrl+c to abort the process under Windows.
The second one is about memory locking. Memory locking is a method to tell the operating system, that this process should never be swapped out - you could also disable swap to achieve the same. Memory locking needs to be allowed by the operating system, and then another JNA call will be executed.
If you are interested you can check the source in
Bootstrap.initializeNatives().
Now we’ve covered all the native system calls.
Set Security Manager
Before the security manager can be set, all the permissions from the different modules and plugins are collected, then the security manager is set.
Load plugins
There is a dedicated chapter about plugins, you can check that one out below.
Bootstrap checks
This is one of my favorite topics to talk about. Coming back again to the problem of not being able to influence the execution environment a downloaded product is running. With a Java application you do not know the operating system, the Linux distribution, the type of hard disks, the JVM implementation being used and many other factors.
So, is there the possibility to enforce checks for a good, stable and performant setup to run Elasticsearch on application start?
If that is the case, the next question pops up immediately: Should we enforce these checks all the time at the possible expense, that the complexity of setup may scare away developers, who just want to get up and running?
Let’s answer the last part of the question first, before diving deeper into bootstrap checks.
Your development setup is rarely similar to your production one. You usually run a single node cluster to test if your application is working as expected, and as soon as you start more complex tasks like bench marking you move away from development machines.
So, how can a smooth development experience ensured, while a strict production setup is required? What could be a good indicator?
Well, turns out in a distributed system, the network might be a good indicator. If you are running on localhost only (the default in Elasticsearch), then it’s considered development mode and the checks will be skipped. The moment, you are listening on a network address, the checks will be run on start up. This is the code doing the checks
static boolean enforceLimits(final BoundTransportAddress boundTransportAddress, final String discoveryType) {
final Predicate<TransportAddress> isLoopbackAddress = t -> t.address().getAddress().isLoopbackAddress();
final boolean bound =
!(Arrays.stream(boundTransportAddress.boundAddresses()).allMatch(isLoopbackAddress) &&
isLoopbackAddress.test(boundTransportAddress.publishAddress()));
return bound && !"single-node".equals(discoveryType);
}
This worked well… until a software defined network like Docker comes into
play. Then the node had a non loopback ip address. The solution to this was
to add another configuration option to mark a node as a single-node that will
never form a cluster using the discovery.type setting in the Elasticsearch
configuration.
Let’s get into the details of bootstrap checks and what they actually do.
This is the list of bootstrap checks.
// the list of checks to execute
static List<BootstrapCheck> checks() {
final List<BootstrapCheck> checks = new ArrayList<>();
checks.add(new HeapSizeCheck());
final FileDescriptorCheck fileDescriptorCheck
= Constants.MAC_OS_X ? new OsXFileDescriptorCheck() : new FileDescriptorCheck();
checks.add(fileDescriptorCheck);
checks.add(new MlockallCheck());
if (Constants.LINUX) {
checks.add(new MaxNumberOfThreadsCheck());
}
if (Constants.LINUX || Constants.MAC_OS_X) {
checks.add(new MaxSizeVirtualMemoryCheck());
}
if (Constants.LINUX || Constants.MAC_OS_X) {
checks.add(new MaxFileSizeCheck());
}
if (ConstantsLINUX) {
checks.add(new MaxMapCountCheck());
}
checks.add(new ClientJvmCheck());
checks.add(new UseSerialGCCheck());
checks.add(new SystemCallFilterCheck());
checks.add(new OnErrorCheck());
checks.add(new OnOutOfMemoryErrorCheck());
checks.add(new EarlyAccessCheck());
checks.add(new G1GCCheck());
checks.add(new AllPermissionCheck());
checks.add(new DiscoveryConfiguredCheck());
return Collections.unmodifiableList(checks);
}
You can roughly split the type of checks into checks regarding the configuration of the operating system - like checking for the number of file handles that can be handled in parallel or the number of threads that can be created - and configuration of the JVM - like not specifying a bad garbage collector the client mode.
This is what a bootstrap check looks like, which implements the
BootstrapCheck interface and returns either a success or a failure.
static class FileDescriptorCheck implements BootstrapCheck {
private final int limit;
FileDescriptorCheck() {
this(65535);
}
protected FileDescriptorCheck(final int limit) {
if (limit <= 0) {
throw new IllegalArgumentException("limit must be positive but was [" + limit + "]");
}
this.limit = limit;
}
public final BootstrapCheckResult check(BootstrapContext context) {
final long maxFileDescriptorCount = getMaxFileDescriptorCount();
if (maxFileDescriptorCount != -1 && maxFileDescriptorCount < limit) {
final String message = String.format(
Locale.ROOT,
"max file descriptors [%d] for elasticsearch process is too low, increase to at least [%d]",
getMaxFileDescriptorCount(),
limit);
return BootstrapCheckResult.failure(message);
} else {
return BootstrapCheckResult.success();
}
}
// visible for testing
long getMaxFileDescriptorCount() {
return ProcessProbe.getInstance().getMaxFileDescriptorCount();
}
}
This check retrieves the allowed file descriptor count (you can use ulimit
under many Linux distributions to figure this out) and returns a failure if
it is less than roughly 65k.
