 Alexander Reelsen
Alexander ReelsenImplementing a modern E-Commerce Search
TLDR; Before joining Elastic my previous job was running a product search engine at a small b2b market place. I learned quite a few things, and especially, what I would do differently nowadays, given that search engines have evolved a lot in the last decade.
This is the written form of a presentation I gave in Hamburg last year.
This post is not only about the pure search aspect of e-commerce sites, but takes a few and different things into account as well, which are slightly off-topic for search, but still highly relevant for e-commerce.
Introduction
Search ain’t easy. Having a good e-commerce search is even harder. A good search is
comprised of two elements: good indexed data and good search queries. Having
both is a rather rare exception. Of course, everybody claims they do have
both. Sometimes you are lucky and you have expert searchers. This is common
in e-discovery, where the person searching your data has deep domain
expertise and also the ability to craft proper queries - the same applies
for patent search engines in some cases. E-commerce is basically vice versa -
you tend to have structured and good data, but your searches are of lower
quality. Users do not exactly know what they search for, it is usually a
search for a brand/product name or adjectives like cheap. All of which can
also contain typos.
Another common search use-case to exclude in this post is the pure aggregating & analytics use-case. This is common for dashboards, but an e-commerce search usually searches for concrete products, even though aggregates are often used to drill down on data. The most common aggregation use-case to me is Observability, where you usually aggregate on logs, metrics, or traces (don’t three pillar me!).
I will not provide a solution using Elasticsearch for every example in this article, but I will give an example here and there to make a point.
Why is e-commerce search so hard?
This is a great question - and after all the years I still find it rather hard to answer, because there is not the one thing that makes it hard. It’s the sum of so many little things, that can go wrong, and sometimes just a small thing is enough to have the website visitor decide in a blink that he will not purchase from your e-commerce shop. On top, there are so many non-search related factors that can also be driving users off your website.
My latest personal experience was trying to order a book from Hugendubel instead of Amazon during the lock-down. Hugendubel, a German book shop which also has plenty of shops, did not allow me to order without creating a user account, whereas Thalia/buch.de allowed me to do that - so I ordered there. This had nothing to do with the search experience, but I still wonder what the abandoned shopping cart gets attributed to - in case you even have such a tooling to not only detect but also report on it.
Another lock-down example: I was trying to order at Ravensburger for a certain book that my daughter wanted to have. The online store told me, that this book can only be bought in physical stores - during a lock-down… WTF. Also, I got errors, whenever I wanted to pay with Amazon Pay without knowing if my credit card got charged. After writing an email, I got feedback two weeks later, that my requests had been forwarded to the department working on payments. Another reason to never go back to this shop, which is completely outside of the search experience.
But let’s not focus on my cursing at online shops (I could go on for hours), but rather on getting search right.
Product data
Let’s start with the utmost priority aka product data. No data, no search, not even a bad one. Running a marketplace means, that merchants are providing the data. Some merchants provide the data in a different format every day. And you begin to curse. A lot.
Clean data
What is clean data after all? The process to get there is also referred to as data cleansing. For customer data, this usually means a lot of validation
- Valid URLs
- Data type constraints (stock must be an integer)
- Range constraints (stock must be a positive integer)
- Value matching via expressions or custom program code
Depending on the profession of the data supplier you may still be in the darkest middle ages and companies are running their data management via excel - including manual stock updates in an excel sheet. Sometimes you are lucky and there is a system allowing you to export such data.
This brings us to another interesting topic. What is the format that you accept? JSON, XML, EDIFACT, or just a good old CSV? Do you have an API or a form upload? What do you do with data that has not been updated for years?
Cleaning data is a tricky thing, you need to have a foolproof process. What happens if your data cleansing process changes the price of a merchant product to 1/10th of the original price and someone triggers a thousand orders? Liability is a topic here as well.
UOM
UOM stands for Unit of measurement. It’s not only about the metric system (and, uhm, ’the others’), but also about the conversion to different units. Values need to be normalized across all of your data. This means if one product has a measurement of inches (like smartphone display diameter) and one has a measurement of centimeters you need to have a conversion mechanism to be able to have proper range queries. You also need to make sure you use the correct measurement for product types. Think of displays, alloy rims, drink sizes, food packaging, etc.
This can also quickly turn into a UI issue because no one knows the diameter of their smartphone screen in centimeters.
For the java developers among you, JSR 363 has been open for quite some time and even superseded by JSR 385, so maybe we will see a UOM helping API at some point in the JDK. There is also a reference implementation on GitHub.
Deduplication
If you run a marketplace with merchants, chances are high, those merchants are selling the same goods unless they are the producers of those, and even then you might have a bunch of resellers in your platform as well.
How do you handle this? This has been solved for books by using the ISBN, and if you are the biggest marketplace in the world, you have the power to create an ASIN - you won’t have that power being a small marketplace.
There are a few error-prone alternatives. You could use the provided photos and check for similarity. Sometimes it is already enough to check for the same hash value of that photo, before going full deep learning and waste a ton of engineering time on that.
You could also compare the product descriptions, as those are often just copied from the producer, name, release date, or certain units of measure.
None of those is hundred percent safe though.
Even if you have a good mechanism for detecting duplicates, the next question is, where does this apply? Query time? Index time?
Inventory stock data
Having near real-time information, if a product is available, is critically important nowadays. If a product cannot be delivered within 2-3 days, most folks will not issue an order, as buying is often impulse-driven.
So, either you can query other systems (which increases complexity a lot) or your merchants provide inventory data. This inventory updates usually happen more often than price or content data updates, so make sure you have a lightweight way of updating.
You also may have to deal with the fact of aged stock information, so that an item was bought on your platform, but is not available anymore at the merchant, resulting in order cancellations and changes.
Data modeling
Time to model your data. That’s a quickie, right? You got a few attributes, put a text/keyword flag on them, and then you’re good to go! Well…
Variants
The elephant in the room are product variants to me (after you solved the above duplication issue). First, you need to model the different attributes and their combination. Merchants will find interesting ways to squeeze many variants into a single product despite indeed being separate products and vice versa - it’s hard to come up with rules, what is a variant and what is not. But let’s stick with something simple, yet omnipresent: clothes.
- Color (red, green, yellow, black, orange, white, blue)
- Size (XXS, XS, S, M, L, XL, XXL, XXXL)
Only two dimensions, that’s easy. But you already got 56 variants. Having four dimensions will give you a variant explosion, and it may be already hard to show in a UI, which variants exist and which don’t. Amazon sidestepped this quest by telling you after you click, and that’s a valid solution as well.
So, how to model this? There are a few solutions associated with very different costs.
First, every variant can become its own document. Even though easy to implement at first, depending on the size of your website, you may end up with a lot of duplicate documents and content. Also, how do you filter searches, if no attributes are specified? Let’s model this quickly by bulk indexing a few documents.
So, this t-shirt exists in different colors and sizes. Is this a new product or just a variant? Also, maybe you need a dedicated title and description for any variant?
DELETE products
PUT products/_bulk?refresh
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "M", "color" : "gray" }
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "S", "color" : "gray" }
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "L", "color" : "gray" }
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "M", "color" : "green" }
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "S", "color" : "green" }
{ "index" : {} }
{ "title" : "Elastic Robot T-Shirt", "size": "L", "color" : "green" }
Running a search is like:
GET products/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "shirt"
}
},
"filter": [
{
"term": {
"color.keyword": "green"
}
},
{
"term": {
"size.keyword": "M"
}
}
]
}
}
}
This returns only one shirt, but the moment we drop one of the filters, we will end up with more hits of basically the same product.
We could solve this by using field collapsing, but this means again doing something at query time.
We could try out a nested datatype and have all variants in an array like this:
PUT products
{
"mappings": {
"properties": {
"variants" : {
"type": "nested"
}
}
}
}
POST products/_doc
{
"title" : "Elastic Robot T-Shirt",
"variants" : [
{ "size": "S", "color": "gray"},
{ "size": "M", "color": "gray"},
{ "size": "L", "color": "gray"},
{ "size": "S", "color": "green"},
{ "size": "M", "color": "green"},
{ "size": "L", "color": "green"}
]
}
This way we could search for products with certain attributes
GET products/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "shirt"
}
},
"filter": [
{
"nested": {
"path": "variants",
"query": {
"term": {
"variants.color.keyword": "green"
}
}
}
},
{
"nested": {
"path": "variants",
"query": {
"term": {
"variants.size.keyword": "M"
}
}
}
}
]
}
}
}
We could also easily search without any filter and only get back a single
document. One thing to pay attention to is to prevent a mapping explosion
by using arbitrary attributes. If you control the attribute names, try to
keep their number down and unify them (size can be used for many different kinds
of products).
Using inner_hits it is also easy to figure out, which nested document matched.
So, what’s the catch? Easy, it’s about product updates! If you also store stock updates in this index, then an inventory update of a single variant will cause a complete reindex of the document. Depending on the number of stock updates, this might be quite the load. I am still leaning towards this solution, as I suppose that stock updates are manageable in most cases. Please do keep in mind, that you are not the amazon storefront, even though many CEOs of e-commerce companies tend to believe that :-)
Finally, let’s give the join datatype a try, allowing us to join two documents (product and variant) together at query time.
