 Alexander Reelsen
Alexander ReelsenImplementing a Linkedin like search as you type with Elasticsearch
TLDR; When searching across most social networks, your direct contacts will be ranked higher than other users. Let’s take a look at the search of Linkedin and see if we can replicate something similar with Elasticsearch.
Note, that this post only deals with autocomplete/search as you type suggestions and will not deep dive into the search results once a search has been sent, resulting in a search result page.
Let’s look at Linkedin
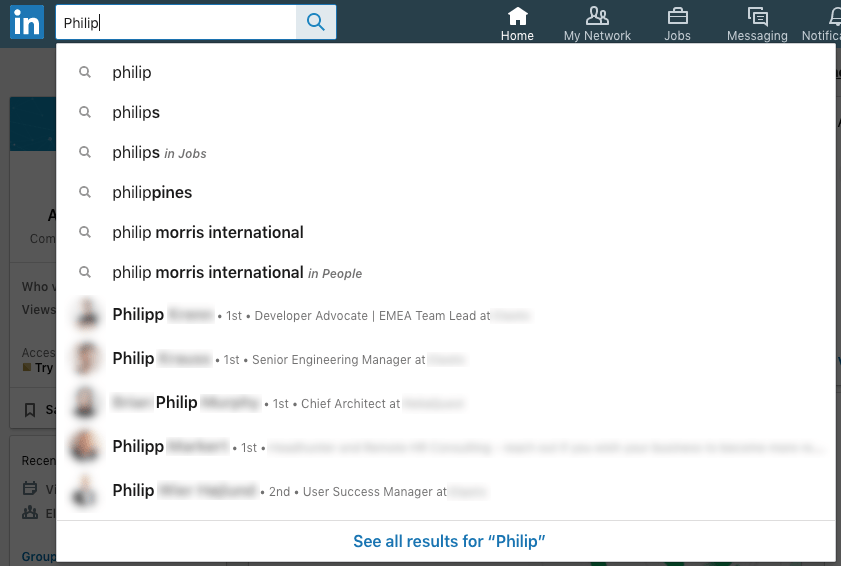
So let’s check out this search response. The input was Philip. We will ignore
any search results or suggestions that are not people - the first 6
suggestions just show you, what else you might be searching for.
Focus on the person results, the last five in the list. The first four hits
are in my direct network. The first two hits are working at Elastic as well.
The third hit has Philip as part of his first name. Only the last hit is
not a direct contact - but also works at my current employer.
Another interesting thing to note is, that this was apparently a prefix
search as Philipp with a two p’s at the end is a valid match as well.
Before gathering requirements, let’s try a second search.
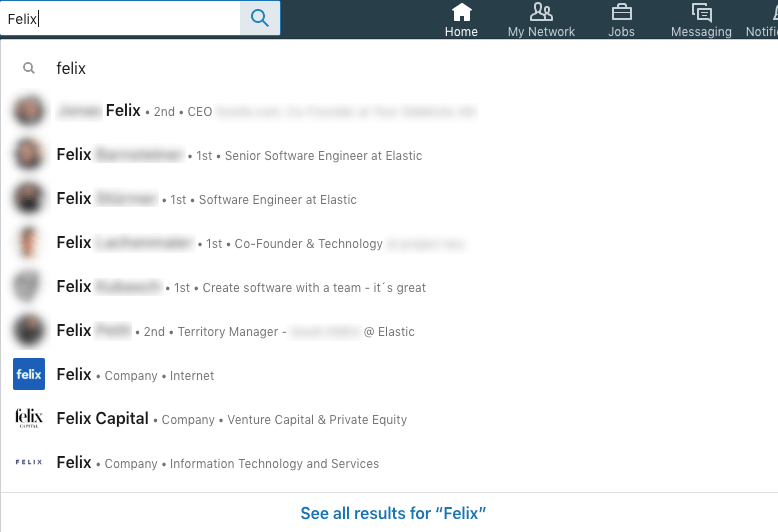
Now this is interesting, as it differs heavily from the first search. I do not have the slightest idea, why this does not give you any non-person results at the top. In addition there seem to be companies named Felix as well. But let’s look at the person search results.