Another interesting check is the G1GCCheck, as it really shows, how useful
such an infrastructure can be. Let’s take a look at the check
/**
* Bootstrap check for versions of HotSpot that are known to have issues that can lead to index corruption when G1GC is enabled.
*/
static class G1GCCheck implements BootstrapCheck {
@Override
public BootstrapCheckResult check(BootstrapContext context) {
if ("Oracle Corporation".equals(jvmVendor()) && isJava8() && isG1GCEnabled()) {
final String jvmVersion = jvmVersion();
// HotSpot versions on Java 8 match this regular expression; note that this changes with Java 9 after JEP-223
final Pattern pattern = Pattern.compile("(\\d+)\\.(\\d+)-b\\d+");
final Matcher matcher = pattern.matcher(jvmVersion);
final boolean matches = matcher.matches();
assert matches : jvmVersion;
final int major = Integer.parseInt(matcher.group(1));
final int update = Integer.parseInt(matcher.group(2));
// HotSpot versions for Java 8 have major version 25, the bad versions are all versions prior to update 40
if (major == 25 && update < 40) {
final String message = String.format(
Locale.ROOT,
"JVM version [%s] can cause data corruption when used with G1GC; upgrade to at least Java 8u40", jvmVersion);
return BootstrapCheckResult.failure(message);
}
}
return BootstrapCheckResult.success();
}
// more methods here ...
}
This check checks for a very specific configuration (java8 in a specific version, by oracle and using G1 garbage collector). If that configuration is found, an error is returned, as a Lucene Developer figured out that this specific configuration can lead to bad JIT code resulting corrupted Lucene data.
Lastly, there is one security specific check, which checks for the setting of
the AllPermission.
static class AllPermissionCheck implements BootstrapCheck {
@Override
public final BootstrapCheckResult check(BootstrapContext context) {
if (isAllPermissionGranted()) {
return BootstrapCheck.BootstrapCheckResult.failure("granting the all permission effectively disables security");
}
return BootstrapCheckResult.success();
}
boolean isAllPermissionGranted() {
final SecurityManager sm = System.getSecurityManager();
assert sm != null;
try {
sm.checkPermission(new AllPermission());
} catch (final SecurityException e) {
return false;
}
return true;
}
}
That permission allows you to bypass all the permission configuration and
simply allow everything. This is absolutely unwanted behavior for
Elasticsearch. The AllPermission has an excellent use when you want to trace
the required permission for your applications, but you do never want to use
this in production and this is the reason why there is an extra check for this.
If you’re interested in more bootstrap check information, there is a blog post about bootstrap checks titled Annoying you now instead of devastating you later, which is very well spent time.
Network enablement
This is the last step after all the steps above were successful, Elasticsearch will start its network functions and try to join or form a cluster and service requests.
Plugins

From a security perspective the best thing would be to not offer any plugin functionality. Plugins are a way to load and execute other’s people code. From a maintenance perspective however plugins are usually a necessity. Plugins are a good way to keep functionality out of the core, while still providing it or allowing users to build functionality for their own specific and narrow use-case, even though it might not work for every use-case.
The Elasticsearch team is rather strict about putting code into the core, first you would have to maintain it for a lifetime, but also because it needs to satisfy the ability to scale The functionality needs to work with few data on a single shard, or terabytes of data across a cluster. Often developers have a compelling feature that works well with a little bit of data (for example for their ecommerce shop). Even though this is unlikely to be supported by the core, the developer could still write a plugin to support this.
Plugins have a few capabilities
- Plugins are really just zip files with a special structure.