DELETE products
PUT products
{
"mappings": {
"properties": {
"join_field": {
"type": "join",
"relations": {
"parent_product": "variant"
}
}
}
}
}
PUT products/_bulk?refresh
{ "index" : { "_id": "robot-shirt" } }
{ "title" : "Elastic Robot T-Shirt", "join_field" : { "name" : "parent_product" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "M", "color" : "gray", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "S", "color" : "gray", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "L", "color" : "gray", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "M", "color" : "green", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "S", "color" : "green", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
{ "index" : { "routing": "robot-shirt" } }
{ "size": "L", "color" : "green", "join_field" : { "name" : "variant", "parent" : "robot-shirt" } }
The query looks like this:
GET products/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "shirt"
}
},
"filter": [
{
"has_child": {
"inner_hits": {},
"type": "variant",
"query": {
"bool": {
"filter": [
{
"term": {
"color.keyword": "green"
}
},
{
"term": {
"size.keyword": "M"
}
}
]
}
}
}
}
]
}
}
}
This will also return the child product, that matches. Note, that a query
using the join datatype will have a performance impact compared to the
nested datatype, so I would always only consider this when high update
loads impact your cluster. Search speed is one of the most important metrics
to me.
The above example uses the already mentioned inner_hits functionality so
that you not only see the parent variant, but also the child that matched.
Note that this can be more than one hit, so you should be careful returning
those to the client (I’d always try to return only one variant). It might be
important to return parts of your variant data for your client. Imagine you
are searching for a green shirt in XL, then returning a green image is
more important than returning an image of an XL sized shirt.
What data belongs to the variant and what data belongs to the parent product is hard to say. Some merchants change the description of every single variant, which I would try to prevent. The attributes should be the only differentiator, this is already enough complexity.
A couple of questions to think about before moving on to the next topic:
- How do you handle missing variants in your UI?
- How do you display variants that are not available?
- Can you handle a product with 2000 variants (backend and UI)? (yes, this stems from personal experience)
- How do you display and model products that don’t have any variants?
- Ensure variants can have different prices (think phones with different memory) - this is probably just an attribute, but suddenly range queries about the price become interesting.
- Do variant attributes like size and color need to be searchable and need to be filtered on?
Multiple languages
If you have product names and descriptions in multiple languages, you should try to have dedicated fields for each language that you want to support, so that you can use custom analyzers. This leaves you with two issues. First, if you do not know the language, you need to detect it. In the best case, this information is delivered with the product data. There is a language identification feature built into the inference processor, so you can extract the language information at index time.
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "lang_ident_model_1",
"inference_config": { "classification": {}},
"field_map": {}
}
}
]
},
"docs": [
{ "_source": { "text": "Das ist ein deutscher Text" } }
]
}
Now you could store the language or the content in a specific field like
description.de. If you can figure out the language of the
user, you can only search German fields with German analyzers, ending up
with a better search experience.
Decompounding
This is for ze germans. The search I helped to implement back then was
German only - but that does not make it any easier, especially if many
product names are already a compound word. Famous: The
Eiersollbruchenstellenverursacher. If you are curious, you can search for
it on Amazon, it’s not a fake product, but that is an outlier. There are much
simpler use cases though, for example, Blumentopf (flower pot) and
Kochtopf (cooking pot). None of these are searchable when just typing
topf as that is just a partial term. English has solved this much better
by pot being an own term and also being put into the inverted index.
Luckily Lucene has a decompounder token filter. Let’s take a look at an example:
# returns each term
GET _analyze
{
"tokenizer": "standard",
"text": [ "Blumentopf", "Kochtopf" ]
}
GET _analyze?filter_path=tokens.token
{
"tokenizer": "standard",
"filter": [
{
"type": "dictionary_decompounder",
"word_list": ["topf"]
}
],
"text": [ "Blumentopf", "Kochtopf" ]
}
This returns topf as a separate token
{
"tokens" : [
{
"token" : "Blumentopf"
},
{
"token" : "topf"
},
{
"token" : "Kochtopf"
},
{
"token" : "topf"
}
]
}
But beware! Let’s run the same for another term
GET _analyze?filter_path=tokens.token
{
"tokenizer": "standard",
"filter": [
{
"type": "dictionary_decompounder",
"word_list": ["topf"]
}
],
"text": [ "Stopfwatte" ]
}
This returns:
{
"tokens" : [
{
"token" : "Stopfwatte"
},
{
"token" : "topf"
}
]
}
Try to explain to your user, that Stopfwatte is a valid hit when
searching for topf - I bet you will have a hard time. You could play
around with more should clauses from a boolean query to influence scoring, but
this very likely means to solve the problem at the wrong end of things, at
query time, whereas this should probably be solved at index time.
This is where the hyphenation decompounder comes into play. This requires an XML file from the offo project, where the link is mentioned in the link above.
GET _analyze
{
"tokenizer": "standard",
"filter": [
{
"type": "hyphenation_decompounder",
"hyphenation_patterns_path": "analysis/de_DR.xml",
"word_list": ["topf"]
}
],
"text": [ "Blumentopf", "Kochtopf", "Stopfwatte" ]
}
returning
{
"tokens" : [
{
"token" : "Blumentopf"
},
{
"token" : "topf"
},
{
"token" : "Kochtopf"
},
{
"token" : "topf"
},
{
"token" : "Stopfwatte"
}
]
}
As you can see, Stopfwatte did not create another topf term, because now a
dictionary is used to get a better grip on splitting terms.
Lastly, the moment you decide to go with decompounding terms you need to be super aware, that you need to have a consistently updated word list, which also needs to be used in your test suites as well!
You may also want to create or modify the hyphenation patterns depending on your domain!
We’ve taken a look on the ingestion side of things, but we also need to take great care on the search side.
Prices
The naive implementation of pricing is that every product has one price - well maybe two, because of a strike price. Well, maybe three, because of bulk deductions. Well, maybe four, because of different sales taxes. Well maybe fifty-two, because of different sales taxes per state. At least those are static prices.
The fun begins, if certain customers get a permanent ten percent reduction, for all products. Do you start to index prices for every customer group in your variants?
Do you factor in the deduction when executing the search? How about displaying prices, do you want to execute a pricing service for each product being returned by a search?
These are tough questions and depend on the use-case, just be sure, that there won’t be a single price at your products or you will be catching this somewhere else in your application.
Search use-cases
Let’s take a closer look at where search is happening on an e-commerce website.
Search bar
In a perfect world, every shop would look like Google, a single search bar, which you type your query into and you get magically all the interesting products you always wanted to buy. In reality, the search experience is nowhere like that, especially in e-commerce.
Let’s take a quick look at a few big e-commerce players in Germany. Somehow all pages are somewhat similar. Note: I do not know for sure which search engine each of those is using, but I am fairly certain that there is a bit of Lucene and/or Elasticsearch in the mix.

Let’s start with Zalando. Lots of elements, that are not centered
around search, but very likely gathered by a lot of user behavior research,
like the Help & Contact Link at the top.
The search bar is hard to find on the upper right, no contrast or framed box make it hard to spot. Maybe clothes are a business where most people browse and do not search.

The next clothing only store. Navigation is very similar to Zalando, a top-left pick to select women/men/kids categories, repeated in the center of the homepage. Zalando and AboutYou each have a single gigantic image in the center, which seems to be the absolute go-to option nowadays, as everyone does it. A few even have a carousel for that. Search is even less important here, as the search bar only appears if you click on the magnifying glass - no one seems folks to expect a search as their first action here either.
Next up the old school juggernaut, and the biggest competitor to Amazon in Germany. AboutYou was also founded by Otto, and still seems to own more than fifty percent).
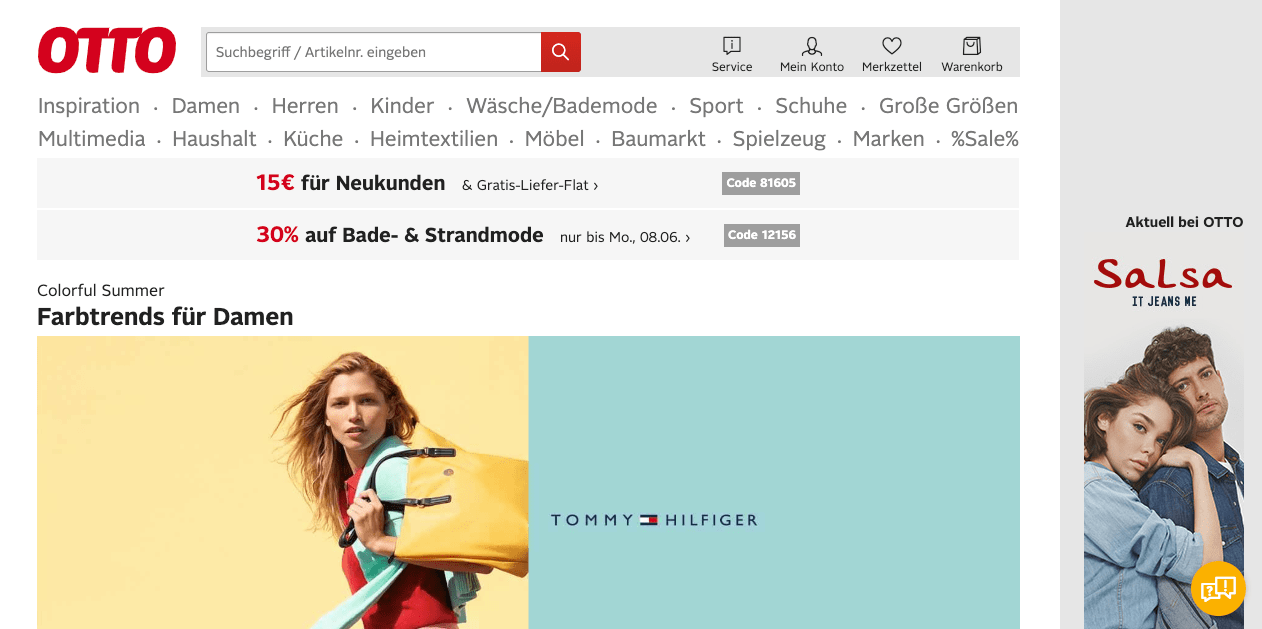
Otto looks a bit less modern just by using different colors. Also, the first company that puts its own logo on the top-left, and finally, a search bar right next to it!
