 Alexander Reelsen
Alexander ReelsenDo Cross The Streams - Elasticsearch Data Streams Explained
TLDR; This blog post will introduce you into the concepts of data streams, including why it’s a good idea to move your time-based data over to data streams and what advantages you will have from doing so. We will go step-by-step to set up your own data streams.
What are Data Streams?
Elasticsearch is often used to store time series. This is a specific workload with a few unique capabilities
- Indexing data is append only, there’s rarely a modification
- Every document contains a timestamp
- Newer data is more relevant, making this suitable for a hot/warm architecture
- Searches usually evolve around a timestamp field
- Data ages out over time
Elasticsearch had basic support for time series data since its inception.
By naming indices based on timestamps like nginx-2015-06-02 you could
store the data from a single day in a single index, and even use date
math
in the index name to search or index data, without knowing the current date.
However, while this basically worked, a few limitations occurred, which lead to the creation of tooling around this like curator.
Over time, more improvements within the stack have been added to support the common time series use-case. Think of Index Lifecycle Management, Index Sorting, Index component templates, Data Tiers and then data streams. We will cover each of those during this blog post and talk about why they were added.
Why are they needed?
So, when you can already cover the use-case of time series data, why is all that infrastructure needed? Usability, edge cases, developer experience - there are many reasons to improve an existing use-case, especially if you consider it a bread-and-butter use-case.
First, the creation date of an index is not a good indicator how big the index will be. It might be very different on Christmas or black friday. Or even worse, when you suffer a DDoS attack, that should not result in differently sized indices or in the worst case, even affect your logging and monitoring infrastructure.
The solution to this is rollover, allowing you to roll over an index based on size or number of documents.
Another issue is sparsity of data and index mapping explosion. If you
index all your data into very few indices (i.e. only filebeat-*), you
will end up with many different fields, ones you index from different data
sources, like nginx logs as well as smtp logs as well as your auth.log.
First this means, that you might end up hitting the 10k mapped fields per
index at some point, but also that the data structure cannot be compressed
that efficiently due to sparsity of the data.
So, how about combining rolling over of data together with dedicated indices for certain data? And how about not worrying about the lifecycle of those? This is basically what data streams allow you to do, so let’s dig into the building blocks first.
As a side note, a lot of Elastic’s products like Fleet and Beats are already using data streams internally, even though this is fully hidden for you, so you do not have to deal with any complexity. We’ll take the fully manual route here to make sure the whole concept is fully understood.
The building blocks
In order to set up a data stream, that is backed by one more indices in the background, you need to set up a proper index template, that configures a set of indices to be a data stream. Let’s index the meetup.com live RSVP data as a data stream - start with creating a proper index template. I will choose smaller values than in a production setup here, so you can recreate the whole rollover/ILM features locally.
Before diving into data streams, let’s do all the preparatory work. One of
those parts is to setup a snapshot repository, so we can make use of
searchable snapshots in the index lifecycle. We need to create a snapshot
directory locally for testing in the elasticsearch.yml like this
path.repo:
- /path/to/elasticsearch-7.13.1/snapshots
Restart Elasticsearch and create a snapshot repository
PUT /_snapshot/meetup.com-snapshot-repo
{
"type": "fs",
"settings": {
"location":
"/path/to/elasticsearch-7.13.1/snapshots/searchable-snapshots"
}
}
If you would run this against a S3 like repository you could run the
Repository analysis
API
to make sure that the implementation behaves correctly like Elasticsearch
expects it to be. Running this against a fs type repository should not
yield any issues, but feel free to try it out yourself:
POST /_snapshot/meetup.com-snapshot-repo/_analyze
Now onto creating a ILM policy
PUT _ilm/policy/meetup.com-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "1gb",
"max_docs": 10000
}
}
},
"warm": {
"min_age": "2d",
"actions": {
"shrink": { "number_of_shards": 1 },
"forcemerge": { "max_num_segments": 1 }
}
},
"cold": {
"min_age": "4d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "meetup.com-snapshot-repo"
}
}
},
"frozen": {
"min_age": "6d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "meetup.com-snapshot-repo"
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
In case you are wondering about the frozen and cold settings for
searchable snapshots - the difference between the two phases are different
performance characteristics due to mounting the searchable snapshot fully,
meaning it contains a copy of the data on the node or partially, where
only recently searched parts of the index are stored locally and are
fetched otherwise.
Now, continue to create an index template
PUT _index_template/meetup.com-template
{
"index_patterns": ["meetup.com*"],
"data_stream": { },
"template" : {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time"
},
"message": {
"type": "wildcard"
},
"group" : {
"type" :"object",
"properties": {
"location" : {
"type" : "geo_point"
}
}
},
"venue" : {
"type" :"object",
"properties": {
"location" : {
"type" : "geo_point"
}
}
}
}
},
"settings": {
"number_of_shards": 2,
"index.lifecycle.name": "meetup.com-policy",
"index": {
"sort.field": "@timestamp",
"sort.order": "desc"
}
}
}
}
So, the built-in mapping contains a timestamp and two geo points as well
as a message field. I did not use component templates intentionally in
order to keep the example slim. By default two shards are created (this will be
reduced down to one via the ILM policy above) plus index sorting in order
to make queries involving the timestamp as efficient as possible. You can
now start indexing data into this data stream or create it via this API
call:
PUT _data_stream/meetup.com
This will create an index named like .ds-meetup.com-2021.07.05-000001
depending on your current date.