- Each plugin can have its own jars and dependencies in any version (as long as it is not a direct dependency from the core, like Lucene or Jackson)
- Each plugin is loaded with its own classloader to achieve the above functionality
- Each Plugin can have its own security permissions, so that only the mustache plugin requires reflection abilities
- Each Plugin can have its own bootstrap checks
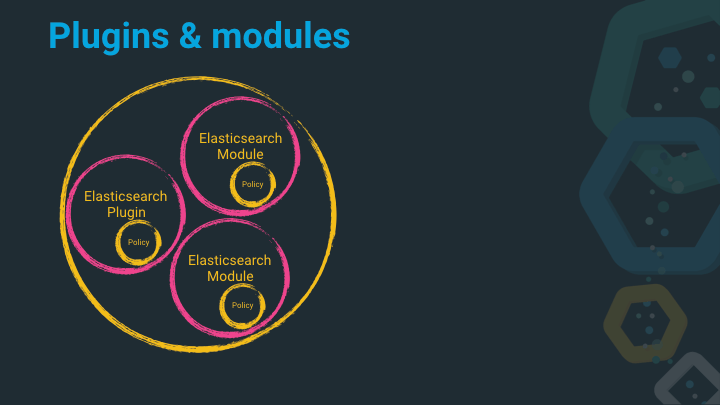
Elasticsearch itself is making use of the above capabilities by loading a bunch of code on startup with the above isolation features. These plugins are called modules and cannot be removed, they are always there, but loaded in isolation with their own classloader, their own security permissions and custom bootstrap checks.
Let’s take a look at a few sample permissions
grant {
// needed to do crazy reflection
permission java.lang.RuntimePermission "accessDeclaredMembers";
};
The above snippet is the plugin-security.policy file from the
lang-mustache module. It enables reflection, as most template languages
require reflection for object introspection. With the new wave of next
generation web frameworks doing more things at compile time than run-time,
there is a refreshing alternative called
qute, that is part of quarkus and
actually not doing this.
grant {
// needed to generate runtime classes
permission java.lang.RuntimePermission "createClassLoader";
// expression runtime
permission org.elasticsearch.script.ClassPermission "java.lang.String";
permission org.elasticsearch.script.ClassPermission "org.apache.lucene.expressions.Expression";
permission org.elasticsearch.script.ClassPermission "org.apache.lucene.search.DoubleValues";
// available functions
permission org.elasticsearch.script.ClassPermission "java.lang.Math";
permission org.elasticsearch.script.ClassPermission "org.apache.lucene.util.MathUtil";
permission org.elasticsearch.script.ClassPermission "org.apache.lucene.util.SloppyMath";
};
This snippet comes from the lang-expression module, which is a scripting
language used to have custom scoring formulas in Lucene. It’s performance
trick is create bytecode from the input and thus be somewhat on par with
the performance of a java class.
However, the ability to create byte code requires you to create a class
loader, which is considered a security risk, if you can sneak arbitrary code
into the script. The solution here is a custom ClassPermission to only
allow certain classes on top of a basic set, but reject all others.
grant codeBase "${codebase.netty-common}" {
// for reading the system-wide configuration for the backlog of established sockets
permission java.io.FilePermission "/proc/sys/net/core/somaxconn", "read";
// netty makes and accepts socket connections
permission java.net.SocketPermission "*", "accept,connect";
};
grant codeBase "${codebase.netty-transport}" {
// Netty NioEventLoop wants to change this, because of https://bugs.openjdk.java.net/browse/JDK-6427854
// the bug says it only happened rarely, and that its fixed, but apparently it still happens rarely!
permission java.util.PropertyPermission "sun.nio.ch.bugLevel", "write";
};
The above snippet even goes a step further. It grants a certain permission
only to a specific jar. The ${codebase.netty-common} snippet is replaced
on build time with the jar name of the current netty-common package. Only
code, that is within this jar is actually allowed to connect to the network
or accept connections. Any other code will be rejected.
Introducing Painless - a scripting language for Elasticsearch
Imagine the use-case of summing up two fields together into a new field,
before a document gets indexed. This sounds super simple for a so called
ingest processor in Elasticsearch. You retrieve the bytes_in and
bytes_out field and create a bytes_total field out of that.
Imagine this tiny functionality would require you to write a custom plugin that contains a custom processor. You would need to maintain and test this plugin, keep up with the Elasticsearch release cadence, follow code deprecations and so forth. What happens when the field name changes or you would like to add another field?
In order to not have to do this, scripting is supported within Elasticsearch, allowing you to have tiny generic code snippets at several points in Elasticsearch, for example
- Ingest node: The ability to modify the document before it gets indexed
- Queries: Dynamic script filter or scripted fields
- Aggregations: Dynamic bucketing
- Templating: Search templates, Alerting and many other places
Scripting has always been a part in Elasticsearch, even in the early 0.x versions. The standard scripting language used to be MVEL and there were plugins for a bunch of languages like python, JavaScript (even before JSR 223).
Over time there was move from MVEL to Groovy, as groovy had a sandbox feature allowing you to blacklist and whitelist classes as well as some performance improvements.
However, due to various reasons with the sandbox behavior and also execution speed it was decided to write a custom script language that looks very much like Java, with a few ideas adapted from groovy to make it more concise.