The content of the search box immediately lists the reason. I suppose there are still quite a few persons putting the article number in there, so they explicitly wrote in the box that this is possible.
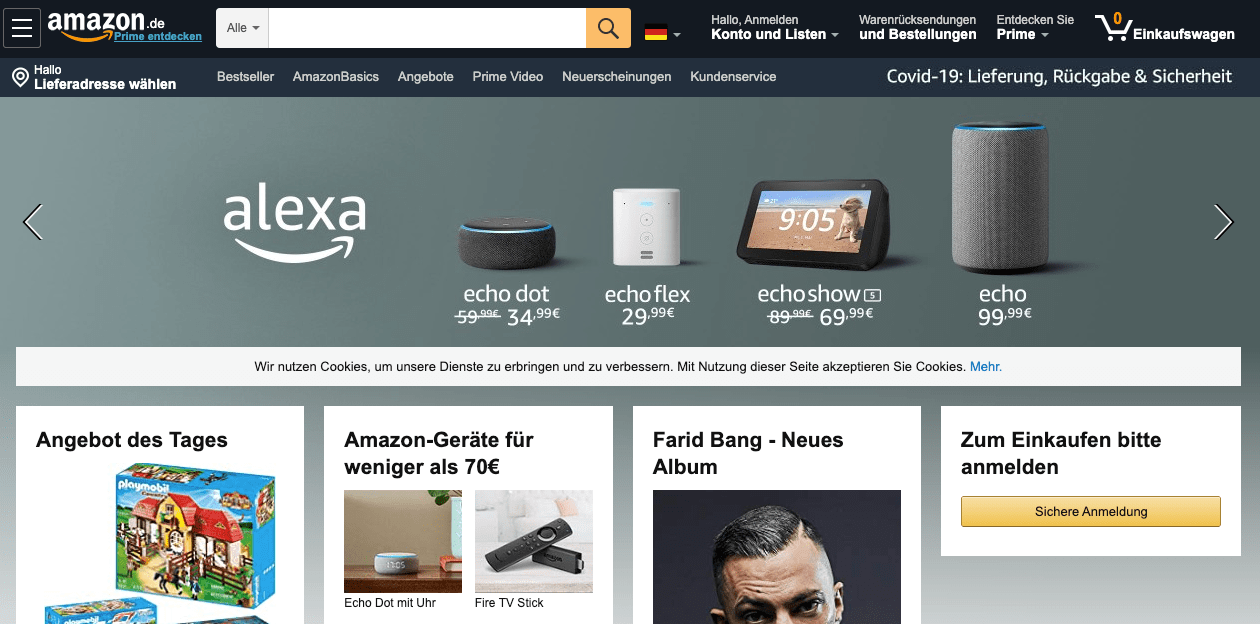
Amazon looks very similar to Otto by having their logo and a search box right at the top. I have never used Amazon anything different than running a search the moment I opened the website, so to me, this is a smart idea. The search bar is also visually very easy to spot due to its bright background.
So, the clothing only stores a look alikes from each other and the general purpose stores are :-)
Let’s take a look at some search bar features, first, not everything is a search…
Search bar landing page redirection
Almost every e-commerce search solution needs a redirect ability, so if a
certain search term is typed in, a redirect is needed. Let’s take
impressum as an example, the search for the imprint - which is always
listed at least at the bottom of the page, but many people type into a search
bar whatever they search for on a website. Just what you do at Google,
right?.
If you run this search on Zalando, it will return clothes matching
impressum. However, Otto will forward you to their imprint site.
Such a forwarding feature implies the need of a middle-ware, that can basically detect searches for certain pages and redirects the application.
Also, this requires you to index a new breed of document type into your existing index, so that you mix and match products and landing pages or that you query a second index, that contains only redirects. If you want to accommodate for that in your index, maybe consider indexing pages instead of products in general and think more in terms of a CMS, that incidentally features a lot of products.
This is an absolutely crucial functionality, not only for redirects but also
for regular search terms. Remember the Blumentopf vs. Kochtopf
discussion above? What happens if a user is only typing topf? Do you want
to return only one of a kind or mix and match the results? If you have
merely cooks ordering from your website, you should create a dedicated
topf landing page feature your best selling cooking pots.
There is a potential danger with this approach, and that is to create landing pages for all search important search to only return the best[tm] products.
That is the moment you can stop using a search engine, as you hired enough category managers. This is also the moment you gave up on the long tail.
Search-as-you-type
This is one of the most powerful functionalities of a search, and I think it is often undervalued.
The idea of search as you type is to suggest partially typed terms to the user who is currently typing - before any search results are returned. This means responses have to be as fast as people typing, which should not be a challenge for modern search engines.
The cleverness of this feature is the fact, that you can guide the user before results are displayed. This means you can:
- display a suggestion with a typo being fixed, before a real search query is sent, potentially improving the results
- already start ranking these suggestions, so they are scored in your favor
For example, searching for iph should always display the iPhone, which is
currently sold best and not display any iPhone leather cases as the first
hit.
To implement a powerful search as you type functionality you need to have a proper feedback loop in place, which constantly changes to your advantage. For example, only taking the most recent orders into account might be a good idea, to not have suggestions that are being too old.
Another advantage of search-as-you-type functionality is the possibility to offload your search engine for regular searches (which may be directed against a bigger index), and just use a smaller data set for your suggestions.
Elasticsearch used to have the completion suggester for this use-case, despite some limitations like only being a prefix suggester. With the new search-as-you-type datatype, that has been added after Lucene 8.0 got a decent speed bump, you can execute a regular search.
If you are interested in this kind of suggestions, check out my blog post about Implementing a Linkedin like search as you type with Elasticsearch.
Let’s take another look at the four websites. I searched for a dress (the
german word is Kleid) in all four of them. This is of course not a fair
comparison because two of those four search engines are specialized in
clothing, allowing them to come up with potentially more aligned
suggestions.
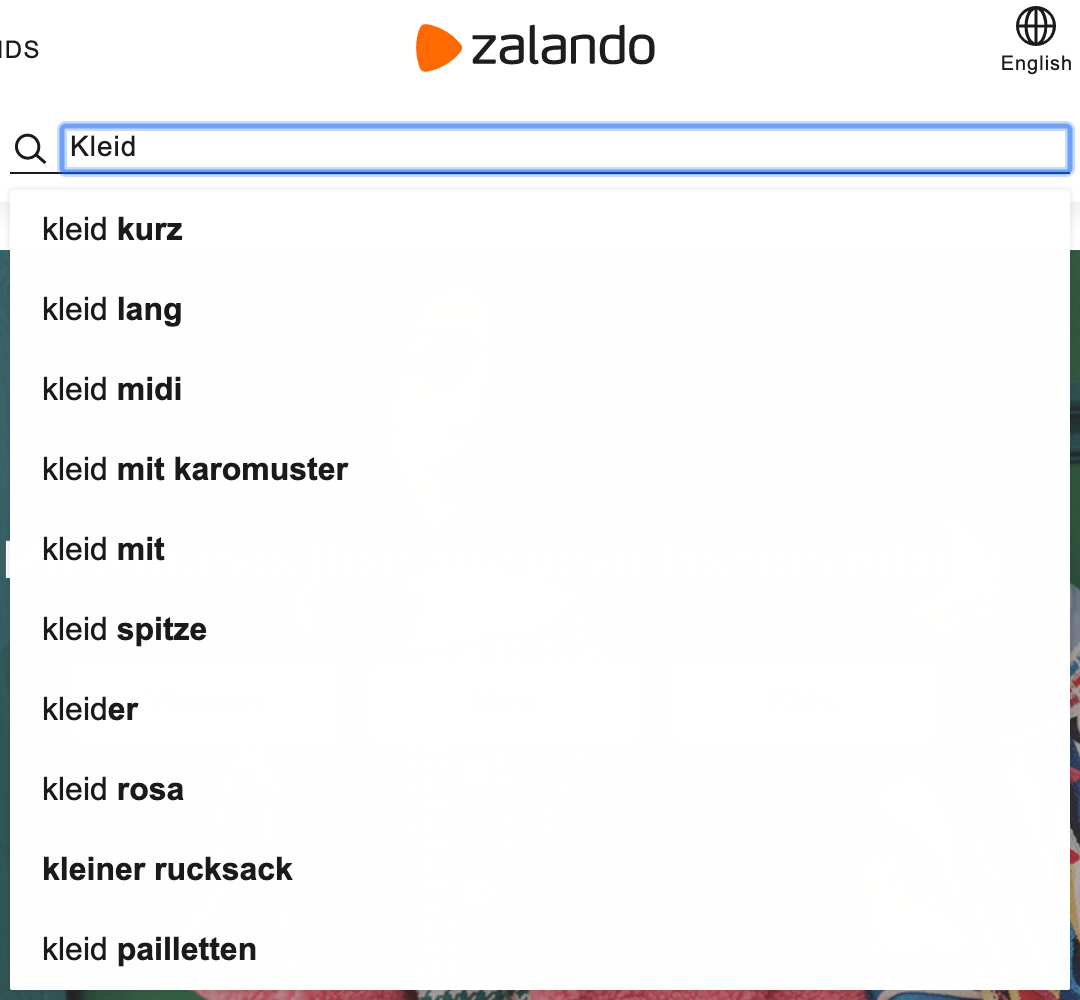
Zalando is mainly showing prefix suggestions, except for
kleiner rucksack, which seems to be included, despite not containing a d
somewhere, so typos seem to be corrected.