The first hit this time is not from my direct contacts, despite having plenty of Felixes (that’s the plural, right?) in my direct contacts.
Apparently an exact match on the surname is scored pretty high.
The next hits are direct contacts, colleagues first, then other companies. The last hit is a 2nd degree hit, but working at Elastic as well.
Scoring rules
Let’s try to derive some scoring rules from both results
- First and last name a searched (and those are two different fields)
- Exact matches on the surname rank highest (remember TF/IDF? It’s likely that Felix is a rare surname in comparison to the first name, so maybe this has happened without tuning).
- Prefix matches are OK (see
Philipvs.Philipp) - Own contacts are ranked higher
- 2nd degree contacts at your own employer rank higher
Data Model
Next up, let’s come up with a data model.
First, fields required for full text search: first name, last name,
full name.
Second, fields required in addition to search fields for ranking:
employer, direct contacts.
Third, fields required for display: title, employer.
Mapping the data model
I will not explain the mapping for now, as some mapping features are needed later to improve the query, let’s just stick with this for now.
PUT social-network
{
"mappings": {
"properties": {
"name": {
"properties": {
"first": {
"type": "text",
"fields": {
"search-as-you-type": {
"type": "search_as_you_type"
}
}
},
"last": {
"type": "text",
"fields": {
"search-as-you-type": {
"type": "search_as_you_type"
}
}
},
"full": {
"type": "text",
"fields": {
"search-as-you-type": {
"type": "search_as_you_type"
}
}
}
}
},
"employer": {
"type": "text"
},
"contacts": {
"type": "keyword"
},
"title": {
"type": "keyword"
}
}
}
}
Also, let’s create an index pipeline to create the full name automatically
PUT _ingest/pipeline/name-pipeline
{
"processors": [
{
"script": {
"source": "ctx.name.full = ctx.name.first + ' ' + ctx.name.last"
}
}
]
}
Next up, let’s index a few people, some direct contacts, some colleagues and some no contacts at all.
PUT social-network/_bulk?pipeline=name-pipeline
{ "index" : { "_id": "alexr" }}
{ "name": { "first" : "Alexander", "last" : "Reelsen" }, "employer" : "Elastic", "title" : "Community Advocate", "contacts" : [ "philippk", "philipk", "philippl" ] }
{ "index" : { "_id": "philipk" }}
{ "name": { "first" : "Philip", "last" : "Kredible" }, "employer" : "Elastic", "title" : "Team Lead"}
{ "index" : { "_id": "philippl" }}
{ "name": { "first" : "Philipp", "last" : "Laughable" }, "employer" : "FancyWorks", "title" : "Senior Software Engineer" }
{ "index" : { "_id": "philippi" }}
{ "name": { "first" : "Philipp", "last" : "Incredible" }, "employer" : "21st Century Marketing", "title" : "CEO" }
{ "index" : { "_id": "philippb" }}
{ "name": { "first" : "Philipp Jean", "last" : "Blatantly" }, "employer" : "Monsters Inc.", "title" : "CEO" }
{ "index" : { "_id": "felixp" }}
{ "name": { "first" : "Felix", "last" : "Philipp" }, "employer" : "Felixia", "title" : "VP Engineering" }
{ "index" : { "_id": "philippk" }}
{ "name": { "first" : "Philipp", "last" : "Krenn" }, "employer" : "Elastic", "title" : "Community Advocate"}
To keep things simple, I only added the list of direct contacts to myself, in a real application, every user would have their own list of contacts.
Search for users
OK, the easiest search first, an arbitrary search for Philipp, this time
only in the first name field.
GET social-network/_search
{
"query": {
"match": {
"name.first": "Philipp"
}
}
}
If you want to reduce the result fields, append
filter_path=**.name.full,**._score to the URL to only include the full
name and the score.
You see, that all documents are scored the same (because most fields only
contain Philipp in the first name, with the exception of Philipp Jean,
which is scored last). There is no concrete order, as the scores are the
same and no sorting tie breaker has been defined.