One of the key drivers of this outside of execution speed was also the fact, that it is super hard to take an existing language like groovy, adapt it to your own security requirements and keep its speed and also not play whack-a-mole with security issues.
Luckily one of the developers of the already mentioned Lucene expression language was working at Elastic and tasked with the development of Painless. Painless has a couple of important features
- Sandboxing
- Allow execution of methods on a per method base
- Opt-in to regular expressions
- Prevent endless loops by detecting them due to controlling the sandbox
- Extensibility (add own code to scripting, whitelist more classes)
This is a snippet of a prevented loop
PUT foo/_doc/1?refresh
{
"foo" : "bar"
}
GET foo/_search
{
"query": {
"script": {
"script": """
def a = 123;
while (true) {
a++;
if (a > Integer.MAX_VALUE) {
break;
}
}
return true;
"""
}
}
}
GET foo/_search
{
"query": {
"script": {
"script": """
for (def i = 0; i < 1_000_000 ; i++) {}
return true;
"""
}
}
}
Also, other things have been taken care of in scripting languages like detection of self references to make sure as a protection of stack overflows.
PUT foo/_doc/1?refresh
{
"foo" : "bar"
}
# exception coming up
GET foo/_search
{
"query": {
"script": {
"script": """
def a = [:];
def b = [:];
a.b = b;
b.a = a;
return a.toString() != "ABC"
"""
}
}
}
If you implement a custom scripting language, don’t forget to test the bad cases as well!
Mark Sensitive Settings
I talked about this at the beginning briefly, but I think it is important to
revisit. One of Elasticsearch features is the ability to mark a setting
(something you set in the YAML configuration or via the Update Cluster
Settings
API)
as being filtered. This means, that it will not be returned, when calling
one of the APIs to return settings.
public static final Setting<String> SUBSCRIPTION_ID_SETTING =
Setting.simpleString("cloud.azure.management.subscription.id",
Property.NodeScope, Property.Filtered);
You can see the Filtered property here. That property is checked, whenever
settings are returned.
However, more recent version of Elasticsearch feature another, preferred way of storing sensitive data, to ensure that it is not stored in clear text in the YAML file: This feature is named Secure Settings and requires the elasticsearch-keystore tool to manage.
A secure setting is registered like this in the code
private static final Setting.AffixSetting<SecureString> SETTING_URL_SECURE =
Setting.affixKeySetting("xpack.notification.slack.account.", "secure_url",
(key) -> SecureSetting.secureString(key, null));
You can see the SecureSetting.secureString() call. However, this snippet shows
another settings feature, the use of so-called affix settings. Affix
settings allow you to have groups of settings based on an arbitrary name. In
this example you can have several arbitrarily named slack accounts like
xpack.notification.slack.account.ops_account.secure_url
xpack.notification.slack.account.marketing_account.secure_url
xpack.notification.slack.account.developer_account.secure_url
So, why is there a dedicated keystore? You can optionally password protect that keystore, so that there is no clear text secret stored on disk. This is the preferred way of dealing with sensitive settings.
Registering Settings
The above example implied another common practice in Elasticsearch. The enforcement of registering all settings. So, any setting that can be configured in the YAML file, needs to be registered. Plugins can also register they own settings, should they need to.
Enforcing this comes with a really nice feature (apart from knowing all the settings, and preventing typos in the configuration). If you try to start Elasticsearch with an invalid option
bin/elasticsearch -E cluster.namr=rhincodon
Then Elasticsearch will fail to start, but also leave a very useful error message for you
unknown setting [cluster.namr] did you mean [cluster.name]?
With the knowledge of all the existing settings it is very fast and easy to look up settings that look similar to the one that was configured and tell the user about it.
The strictness of settings also helps YAML indentation issues and will return an error there.
Deep pagination vs. search_after
This is less of a security feature, but again more of a safety one to make sure that Elasticsearch keeps up and running without consuming too much resources.
Let’s dig into the issue of deep pagination first
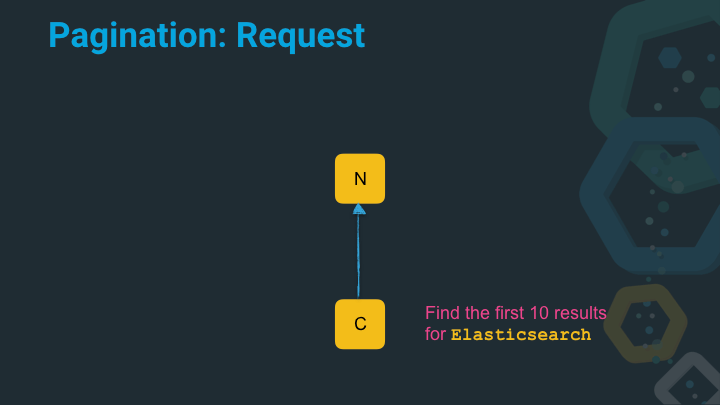
In this example the coordinating node (that is the Elasticsearch node in a
cluster that receives a query) queries the node for the term Elasticsearch
and would like to receive the first ten results. For the sake of simplicity
let’s assume that each node is only holding a single shard.