AboutYou is taking a different route. The suggestions are split between different kinds of suggestions. The product suggestions are basically useless as all have the same name without a preview, but the brands and categories do make a lot more sense than individual products if you plan to browse the catalog.
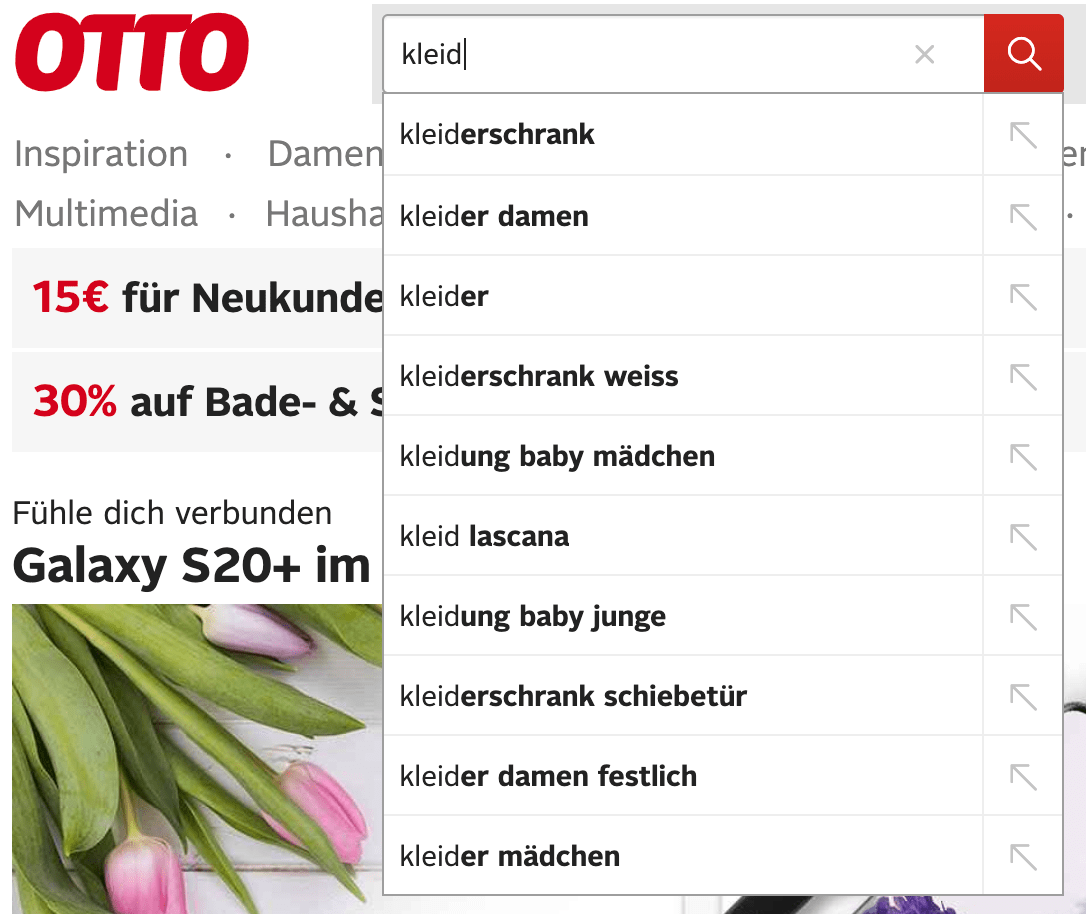
Otto shows non-clothing as well. Prefix suggestions seem to score higher
than exact matches here. The order is rather confusing. Maybe everything
beginning with kleid and kleiderschrank could be grouped together to
make the suggestions easier to navigate.

The best hit in Amazon seems to dictate the offered category in the second line, and everything seems to be prefix-based as well.
Note: If you want to find out if a product search engine is suggesting only from the start of a field, just turn two terms around and retry. This is especially something that social networks should never do, as many people often remember the surname of a person easier than the first name.
Smart Searches
Next up, go for a smarter search, as incoming queries will not be smart. Take the following search query, which is a good user query:
nike running hoodie xl
As a human, this is easy to parse and the query should be:
brand:nike running hoodie size:xl
two of those four terms should be applied as a filter and only running hoodie should be an actual search in the product title or product
description.
So, what’s stopping you from doing this? All you need is a small middle-ware enriching your query. You already have a middle-ware, … right?
This is just a form of query rewriting. The main question is, how
do you rewrite. Will you run the query against an index filled with brands
and sizes and see if anything matches, and then use that for your real
query. For something like the size attribute, this might be overkill. For
brands, this again might make a lot of sense, as you could use the fuzzy or
phonetic capabilities of your search engine to fix mistyped brands. Brands
like Louis Vuitton, Balenciaga, Calzedonia, or Wellensteyn are easy to
type wrong.
That said, maybe starting small and catching a ton of brands when typed correctly as well as two dozen different colors along with sizes will already improve your search manifold, so do not go crazy but start small.
There is another common use-case for somewhat smart search. Searching by a certain identifier. On Amazon, you can always search for the ASIN or the ISBN in many different formats (with dashes or without), so detecting this kind of numbers and rewriting your search might also make a lot of sense.
Query enrichment
Even though your query looks like north face hoodie on the outside, it is
usually all but that on the inside. When you are a platform with a ton of
merchants, you may want to influence your search results based on the
provision you are receiving per merchant. When you are a newspaper, you want
to score more recent documents higher. When you are a hotel website, you
want to score hotels near the airport or the city center higher. So, numbers
or geo points should be additional signals when scoring. This is not new,
but easier and faster with Elasticsearch 7.x. Let’s take a look at the
distance_feature
query
and the rank feature
query/datatype
Imagine we have an auction-based site and would like to boost documents that are ending soon.
PUT auctions/_bulk
{ "index" : {} }
{ "end_date" : "2099-06-30T11:11:11", "name" : "North Face Hoodie" }
{ "index" : {} }
{ "end_date" : "2099-06-29T11:11:11", "name" : "North Face Vest" }
{ "index" : {} }
{ "end_date" : "2099-06-28T11:11:11", "name" : "North Face Shirt" }
{ "index" : {} }
{ "end_date" : "2099-06-30T11:11:11", "name" : "Nike Hoodie" }
{ "index" : {} }
{ "end_date" : "2099-06-30T11:11:11", "name" : "Puma Hoodie" }
# regular search, north face products scored highest
GET auctions/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "north face hoodie",
"minimum_should_match": "66%"
}
}
}
]
}
}
}
# now take end date into account
# let's assume the current date is 2099-06-28T08:00:00
# use origin for current date
GET auctions/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "north face hoodie",
"minimum_should_match": "66%",
"boost": 0.5
}
}
}
],
"should": {
"distance_feature": {
"field": "end_date",
"pivot": "7d",
"origin": "2099-06-28T08:00:00",
"boost": 2
}
}
}
}
}
Comparing the output of those queries (keep the size of the data set in mind
making this completely artificial) shows that the second query response
scores the north face clothing higher which is about to end. Even with such
a small data set, you will find yourself tweaking the boosting of the match
query as well as the distance_feature query. You can imagine, that in
production this requires a good and decent sized test corpus to
continuously validate those results.
Imagine you would like to score auctions up, that do not have any bids.
That’s an easy one, right? You could add another should clause the above
query searching for { "total_bids: 0 } or something like that. How about
fostering some competition by scoring those higher, that have fewer bids in
general?