Time to get some data in:
Streaming the data
Let’s use Filebeat to get some data into our data stream. There is a
real time stream that emits every RSVP on meetup.com via its on JSON line.
We’ll read this step by step and index into Elasticsearch using Filebeat.
This is our configuration for Filebeat, you can store it in meetup.yaml
name: filebeat-meetups
filebeat.inputs:
- type: stdin
json.keys_under_root: true
json.add_error_key: true
setup.ilm.enabled: false
setup.template.enabled: false
processors:
- rename:
ignore_missing: true
fields:
- from: "group.group_lat"
to: "group.location.lat"
- from: "group.group_lon"
to: "group.location.lon"
when:
has_fields: ['group.group_lat', 'group.group_lon']
- rename:
ignore_missing: true
fields:
- from: "venue.lat"
to: "venue.location.lat"
- from: "venue.lon"
to: "venue.location.lon"
when:
has_fields: ['venue.lat', 'venue.lon']
# remove all the beat specific fields, just have the meetup data
- drop_fields:
fields: [ "log", "agent", "host", "input", "ecs" ]
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "meetup.com"
Now you can run Filebeat like this
curl -s https://stream.meetup.com:443/2/rsvps \
| ./filebeat run -e -c meetup.yml
Taking a look at the above configuration, configures the Elasticsearch
output in Filebeat to index into the data stream. There is some mangling
of the documents to make sure that the venue.location and
group.location fields are in a proper format to be indexed as a geo
point.
Also, ILM is disabled in the Filebeat configuration in this case, because we set up the data stream manually.
Going through the lifecycle
You can wait a little and index some data, and at some point 10k documents will be indexed for a rotation. While this is supposed to be happen, you can use the Resolve Index API to see which backing indices a data stream has (right now it’s probably only a single one).
GET /_resolve/index/meetup.com
This returns something like
{
"indices" : [ ],
"aliases" : [ ],
"data_streams" : [
{
"name" : "meetup.com",
"backing_indices" : [
".ds-meetup.com-2021.07.05-000001"
],
"timestamp_field" : "@timestamp"
}
]
}
The response shows the backing indices as well as the default timestamp field. The nice part about the API is that it also works with indices.
Another interesting endpoint is the Data stream stats API showing some statistics about the specified data stream. See this example
GET /_data_stream/meetup.com/_stats?human
returning
{
"_shards" : {
"total" : 4,
"successful" : 2,
"failed" : 0
},
"data_stream_count" : 1,
"backing_indices" : 1,
"total_store_size" : "4.3mb",
"total_store_size_bytes" : 4519696,
"data_streams" : [
{
"data_stream" : "meetup.com",
"backing_indices" : 1,
"store_size" : "4.3mb",
"store_size_bytes" : 4519696,
"maximum_timestamp" : 1625492590826
}
]
}
This only returns a single data stream, but keep in mind that something
like nginx-* could return data about access logs, error logs and stats,
and so contain information from several data streams.
You can also retrieve data stream information via the Get data stream API:
GET /_data_stream/meetup.com
returning
{
"data_streams" : [
{
"name" : "meetup.com",
"timestamp_field" : {
"name" : "@timestamp"
},
"indices" : [
{
"index_name" : ".ds-meetup.com-2021.07.05-000001",
"index_uuid" : "6DR0BSYIRM6ET-UpuqFaHw"
}
],
"generation" : 1,
"status" : "YELLOW",
"template" : "meetup.com-template",
"ilm_policy" : "meetup.com-policy",
"hidden" : false,
"system" : false
}
]
}
After running this around an hour in the background you should hit the 10k document limit configured above and the first step of ILM kicks in with a rollover of the index, resulting in the get data stream output looking like this and showing to backing indices
{
"data_streams" : [
{
"name" : "meetup.com",
"timestamp_field" : {
"name" : "@timestamp"
},
"indices" : [
{
"index_name" : ".ds-meetup.com-2021.07.05-000001",
"index_uuid" : "6DR0BSYIRM6ET-UpuqFaHw"
},
{
"index_name" : ".ds-meetup.com-2021.07.06-000002",
"index_uuid" : "pb34AnDvThWt5GAqJHFSgg"
}
],
"generation" : 2,
"status" : "YELLOW",
"template" : "meetup.com-template",
"ilm_policy" : "meetup.com-policy",
"hidden" : false,
"system" : false
}
]
}
Retrieving the settings for .ds-meetup.com-2021.07.05-000001, as we need
to wait until the warm phase kicks in and reduces the number of shards.
You can see in the
settings.index.routing.allocation.include._tier_preference that is
currently set to data_hot, but will automatically change to warm after
two days - or whatever else is configured in the ILM policy.
Let’s take a look using the ILM explain API to figure out what’s up with our shards after the warm phase started:
GET meetup.com/_ilm/explain
returns
{
"indices" : {
".ds-meetup.com-2021.07.06-000002" : {
...