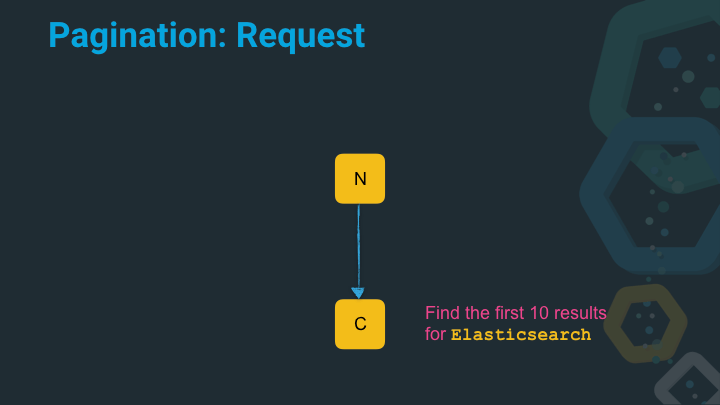
The node executes a single search and returns the found results.
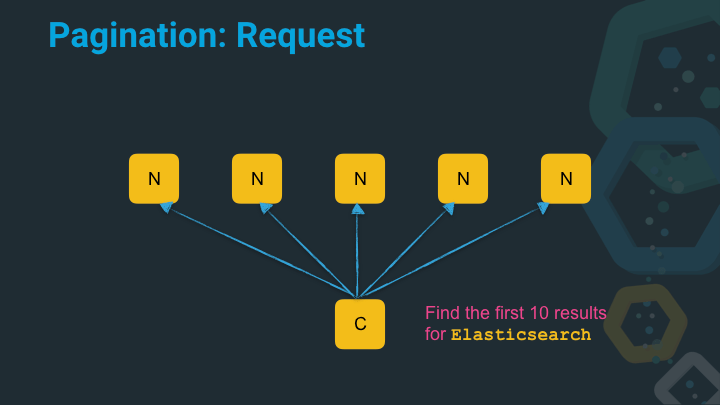
Let’s add some spice and ask five nodes (or to be more specific in the Elasticsearch world: ask five nodes, which hold one shard each) to get the first top ten results.
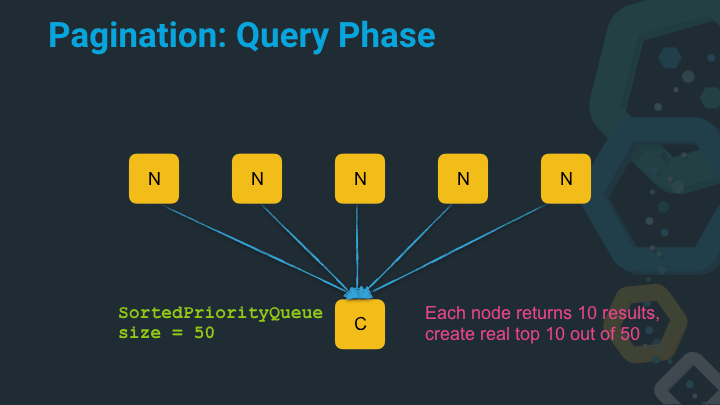
In this case, we actually have to do more work on the coordinating node before we can return anything to the client. As we now end up with 50 results on the client, that need to be sorted by score (or whatever sort criteria was specified) and then only the real top 10 needs to be processed further.
This gathering of the data is called the query phase. The query gets executed on all nodes and the next step is to retrieve the actual documents for the top ten list.
Both phases can folded into a single phase, if only a single shard gets queried.
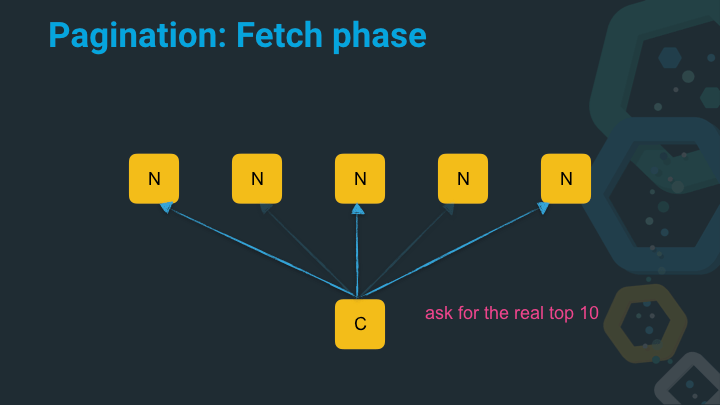
Now the coordinating node asks the nodes that are part of the top ten list to retrieve the original JSON.