Score own contacts higher
OK, so my user has a list of contacts. How can their influence scoring. We
can use a should in a bool query. Let’s assume that only Philipp Krenn
is my colleague. I could look his id up (philippk) and add this like this:
GET social-network/_search?filter_path=**.name.full,**._score
{
"query": {
"bool": {
"should": [
{
"term": {
"_id": {
"value": "philippk"
}
}
}
],
"must": [
{
"match": {
"name.first": "Philipp"
}
}
]
}
}
}
The response looks like this:
{
"hits" : {
"hits" : [
{
"_score" : 1.438688,
"_source" : {
"name" : {
"full" : "Philipp Krenn"
}
}
},
{
"_score" : 0.43868804,
"_source" : {
"name" : {
"full" : "Philipp Laughable"
}
}
},
...
]
}
}
LGTM! Philipp is now scored higher. But looking up the id manually before each query is waaaaaaay too tedious (imagine doing this for thousands of contacts). Elasticsearch can do that for us already! There is a terms lookup feature built-in. Using this we can look up the list of contacts of my user automatically like this.
GET social-network/_search?filter_path=**.name.full,**._score
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
}
],
"must": [
{
"match": {
"name.first": "Philipp"
}
}
]
}
}
}
this returns
{
"hits" : {
"hits" : [
{
"_score" : 1.438688,
"_source" : {
"name" : {
"full" : "Philipp Laughable"
}
}
},
{
"_score" : 1.438688,
"_source" : {
"name" : {
"full" : "Philipp Krenn"
}
}
},
{
"_score" : 0.43868804,
"_source" : {
"name" : {
"full" : "Philipp Incredible"
}
}
},
{
"_score" : 0.31562757,
"_source" : {
"name" : {
"full" : "Philipp Jean Blatantly"
}
}
}
]
}
}
All right, the first two hits are direct contacts, so that sounds like a
good implementation to me. Whenever you add a new contact, make sure the
contacts array is updated and you are good to go.
There’s more to it however.
Score exact matching surname higher
We saw the surname being matched much higher. Let’s try that, so far we only searched for the first name, but maybe we can search across first and last names using a multi match query.
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
}
],
"must": [
{
"multi_match": {
"query": "Philipp",
"fields": [
"name.last",
"name.first"
]
}
}
]
}
}
}
Let’s see the results:
{
"hits" : {
"hits" : [
{
"_score" : 1.6739764,
"_source" : {
"name" : {
"full" : "Felix Philipp"
},
"employer" : "Felixia"
}
},
{
"_score" : 1.6063719,
"_source" : {
"name" : {
"full" : "Philipp Laughable"
},
"employer" : "FancyWorks"
}
},
{
"_score" : 1.6063719,
"_source" : {
"name" : {
"full" : "Philipp Krenn"
},
"employer" : "Elastic"
}
},
{
"_score" : 0.6063718,
"_source" : {
"name" : {
"full" : "Philipp Incredible"
},
"employer" : "21st Century Marketing"
}
},
{
"_score" : 0.44027865,
"_source" : {
"name" : {
"full" : "Philipp Jean Blatantly"
},
"employer" : "Monsters Inc."
}
}
]
}
}
Thanks to the standard scoring algorithm (and our very small data set) matching the last name scores the highest.
Score colleagues higher
If we find two direct contacts, but one user work for your employer, how about rating them higher? Luckily we can just add a should clause.
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
},
{
"match": {
"employer": "Elastic"
}
}
],
"must": [
{
"multi_match": {
"query": "Philipp",
"fields": [
"name.last",
"name.first"
]
}
}
]
}
}
}
the results are these
{
"hits" : {
"hits" : [
{
"_score" : 2.5486999,
"_source" : {
"name" : {
"full" : "Philipp Krenn"
},
"employer" : "Elastic"
}
},
{
"_score" : 1.6739764,
"_source" : {
"name" : {
"full" : "Felix Philipp"
},
"employer" : "Felixia"
}
},
{
"_score" : 1.6063719,
"_source" : {
"name" : {
"full" : "Philipp Laughable"
},
"employer" : "FancyWorks"
}
},
{
"_score" : 0.6063718,
"_source" : {
"name" : {
"full" : "Philipp Incredible"
},
"employer" : "21st Century Marketing"
}
},
{
"_score" : 0.44027865,
"_source" : {
"name" : {
"full" : "Philipp Jean Blatantly"
},
"employer" : "Monsters Inc."