DELETE auctions
PUT auctions
{
"mappings": {
"properties": {
"total_bids": {
"type": "rank_feature",
"positive_score_impact": false
}
}
}
}
# minimal value for rank_feature fields is 1
PUT auctions/_bulk
{ "index" : {} }
{ "name" : "North Face Hoodie", "total_bids":100 }
{ "index" : {} }
{ "name" : "North Face Vest", "total_bids":1 }
{ "index" : {} }
{ "name" : "North Face Shirt", "total_bids":15 }
{ "index" : {} }
{ "name" : "Nike Hoodie", "total_bids":1 }
{ "index" : {} }
{ "name" : "Puma Hoodie", "total_bids":20 }
GET auctions/_search?filter_path=**._score,**.name,**.total_bids
{
"query": {
"bool": {
"must": [
{
"match": {
"name": {
"query": "north face hoodie",
"minimum_should_match": "66%",
"boost": 1
}
}
}
],
"should": {
"rank_feature": {
"field": "total_bids"
}
}
}
}
}
This will show a response similar to this one
{
"hits" : {
"hits" : [
{
"_score" : 1.9036325,
"_source" : {
"name" : "North Face Vest",
"total_bids" : 1
}
},
{
"_score" : 1.595582,
"_source" : {
"name" : "North Face Hoodie",
"total_bids" : 100
}
},
{
"_score" : 1.4846532,
"_source" : {
"name" : "Nike Hoodie",
"total_bids" : 1
}
},
{
"_score" : 1.3632694,
"_source" : {
"name" : "North Face Shirt",
"total_bids" : 15
}
},
{
"_score" : 0.8818006,
"_source" : {
"name" : "Puma Hoodie",
"total_bids" : 20
}
}
]
}
}
As you can see, north face products are still scored high, but the north
face vest with only a single bid is the first product. The same applies to the
nike hoodie. I’d be very careful though with scoring the vest higher when
there is an exact hit like a hoodie.
Faceted Navigation
Time for some old fashioned topic, that everyone knows about. Faceted navigation. This is the second stage of navigation. Whenever I enter an e-commerce website, the first thing I do is typing the product I search for in the search bar. If I am lucky, I get a few suggestions that immediately take me to the product page.
If I am unlucky or my search was too generic I am taken to search results
page, which has the same layout everywhere. Let’s take a look at our four
examples and our search for a dress (Kleid in German).
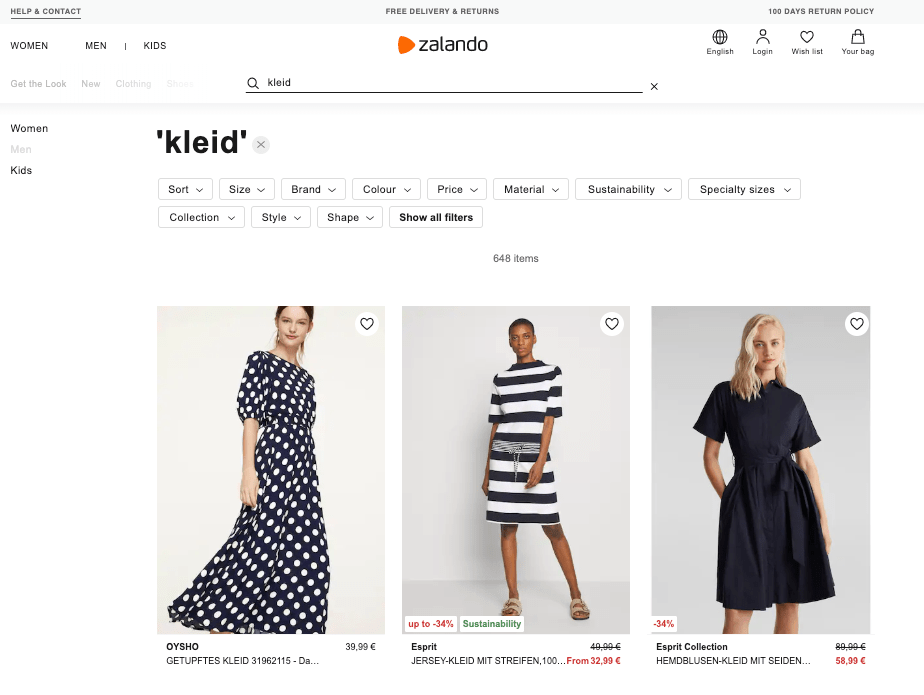
Zalando has the faceted navigation, or feature selection right at the top above everything else. I like that. Every selection is shown differently, which makes sense. A price is usually a slider, a color selection displays colors, most others are simple string-based selections like brand and material.
I suppose the placement at the top allows for the same experience on a mobile device than on any other device.
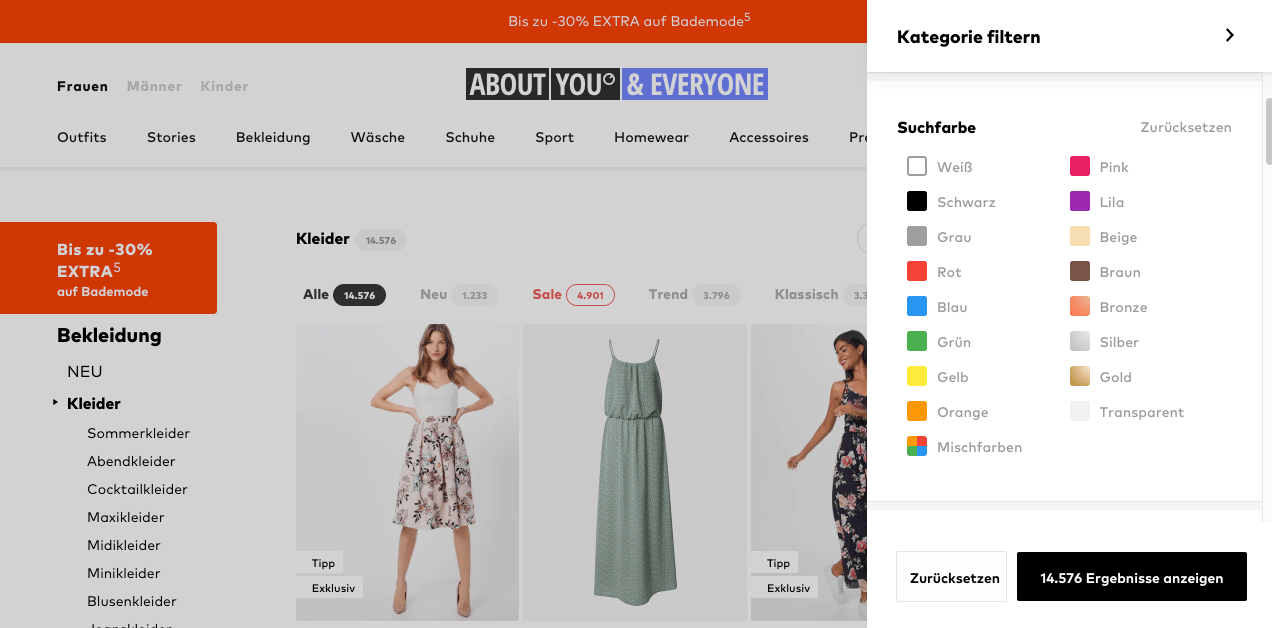
AboutYou is hiding all the filters behind a button and only slides them in after a click. The left side - where I would have expected the filters - only contains categories. I found this slightly confusing, but I am not the intended main user for this, so maybe this is how users are using the platform.
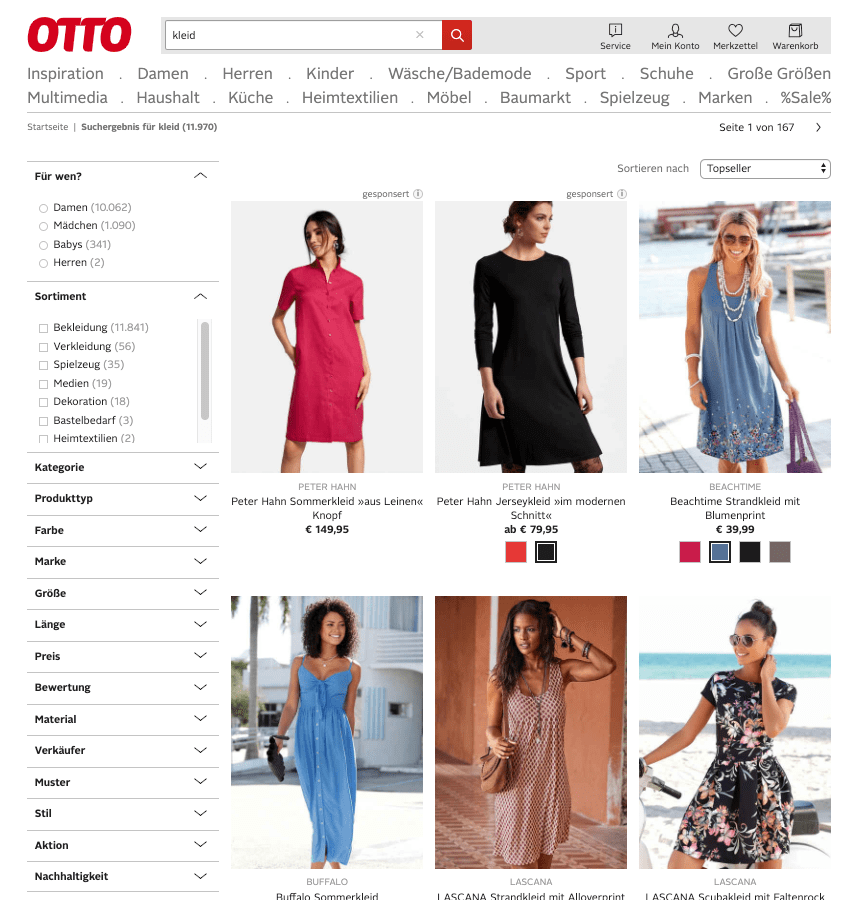
I had to take a bigger screenshot of Otto because the sheer number of filters is absolutely overwhelming to me. 16 different filter categories to pick from. Wow. On the other hand, Zalando also had 13, just hiding it much better, requiring much less space on the screen.