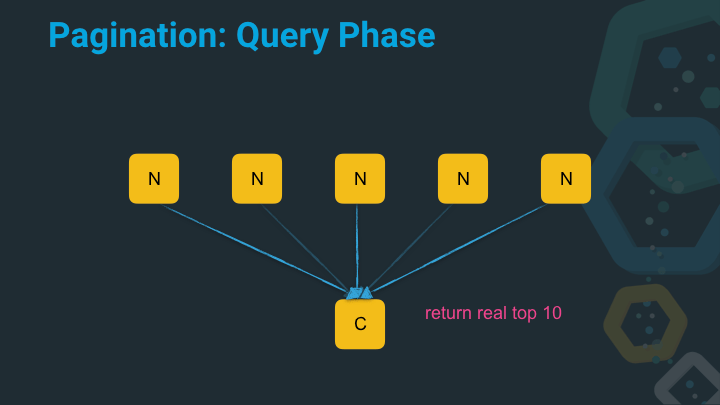
Now we’re at the point that the coordinating node can return the data to the client. As you can see, by default a distributed search operation is a two step operation. Now let’s see where the problem with this approach is.
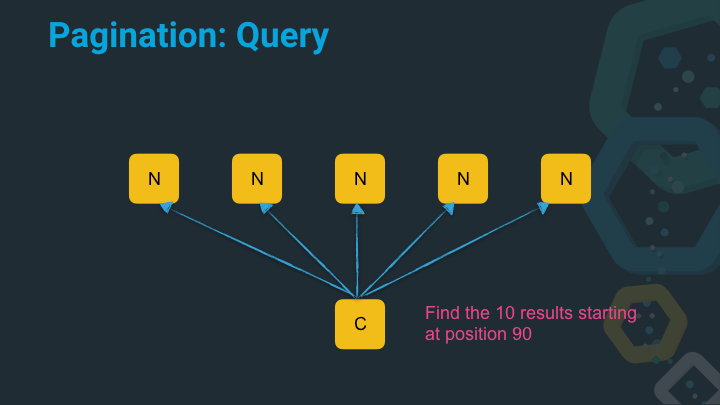
In this example the coordinating node asks not for the top ten results, but for the results from 90 till 100.
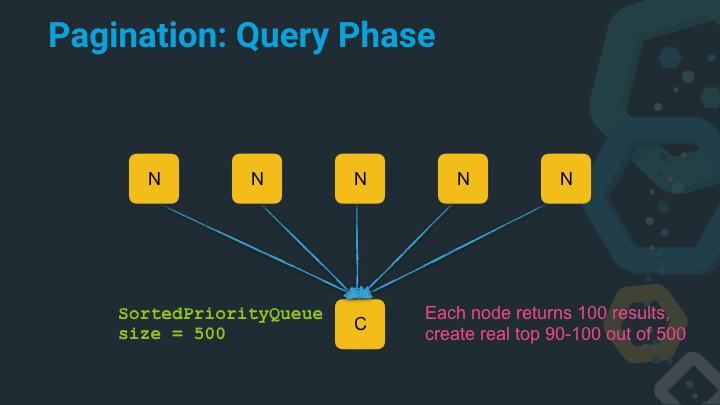
Now things are a bit different. We actually end up with a fair share of more documents on the coordinating node that require sorting, before we can execute the fetch phase and collect the document.
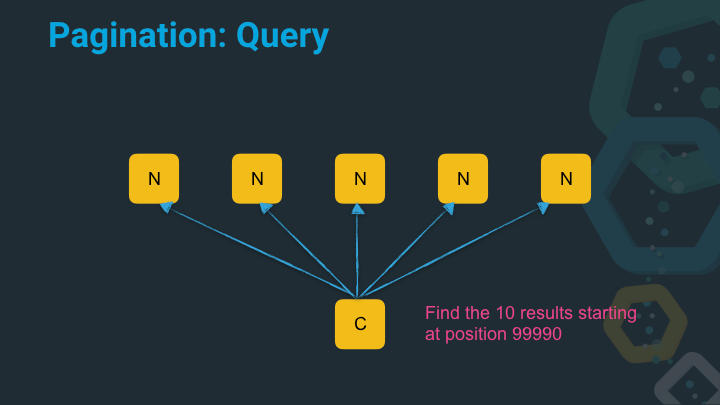
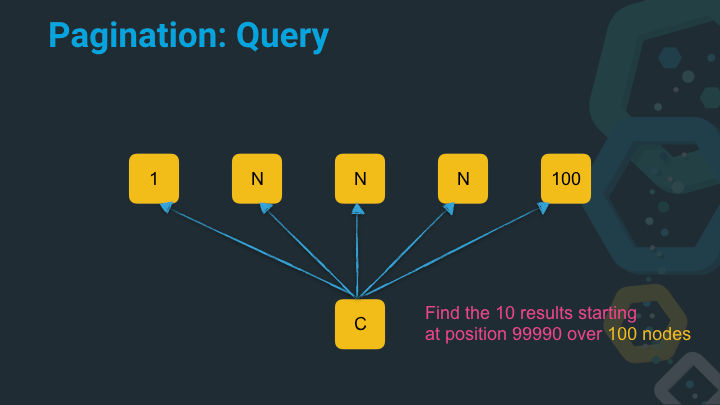
Now let’s imagine we try to get the results starting at position 99990 from five nodes.