}
}
]
}
}
Now with two should clauses, you can see that the scoring has changed and
Philipp as a surname is no longer scored the highest. This may be the
desired behavior or not. What can we do, to increase the last name scoring
again? Or maybe decrease the two should clauses? Another solution is to
score contacts higher, but employees only if they are no contacts yet - as
this query gets much more complex, that’s an exercise for you.
Another solution would be to increase the must part of the query by
changing that part to
"must": [
{
"multi_match": {
"query": "Philipp",
"boost": 2,
"fields": [
"name.last",
"name.first"
]
}
}
]
This way the must part gets some more importance. As you can see, there are a lot of knobs to tune and try out with your own data.
There is one last thing.
Using the search-as-you-type datatype
One thing we did not cover yet, were partial matches. Searching for Philip
should also return all the Philipps in our data set.
Right now the following query just return Philip Jan Kredible, our only
single-p Philip.
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
},
{
"match": {
"employer": "Elastic"
}
}
],
"must": [
{
"multi_match": {
"query": "Philip",
"boost": 2,
"fields": [
"name.last",
"name.first"
]
}
}
]
}
}
}
Remember the mapping at the beginning? The names field contains a search-as-you-type datatype mapping which we now take advantage of. This field is optimized for search as you type use-cases out of the box by storing a field shingle and edge ngram token filters to ensure that queries are as fast possible - at the expense of needing somewhat more disk space.
Let’s switch the type of our multi match query
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
},
{
"match": {
"employer": "Elastic"
}
}
],
"must": [
{
"multi_match": {
"query": "Philip",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
}
}
]
}
}
}
This will return
{
"hits" : {
"hits" : [
{
"_score" : 4.6702895,
"_source" : {
"name" : {
"full" : "Philip Jan Kredible"
},
"employer" : "Elastic"
}
},
{
"_score" : 3.5283816,
"_source" : {
"name" : {
"full" : "Felix Philipp"
},
"employer" : "FancyFelix"
}
},
{
"_score" : 3.2081292,
"_source" : {
"name" : {
"full" : "Philipp Krenn"
},
"employer" : "Elastic"
}
},
{
"_score" : 2.2658012,
"_source" : {
"name" : {
"full" : "Philipp Laughable"
},
"employer" : "FancyWorks"
}
},
{
"_score" : 1.2658012,
"_source" : {
"name" : {
"full" : "Philipp Incredible-Smith"
},
"employer" : "21st Century Marketing"
}
},
{
"_score" : 0.93763053,
"_source" : {
"name" : {
"full" : "Philipp Jean Blatantly"
},
"employer" : "Monsters Inc."
}
}
]
}
}
The exact match first, the highest scored surname second and then my colleague Philipp Krenn. That looks nice!
Now we got the perfect search? Well… try searching for Philipp K - and
we do not get any result. That’s bad!
However, thanks to our ingest pipeline, we got the full name also indexed, let’s add that one to the fields being searched
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
},
{
"match": {
"employer": "Elastic"
}
}
],
"must": [
{
"multi_match": {
"query": "Philipp K",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
}
}
]
}
}
}
Now searching for Philip, Philipp and Philipp K returns the correct
results.
There is one more thing…
Don’t care about the term order
Not everyone knows the full name of a person he is searching for, so
sometimes you might be typing the last name only. Searching for Krenn works
as expected, however searching for Krenn P does not yield any result!
So, what can we do about this? Let’s make our query a bit bigger:
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
{
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "alexr",
"path": "contacts"
}
}
},
{
"match": {
"employer": "Elastic"
}
}
],
"must": [
{
"bool": {
"should": [
{
"multi_match": {
"query": "Krenn P",
"operator": "and",
"boost": 2,
"type": "bool_prefix",
"fields": [
"name.full.search-as-you-type",
"name.full.search-as-you-type._2gram",
"name.full.search-as-you-type._3gram"
]
}
},
{
"multi_match": {
"query": "Krenn P",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
}
}
]
}
}
]
}
}
}
This query behaves similar in all the previous cases, but also support searching for terms in an arbitrary order (like last name first) while still providing completion support.