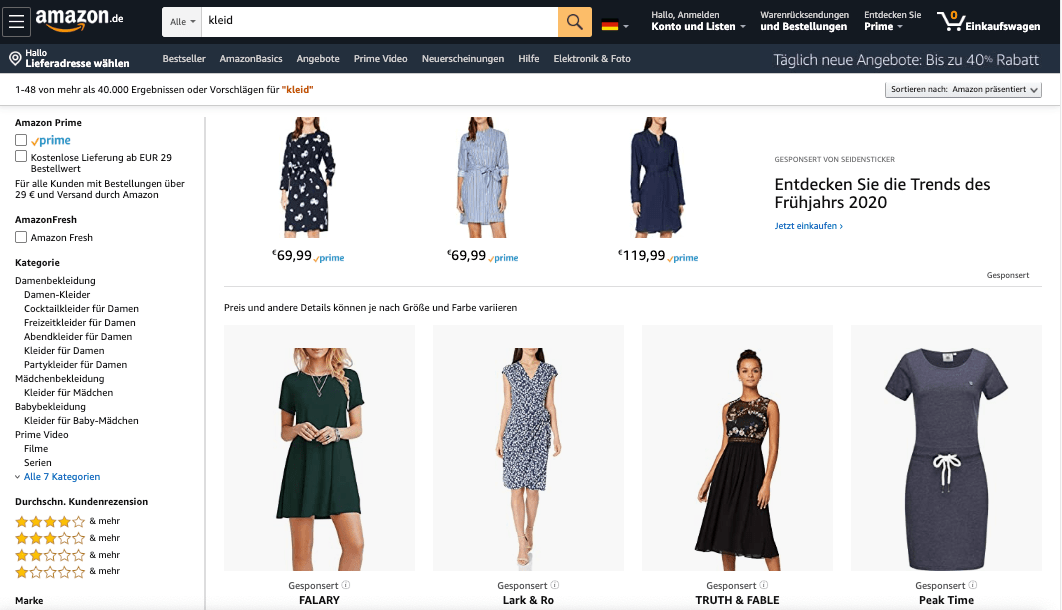
Amazon is doing an interesting take regarding the order of filters. The first one is always about Amazon prime, to make sure this burns into their users minds, that there is prime and you should use it. Also quite high up is always the rating filter. As Amazon is one of the few shops where ratings can have an impact due to their sheer numbers, this makes a lot of sense.
In general, you should change the filters based on the products you are displaying and try to reduce the number of filters as much as possible.
If the user is searches for TVs and you figured out the user is doing that, ensure that the order of filters is good. I suppose most people are filtering by diameter, price, and manufacturer. You can remove your category selection filter, once a user is in a certain category.
There is one more interesting thing to note (because it is hard to implement). Three out of those four do not display document counts at each element of a category, they just show the existence of a category. So, why is this hard? Let’s take a look at how to implement this. To fully understand, you can check out a sample micronaut app I wrote for demonstration purposes.
This is its navigation:

Now the trick is, whenever you select a facet value like color: red, this
needs to be applied for the counts in brand and material as well,
however, this may not be applied to count in the color facet. If you
would do that, you would not see all the colors that you may want to
specify as well. If you have a filter each for color, brand, and
material your query looks like this
- Query limited by price and stock
- Documents on the right must be filtered for brand + color + material
- Color facet must be filtered for brand + material
- Brand facet must be filtered for color + material
- Material facet must be filtered for brand + color
The more facets you add, the more complex your query will be.
Sponsored searches
If you take a look at the Amazon result page above, it’s not only about the faceted navigation.
The first results on the right are not search results based on relevancy. Those are sponsored results - which makes sense for Amazon, as they get some additional money in case of clicks and buys.
At first, this does not make sense for the other three platforms. However you will always have a reason to not score certain products, but simply shove them to the top.
Zalando at some point had started their own clothing brand (not sure they still do), but pushing those up might make a lot of sense to ensure products get sold or to free warehouse capacity.
You could solve this with two different searches, but this might be complex in case of product sorting and ordering or counting aggregations. Elasticsearch has a special pinned query allowing you to score some document ids up, it works like this:
PUT products/_bulk?refresh
{ "index" : { "_id" : "1"} }
{ "title" : "Nike Hoodie", "brand" : "Nike" }
{ "index" : { "_id" : "2"} }
{ "title" : "Nike T-Shirt", "brand" : "Nike" }
{ "index" : { "_id" : "3"} }
{ "title" : "Nike Shorts", "brand" : "Nike" }
{ "index" : { "_id" : "4"} }
{ "title" : "Adidas Shorts", "brand" : "Adidas" }
GET products/_search
{
"query": {
"pinned": {
"ids": [
"4"
],
"organic": {
"match": {
"title": "nike"
}
}
}
},
"aggs": {
"by_brand": {
"terms": {
"field": "brand.keyword"
}
}
}
}
The response will contain the Adidas shorts as the first hit. You can also check out the aggregation part of the response which contains the pinned document as well.
Product Detail Page
The product detail page is one of the steps of making a sale to put an item in the shopping cart. This means it needs to be easy to put it in the shopping cart.
Every product detail page on our four sample sites looks similar:
- The most space is taken on the upper left to center by a big product image and the ability to page through a list of images
- The right side allows selection on the variants, for a dress that would likely be size and color
- Amazon is very prominent with the product rating. Others range from a very small view to not showing a rating at all
- A more detailed product description is usually below the pictures
- Cross/Upselling opportunities: Some shops show products from the same brand. Others show similar products or products which complement the current one. Others show the products the user viewed before
- A big button to add the item to the shopping cart
- Information about delivery date and return policies. Omitting delivery dates won’t make you would survive long in e-commerce nowadays. Amazon has set quite the benchmark here.
- A few shops have an option to not put a product into the shopping cart directly, but keep in another list to look at later
To me, a Zalando product detail page looks much cleaner than all the others, but still, the amount of information that needs to be displayed is rather vast.
One last thing: What happens if a product is not available? Very likely your product page will not issue a HTTP 404 not found error but still, show the product. Do you provide any actionable option when an item cannot be bought? At my former employer, we replaced the ‘add to shopping cart’ button with a button to notify the user as soon as the product is back in stock again. This also meant we got a first glimpse of the user and his/her email address (everything pre GDPR :-)
A product detail page usually includes a lot of data retrievals apart from the product itself, like price calculations, product recommendations, alternative products, etc.
Product recommendations
This is part of many product detail pages. At one of my former employers we used a third-party service, that was incredibly slow to poll, returned bad recommendations, which then were displayed at the bottom of the page.
Nowadays I would not try to use a third-party service for this, but just use the existing data, that your e-commerce system has already: Inspecting the existing orders, it is possible to figure out, which products have been bought together.
Let’s have a super small example:
PUT orders/_bulk?refresh
{ "index" : { "_id" : "order_1"} }
{ "product_ids" : [ "1", "2", "3" ] }
{ "index" : { "_id" : "order_2"} }
{ "product_ids" : [ "1", "3" ] }
{ "index" : { "_id" : "order_3"} }
{ "product_ids" : [ "1", "2" ] }
{ "index" : { "_id" : "order_4"} }
{ "product_ids" : [ "4" ] }
GET orders/_search
{
"size": 0,
"query": {
"match": {
"product_ids.keyword": "1"
}
},
"aggs": {
"by_term": {
"terms": {
"field": "product_ids.keyword",
"size": 10,
"exclude": "1"
}
}
}
}
An index named orders contains single order documents that have a single
multi-field/array that contains all the product ids that were part of this
order.
Now, retrieving the suggestions for the product with the id 1 means
firing up a query, that contains all orders with that product. However, we
are not interested in single orders but aggregate the other ordered
products based on their id. Also, we want to exclude its own ID, as this
would be the one with the highest count very likely, but should not be
suggested. In the above example, this will return products 2 and 3 with
a document count of 2 each.