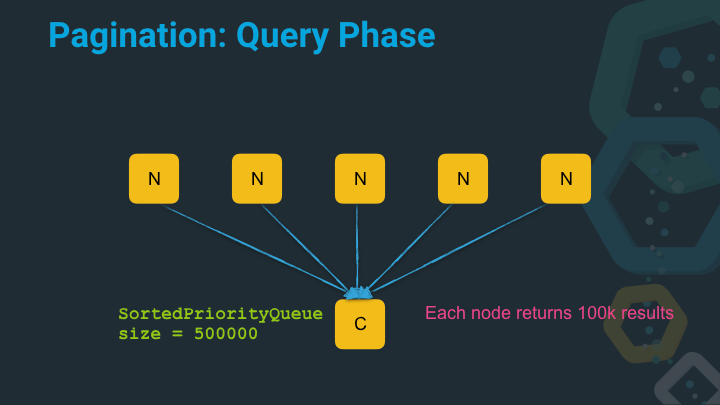
Our sorted priority queue to sort the results now has a serious size and needs to sort 500k entries! That takes time and requires memory.
Let’s do this one more time and see it gets worse if we have to paginate deep and query a lot of nodes. Imagine you got a hundred nodes and would like to receive the results starting at position 99990.
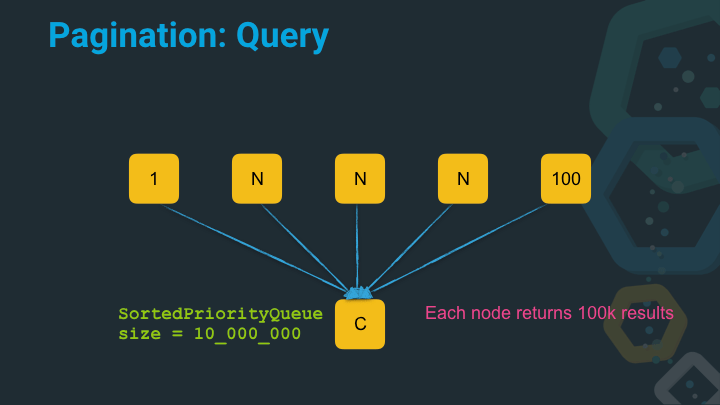
OK, so this is crazy right. A single search request - imagine you have hundreds per second - now requires a queue with ten million entries to be sorted. This is extremely inefficient, slow and will lead to garbage collections to clear this structure up after a search.
So, what can be done about it?

The solution is to use a feature called search_after in Elasticsearch.
Instead of dealing with integer positions when specifying where to start with the next page, you just specify the previous position based on the values of the last hit. This way every node, can go to the last value in its dataset and just return the next ten documents. So the number of the documents to be sorted in the sorted priority queue is always linear, based on the number of nodes (or shards) and the number of expected results.
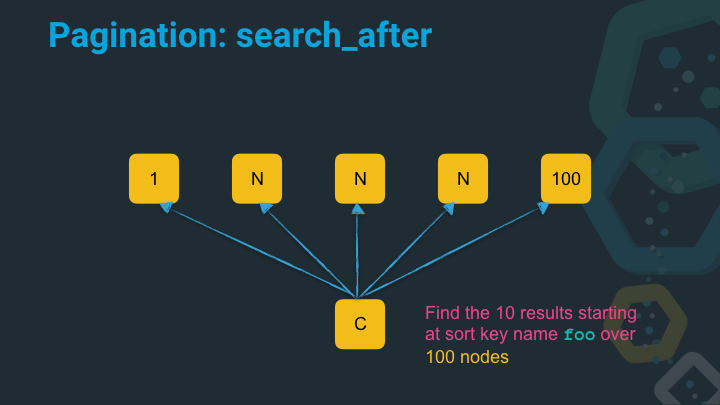
In this example we specify the sort key name foo to get ten results from a hundred nodes - which for the sake of the example resembles the exact position of 99990 in our dataset.