Now as a last step, let’s make this a bit more maintainable on the search side.
Use a search template
The last step is to store this search so that the search client only has to provide the input query once.
Let’s store a mustache script
POST _scripts/social-query
{
"script": {
"lang": "mustache",
"source": {
"query": {
"bool": {
"should": [
{
"terms": {
"_id": {
"index": "social-network",
"id": "{{own_id}}",
"path": "contacts"
}
}
},
{
"match": {
"employer": "{{employer}}"
}
}
],
"must": [
{
"bool": {
"should": [
{
"multi_match": {
"query": "{{query_string}}",
"operator": "and",
"boost": 2,
"type": "bool_prefix",
"fields": [
"name.full.search-as-you-type",
"name.full.search-as-you-type._2gram",
"name.full.search-as-you-type._3gram"
]
}
},
{
"multi_match": {
"query": "{{query_string}}",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
}
}
]
}
}
]
}
}
}
}
}
Now queries are super short, all we need to provide is some query information:
GET social-network/_search/template
{
"id": "social-query",
"params": {
"query_string": "Philipp",
"own_id" : "alexr",
"employer" : "Elastic"
}
}
Another advantage of this approach is the fact, that you can now switch the underlying implementation of your query without changing your application. You could even do fancy things like a/b testing.
Final optimization: exclude yourself
Even though this sounds useful at the beginning, I bet everyone is searching for themselves at every social network every now and then. Switching off narcissism is hard :-)
You could add another must_not clause that filters for the {{own_id}} in
the bool query and make sure you are never seeing yourself when searching
for things, but I think it’s probably a nice feeling. Also, if you keep
including yourself, you may want to score yourself up really high using a
should clause.
I have purposely not included this sample here, feel free to try it out.
Next steps: Think about analyzers
Searching for names comes with its own challenges. Names that sound
similar, are not necessarily written similar, so that a fuzzy query is
essentially useless. A common german surname is Meier - however that can
also be written als Meyer, Maier, Mayer, Mayr, Meir - the edit
distance becomes easily greater than two. This is when phonetic analyzers
come into play. Elasticsearch and Lucene feature quite a bunch of those. For
Elasticsearch you need to install the analysis-phonetic
plugin
first.
This also applies for non-western languages, just ask border control agencies or country specific social networks.
Summary
I hope your biggest takeaway of this read is the fact, that an innocent looking query can easily become much bigger to ensure that the data is returned the way you would like it to be.
Compared to other queries, this query has a slight performance impact because of looking up the contacts of a user. I tested this with 500k users and 100 contacts per user and never exceeded 50ms on my notebook - which is absolutely not an environment you should do performance tests in, but usually helps to get a first grip, if this is OK to use, especially for something time sensitive like search as you type suggestions.
The data set was 2.5 GB and thus fit easily into the file system cache.
Ranking and scoring is tricky. You need to keep monitor those things when you data keeps changing and also have some simple mechanisms for alerting in case of changes and to check your scoring and ranking.
Other use-cases
Social networks are usually a bad demo example, because pretty much no one is running one (and those who do you usually use highly specialized software for their use-case as their users are in the billions).
The good news is, that this basic idea and assumption can be used for more use-cases. For example:
- Recently viewed products in an online shop can be ranked higher, because the user might want to visit those again
- Segment-of-One recommendations can be done with this. If you have ever taken a CRM course at university (at least when I was studying back then[tm]), you would get bombed with segment-of-one aka personalized marketing. With this you could basically have a nightly cronjob that creates hyper personalized recommendations every night and then present this to the user - or maybe recreate those when the user logs into your website, if your system is fast enough.
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, github or reach me via Email.
If there is anything to correct, drop me a note, and I am happy to do so!
Same applies for questions. If you have question, go ahead and ask!