Remember, when I said, that I would not use any recommendation service anymore? Well, let’s be honest, the above example is crazy simple. Coming up with a good recommendation service is not easy, and maybe products being bought together are not the best indicator. There are a few issues to be aware of (very similar to your regular search):
- The date of the order is not taken into account. Maybe user behavior changes over time and your query should reflect that by taking only more recent orders into account.
- The number of bought products is not taken into account. If someone buys 10 packs of something in combination, maybe that should be added as well
- Do you reduce a variant to its parent product or do you suggest variants?
- Should you take returns into account?
- Should you take product ratings into account?
- Should you take previous orders of the logged-in account with more weight?
- Should you take product prices into account to only show premium products?
- Should you take visits of products into account even if it didn’t lead to a buy?
- Should you take the generic top sellers into account (or from this category)?
- Should you take product provision into account?
Such an engine could also be used in email campaigns, for personalized recommendations.
This engine might be even more useful after an item has been added to the shopping cart. Maybe just display a single item in that case on the product detail page. Displaying even more products on the product detail page might be too much, as the customer has not placed an item into the shopping cart yet.
With all the different scoring options above I would be even more careful with a black box that suggests products magically to me, would be hard to tune and even harder to understand.
You could have a repeating cronjob, that collects this information and adds it directly at the product data so that there is no need to look this up during rendering of the product detail page.
Analytics
E-commerce is a lot about metrics. Knowing about the product that gets returned most often is crucial. Compared to shop based commerce you can even dig a little bit deeper, like analyzing abandoned shopping carts.
From a search perspective, there are a few statistics, that you should always gather. Remember the middle-ware I mentioned a few times in this article already. That’s a great place to add this functionality. You could gather information about
- Most executed searches of the day
- Searches that did not return any hints, which would allow you to create synonyms or a custom landing page as a follow-up action
- Top-n searches with the longest response times
- Percentiles of your response times
Logging all your searches into an own Elasticsearch cluster will answer all of the above questions pretty easily and even allow for neat dashboards.
A couple of years ago I saw a great talk, where a company had written their own chrome extension, to have a heatmap of where users clicked after a search result was displayed. That was a super neat way of visualizing things and also figuring out if the first row of hits was of good quality.
These analytics might also be able to aid you to plan downtime, but I hope you do have those numbers already somewhere else.
Mobile experience
Mobile phones and tablets were not so much of a big thing when I set up the search engine at my previous employer. But now they make up a sizable portion and I suppose they will surpass desktops this or next year.
Usability is different on those devices and so are searches. The likelihood of typos is much higher on a phone, so you need to account for that. The amount of space for suggestions in the viewport may be much smaller.
Auto correcting search results might help. Google has been doing that for years on its main page as well, telling you it searched for something else and maybe you really want to search for what you typed.
Filter capabilities are often hidden behind a modal to save space (what I mentioned earlier when checking out AboutYou).
If you google for mobile search experience you will find a ton of articles featuring the exact same screenshot of a computer manufacturer not showing any results as a bad search example. I have no idea if that still holds up.
User interfaces have changed over the years. Swiping left and right has become a common motion for liking and disliking, so maybe you want your mobile phone experience to resemble something like that as well, might also be an interesting form of feedback.
Relevancy
So we made it until here in a search article and have not talked about relevancy. The most important part of search - however, you probably have figured out that there are dozens of factors that need to come into play for a proper e-commerce search. This also makes it incredibly hard to measure success or failure.
I remember an on-site visit at one of the top ten IT news sites in Germany. We were meeting with about 15 people and of course the CTO back then came in an hour later without knowing what we talked about the previous hour and said the following
But if we use Elasticsearch, will our search be better?
This made cringe. In my chair. A lot. I was so upset that I asked every attendee what better means for them. I ended up with 10 different definitions within a single and supposedly aligned team.
Everyone wanted a better search, but no one could put a concrete number or strategy on it. One said “more clicks on the first hit”, another one said “increased usage of the search box”. The website got 90% of their visitors from Google, almost no one used the website’s in-house search engine. Another one mentioned “less pagination” - many of them were valid, but no one had created a top 5 list of problems to tackle. This was before the LTR and ML era if I asked that question again at the same company right now, I would probably receive a more advanced answer from a technology point of view, but the fundamentals would still be unanswered.
Besides, no one could come up with a metric on how to measure success or the search being better, and what would be a success percentage-wise or just noise.
So, if someone comes up and asks you to improve relevancy or “our search”, you need to have a very long and painful discussion where you need to get everyone aligned first. What should be the final outcome? Then you need to operationalize those steps, what can be done within the scope of the search engine, and what should be done outside of it - the position of your search input field can already have a different impact.
Display cross/upselling products in each search response
Many users focus only on the first few elements of a search and if those are good. Naturally, the business search owner wants to have those first results good and maybe created manually. While this might be a good idea at the beginning, maybe this is also solving the wrong problem.
Let’s imagine you are trying to buy a bike trailer for kids. Are you really going to check out the first twenty results? Probably not. But when buying a bike trailer, you will also need a bunch of additional things, like a lock, an additional hitch for your partner’s bike, an additional rain/sun cover, a bike helmet for your kid, and so forth.
Maybe it makes sense to only display five results and also hint to additional products that are usually bought when buying a bike trailer.
If that user bought a bike trailer three months ago, maybe that user is searching for replacement parts and does not want to buy the trailer a second time.
This years MICES e-commerce conference had a nice panel about this, talking about diversifying results. Keep your eyes open for more about that in search products in the future.
If your users are power users, they are probably annoyed by such an enriched search response, as they know exactly what they are looking for. For e-commerce, this approach looks good to me. You could even resemble that experience on the product detail page again…
Stable search results
If your customer searches for a term, comes back an hour later, retypes the search and sees completely different results, this might be confusing. This is a topic of perception. In a fast-paced business like hotel booking engines or auction sites, I expect things to change fast. In a less scarcity-based business like a book shop, I expect stable search results. As soon as you take factors like stock or date into account your search results can vary by the second. Keep that in mind.
Semantic Search
Semantic search is a very broad term. It means to understand the intent of
the person executing the search. For e-commerce, this could mean to split the
search into several fields (nike hoodie xl) which is some form of natural
language processing. Semantic search means much more, like taking
the location of a user into account (next to a store where the product is on
stock? Show a banner!), or if the user has navigated to a category, filter
based on that, or using an RDF based search - which I have never seen used
in an e-commerce setting.
I think if many search systems would be able to detect colors, brands, materials, and sizes in their queries, then many searches would be much better. I would not call that a semantic search engine though. It’s more of a decent query rewrite.
Searching for rot gepunktetes kleid (red dress with dots) only Zalando
didn’t show up any search results.
Zalando has a couple of interesting behaviors searching for similar terms or when turning terms around in the query
kleid rot punkteshow one dress with dots, but also blue ones or red oneskleid rot mit punktengets rewritten and only shows black/blue dresseskleid rot punkteshows useful results again, Seems thatmit(with) is not treated as a stop word
This topic still seems hard, which I find rather surprising when testing those big e-commerce shops.
Image feature detection
I know of a couple of search implementations, especially in platform and merchant based environments, where duplicates are likely, that use images for duplicate detection.
I also know of a few systems, that try to extract features from important images. For example, figuring out all colors or if a dress is striped in several colors. There must be a reason why many e-commerce companies ask you to photograph against a white background, right? Still, the error rate here can be rather high. And you need quite a bit of data, so this is usually something for bigger data sets.
Most companies just have an additional field to tag their products and that
one is searched as well. Even though this is a manual process, it allows
easily to search for a dress with dots. Even then a search time like rot gepunktetes kleid needs to be stemmed to gepunktet and then searched in
those fields as well.
Feedback loop
This is an advanced feature and you should never start with it, but it is worth thinking about. It is especially important for suggestions, where you want to make sure, that the suggestions align with the most recent searches, products and orders, so you may want to build an index every hour that only takes the searches from the previous 24 hours into account.
This is a rather short term feedback loop from a search engine implementation perspective.
On a more broad perspective the question usually is, how can you provide feedback to your stakeholders without diving too much into search details. How can you provide results to explain, that your search has improved and you should keep doing something or abort this experiment?
If you only accept suggestions to change your search implementation attached to an expected measurement, then providing a feedback loop to others might become a little easier. This is hard sometimes though.
At times you do not know, what the impact is. What if you half your search response time? Will this increase your conversion rate?
Feedback loops also have a dangerous side aka the winner takes it all. If you search favors previously bought products, newer products will have a very hard time to become relevant. This kind of algorithmic amplification will create some sort of product echo chamber that is hard to break, as the output of the relevance will be the input for the next calculation.
Sprinkling in a little bit of random might be a good idea.
Synonyms
We managed to get down here without the mentioning of synonyms, which is nice. It’s an important building block in any search engine allowing you to group similar terms together.
Synonyms can help normalize your data (this could also be done with proper analysis)
GET _analyze?filter_path=**.token
{
"text": [ "i pod", "ipod", "i-pod"],
"tokenizer": "standard",
"filter": [
{
"type": "synonym_graph",
"synonyms": [
"i pod, i-pod => ipod"
]
}
]
}
The returns ipod for all three tokens, instead of treating the i as a
separate token.