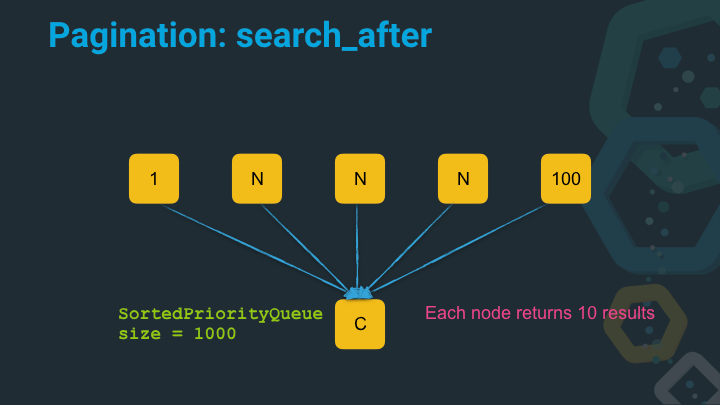
The sorted priority queue will have a size of 1000 instead of 10 million - and it will always remain at that size, no matter how deep you continue to go through your dataset.
Side note: There have been a ton of improvements in 7.x versions of Elasticsearch to figure out which shards to query, and also to not query all shard in parallel and reuse the results of the already queried shards to reduce the returned results. This is only the most naive way to explain the problem.
Summary
Wow, you almost made it. Bear with me just one more minute.

Let’s start with the more technical summary
- Not using the Java Security Manager - what’s your excuse? - This is my fine art of trolling you after reading page after page after page. Setting up the security manager in an existing codebase and making it mandatory is hard and time-consuming. Elasticsearch has added support for the security manager in Elasticsearch 2, but left a flag in there to disable the security manager. This flag got removed in Elasticsearch 5 only, one major version later (I know, it looks like three, but it’s not). For many projects the amount of time required to spend to adapt an existing codebase might not be worth it economically. For an very much used service like Elasticsearch however, it was.
- Scripting is important. Is your implementation secure? - Scripting implementations need to be tested inside out to make sure you cannot do something bad with it, like executing arbitrary code. Again this not a simple thing to do, as isolation is always hard.
- Use operating system features - The operating system is a battle proven system over decades. I highly doubt you will outsmart that experience for generic use-cases - you will however for concrete use-cases, so figure out when to switch. I really do not want you to reimplement the security manager in java or seccomp functionality!
- If you allow for plugins remain secure - Try to keep other people’s code out of your project, is the best you can do from a security perspective. In times of open code this is a really contradictory advice, but this is not about writing the code, but more about the code running. If you can’t, audit everything really carefully.
One more thing to remember: All the things I wrote about in here are open, so you can look them up in Elasticsearch, understand how they work, and incorporate them into your own projects. I encourage you to do that, as you will figure out, that many smaller features do not require a lot of code on your side.

Now let’s talk about the process part of things
- Development has big impact on security - Developers can secure software before it goes to production. This is where the most money on security incidents is saved. Make use of that. I’d rather wait for a feature than to find myself on frontpage news with a security incident.
- Operations is happy to help what is there out of the box - Talk to non-developers about security features. Your ops folks will (well, should) know all the inside-outs of seccomp, apparmor, selinux and figure out how you can utilize (and monitor!) these kind of things to lock down your application.
- Developers know their application best. - Boring repetition, but to reiterate you cannot expect to have operation folks know about the proper java security manager configuration for the application you as a developer wrote. Collaborate on this and access all the operations knowledge to improve your software.
- Don’t reinvent, check out existing features! - Boring repetition, part
2. Favor the Security Manager and seccomp over your fancy self written
wrapper to prevent calling
Runtime.getRuntime().exec() - Developers are responsible for writing secure code - before things go sideways! - It’s responsibility to keep security in mind, whenever you write code. All. The. Time.
Resources
Code
Blog posts & Articles
- Seccomp in the Elastic Stack, giving you an overview where and how seccomp is actually used
- Bootstrap Checks - Annoying you now instead of devastating you later
- All about Scripting, a blog post about a couple of scripting decisions before painless was used, from August 2014
- Scripting and Security, another blog post about scripting and security from 2014 way before painless, just to make you aware that this has been a continuous process over years
- Java Security Guide, including security manager information
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, github or reach me via Email.
If there is anything to correct, drop me a note and I am happy to do so!
Same applies for questions. If you have question, go ahead and ask!