Another common use-case is to group terms together so that searching for
hippo or hippopotamus also returns documents containing Nilpferd (the
German translation).
Stemming
Putting words back into their root form is known as stemming. Stemming can be useful in some languages and can be rather bad in others, as there are two kinds of stemmers. On the one hand, there is an algorithmic stemmer which is rule-based and sometimes has the issue of overstemming. On the other hand, there are dictionary-based stemmers, that are much harder to configure, but even work for languages like german. Let’s see an example of overstemming first:
GET _analyze?filter_path=**.token
{
"text": [ "experience", "experiment"],
"tokenizer": "standard",
"filter": [
"porter_stem"
]
}
The last item returned will be experi in both cases. You will have a hard
time to explain to your users why a document containing experiment will match a
query for experience, as this stemming is rather aggressive.
Let’s try an OpenOffice spell checker now. I downloaded this one from
here,
unzipped it, and put the en_US.dic and en_US.aff file into the
./config/hunspell/en_US directory of Elasticsearch.
GET _analyze?filter_path=**.token
{
"text": [ "experience", "experiment"],
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "hunspell",
"locale": "en_US"
}
]
}
This correctly returns both tokens in their original form. Are we good now?
Well, try the above with both terms as a plural. You will see that
experiences will be returned as-is, as this might be a verb.
In general, test stemmers against your data, also test different algorithmic stemmers, like porter, kstem or snowball before trying to use an algorithmic one. All of the above yield different results, even with the examples above.
LTR (Learning to rank)
LTR would probably justify its own blog post. It might be the most used buzzword in search for the last couple of years before deep learning emerged.
The basic idea of LTR is to incorporate machine learning models into your ranking. There is a learning to rank Elasticsearch plugin available, that allows to store models within Elasticsearch and uses the rescore query to score results against that model.
There is also a blog post about Wikipedia using the above plugin. This post also mentions mjolnir, a tool to transform click logs into ML models.
So on top of your search duties, you have to find a way to properly and constantly convert data into an ML model.
LTR can be extremely powerful, given you have a good model resulting from enough data and someone who knows how this works inside out. It’s quite a way to an automated setup, as well, but powerful.
You can also get creative with LTR problems. Imagine you are diversifying your search results by row, for example, bikes in the first, bike trailers in the second, bike helmets in the third row, bike locks in the fourth row. Now you could use LTR to decide which of those rows is the most important one.
Testing & Search evaluation
So you fought through your data, got a fancy search setup with decent search results. How do you keep the quality of your search? How do you test the quality of your search? Putting this into CI sounds like a good plan.
As most of your e-commerce data is static, having a copy of your live data might be an OK idea, but it gets more complex for dynamic data.
Another approach for are tools like quepid trying to reduce the gap between relevancy experts and domain experts and allowing you to evaluate the effect of changes over longer durations.
One last thing, that is hard to implement. A middle-ware (surprise!) can help running A/B testing for search experiments. Try a new search with a limited amount of users and see if behavior changes. Do not underestimate the complexity of this in combination with a proper setup allowing you to do result & ranking such tests. Once you got this, this can be super powerful, given that you produce enough data.
For Elasticsearch users, you may want to check out the Ranking Evaluation API.
Replacing search engines
At some point you may decide to replace your legacy search engine with your own one or another product. What is a good approach to do this? It’s not so different from replacing other parts of your software stack. First, like in programming, always take baby steps. Get your new fancy search engine up and running and implement the indexing mechanism and the synchronization work to store data in your new search engine as well. Ensure reindexing your data is a piece of cake, you will need to repeat that a lot.
Next, take queries from your live system and performance test. If the load can be sustained, shadow your live searches by always sending your queries to both search engines, but still return the query responses from the existing search engine back to your users. Shadowing means, you need to have some sort of load balancer or middleware which is able to take care of that.
From now on, you can compare search results, automatically log differences and start optimizing step by step - don’t try to replicate the exact results one by one though, that sounds like a never ending task.
Once you are happy refining your shadowed searches, redirect a small portion of your live traffic over to real users. Ensure that the same users always use the same search engine. You could take the session into account and decide based on that. You could also allow the users to pick a search engine, but I think that is too overwhelming for most users.
If you can attribute conversion, searches, etc to the concrete search engine impementation, you can measure if there is a difference of quality between both search engines. Once you are happy with the result, shift more traffic to your new implementation, until all the traffic has been shifted.
Summary
You just read through 45 minutes of trade-offs to keep in mind, congratulations. Hopefully, this does not end in you abandoning search, but rather dive into it, as it can be a great multiplier for your online revenue.
Improving search is not a single step, but an ongoing series of steps. Once you stop, your search quality will visibly deteriorate. Are you up for the challenge of binding manpower and time for this? If not, keep reading.
The future… will be exciting
I think e-commerce tailored search integrations are still at the beginning. It’s great to see that in the last 18 months various initiatives took shape to propel e-commerce search significantly forward. One of the things is to incorporate more signals into ranking like age, provision or price, or nearby shop. Everyone realized that BM25 alone is not a sufficient scoring algorithm but just a part of the score, but now open source communities start with a concrete implementation.
The next step is personalized searches. With Lucene starting to work on support for vectors (Elasticsearch has another implementation) I am eerily excited about the collaboration of Lucene committers in that space. All in all, seeing this kind of searches becoming a commodity over the next years looks nice to me.
That said, there is also some movement on the smarter search front with
tools like quergy, being
much more than just synonym handling, but also the ability to rank
differently or remove terms like cheap from a search query or add/remove
filters based on search terms and also do boost based rewriting.
I have not yet mentioned anything about deep learning, as I think getting the other basics right first is more important to end up with generic solutions. We’ll get there as well :-)
Another nice trend are upcoming open source e-commerce search stacks, like chorus and Open Commerce Search. Excited to watch these as well!
Finally, a reminder that there are only a few stores, who have a lot of documents. Most of the e-commerce webshops can fit their search data easily in memory. A solution based on a low footprint search engine might work wonders here. Tools like CQEngine look very interesting for such setups - of course, non Java technologies in times of serverless and k8s come to mind as well, ranging from tinysearch over meilisearch up to tantivy.
All in all, we can watch out with excitement about what happens in the next years!
Make or Buy?
So far I have managed to avoid talking about money. Running your own search engine, growing your relevance team, machine learning engineers can be prohibitively expensive and will only make sense if you have strategically decided that search is relevant (oh, the pun!) in your company. Your two dozen e-commerce shops with several ten thousand products probably do not fall into this category (you never know, especially with luxury goods).
Of course there are solutions out there helping - I happen to work at a company doing exactly this by offering an Enterprise Search solution, named App Search, which offers a simplified experience allowing you to create a search experience using a React based library called Search UI on the front end and having a neat administration backend to easily tweak things like boosting, pinned products and synonym management, as well as query logs. There is also a magento integration as well as clients for node, php, python, ruby, and javascript.
<biased> You can consider Elastic App Search an implementation of one of those middle-wares that I kept mentioning throughout this post. As all the data is stored in Elasticsearch, you still have all the power available, allowing you to use the same search engine to go from buy to make. </biased>
Books
Books on this topic are unfortunately thin, I have not found a good one on implementing e-commerce search.
- Relevant Search, by Doug Turnbull and John Berryman
- Deep Learning for Search by Tommaso Teofili
- AI powered search by Trey Grainger
- Designing Data-Intensive Applications by Martin Kleppmann
- Database Internals by Alex Petrov
Resources
These are resources that I might have mentioned in the post, but still might be interesting to check out further:
- Berlin Buzzwords, a conference on search, speed and scale
- MICES, a conference about e-commerce search, highly recommended!
- Open Commerce Search, a framework for building commerce search solutions around open source search technology like Elasticsearch
- CQEngine, a high performance java collection which can be searched with SQL like queries
- Chorus, an open source stack for e-commerce search
- LTR4L, LTR for Apache Lucene
- RankLib
- Quarite
- Text similarity with vectors in Elasticsearch
- On-Site Search Design Patterns for E-Commerce
- Paper: Challenges and Research Opportunities in eCommerce Search and Recommendations
Update from 2020-06-24
After publishing this blog post and tweeting about it, I received a couple of useful hints that, I do want to share:
My colleague Honza tweeted about a few things that could be added:
- percolator for query rewriting
- nested name/value attrs for dynamic facets (terms agg on name to get top attr, get facets in 2nd search)
- Stored searches for autocomplete with pre defined filters (red shoes -> color:red AND category:shoes)
My former team mate Jun from Japan tweeted a few replies (1, 2, 3) about differences in non-western languages - which is something I completely ignored, as I only implemented german & english based search solutions so far
Great post! There are some different challenges with Japanese search. Search-as-you-type is more difficult with Japanese Input, tokenization is harder, etc…
For typing Japanese, we usually use IME. This is the software to type and transform Hiragana to Kanji characters. To type Hiragana, we usually hit some roman character to make Hiragana, then IME shows some Kanji chars candidates. See.
Documents has basically only Kanji and Hiragana characters. There is no information about Roman characters. So, we have to make Roman chaacters strings for search-as-you-type index. And also there are many varriation of Roman chars combination… ja = jya = jixya
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!