},
"shrink-wci4-.ds-meetup.com-2021.07.05-000001" : {
"index" : "shrink-wci4-.ds-meetup.com-2021.07.05-000001",
"managed" : true,
"policy" : "meetup.com-policy",
"lifecycle_date_millis" : 1625563277613,
"age" : "2.06d",
"phase" : "warm",
"action" : "complete",
"action_time_millis" : 1625651863313,
"step" : "complete",
"step_time_millis" : 1625651863313,
"shrink_index_name" : "shrink-wci4-.ds-meetup.com-2021.07.05-000001"
}
}
}
As you can see, the shrink action has already been run and created a new shrunk index, that contains only a single shard when checking via
GET shrink-wci4-.ds-meetup.com-2021.07.05-000001/_settings
The response not only mentions that only one shard is used, it also has a write block set and the following routing allocation
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_warm,data_hot"
},
"initial_recovery" : {
"_id" : "fZhL9ocFSr22NFU5D1G83A"
},
"require" : {
"_id" : null
}
}
}
This means, that the cluster prefers this index to be on a node within the
warm tier.
After some more time, the index will be snapshotted and used as a searchable snapshot. The output of the Explain ILM API then looks like this
{
"indices" : {
".ds-meetup.com-2021.07.06-000002" : {
...
},
"restored-shrink-wci4-.ds-meetup.com-2021.07.05-000001" : {
"index" : "restored-shrink-wci4-.ds-meetup.com-2021.07.05-000001",
"managed" : true,
"policy" : "meetup.com-policy",
"lifecycle_date_millis" : 1625563277613,
"age" : "1.07d",
"phase" : "cold",
"action" : "complete",
"step" : "complete",
"repository_name" : "meetup.com-snapshot-repo",
"snapshot_name" : "2021.07.07-shrink-wci4-.ds-meetup.com-2021.07.05-000001-meetup.com-policy-j_r3fcl8tpajxvtwfhfeqa",
"shrink_index_name" : "shrink-wci4-.ds-meetup.com-2021.07.05-000001"
}
}
}
You can retrieve the snapshot info via the Get Snapshot API against the
above shown snapshot_name.
Index Lifecycle Management and data tiers
In order to understand the whole picture, we need to step into a side quest and learn a little about data tiers. If you remember our index lifecycle policy at the beginning, it was written like this:
{
"policy": {
"phases": {
"hot": { },
"warm": { },
"cold": { },
"frozen": { },
"delete": { }
}
}
}
Those five phases are are hard coded in the index lifecycle. Whenever a
change in one of those policies implied that data needed to be sent to
another node type (i.e. from hot to warm), this needed to be reflected
in the index attributes to trigger a shard re-allocation.
As of Elasticsearch 7.10 this has been formalized as Data
tiers.
Those consist of the above known tiers hot, warm, cold, frozen
plus a content tier, that basically reflects a non tier, for when you
don’t have time based data.
These tiers are configured via node roles, i.e.
node.roles: ["data_hot", "data_content"]
There is also a dedicated _tier_preference field in the
index.routing.allocation settings for
indices,
which is also used by data streams.
Starting with Elasticsearch 7.14 there will be a dedicated API to help you in Migrating to data tiers by moving from custom node attributes to data tiers for indices and ILM allocation filtering.
Migrating from indices to data streams
To be able to easily use data streams, there is dedicated API to ‘upgrade’
from an index alias to a data stream, the Migrate to data stream
API.
This however requires at least Elasticsearch 7.11. Looking at this API
from a code perspective, one of the steps is adding a field to the mapping
named mappings._data_stream_timestamp.enabled set to true. Also, in the
index settings the index is marked as
hidden,
thus not returned by default even if wildcard expression matches.
This allows for an easy switch from regular indices to data streams.
Starting with Elasticsearch 7.14 there is also a Migrate to data tiers API simplifying to move to data tiers by changing custom node attributes within indices and index templates. Keep in mind that ILM must be stopped for this to work.
Optimizations on the query side/storage side
Essentially data streams simplifies or eases the handling of index creation and lifecycle management. However that is only one side of the equation. There is also storage improvements and query improvements to deal with a probably bigger amount of indices. One of the important building blocks was added in Elasticsearch 7.7 by significantly reducing the heap usage of shards allowing to fit much more data into a node while keeping the heap the same, improving the heap to storage ratio. The other important step was adding searchable snapshots, completely removing data from a cluster and optionally keeping a local copy around if needed.
Also the amount of data stored on disk keeps improving, for example by using
index sorting.
Index sorting comes with a performance cost on the indexing side, but
there is currently work being done to speed this up. Another is a newly
introduced variant of the text field named
match_only_text,
that stores less data, which is usually only used for queries that are not
often used in combination with time series data. This field will be released
in Elasticsearch 7.14.
Another idea is to remove more fields like _id and seq_no, even though
that will take some more time, you can follow the discussion in this GitHub
issue.
There is another optimization in the so called can_match query phase,
that checks very quick if a shard needs to be addressed at all. When running
against searchable snapshots, the min/max time values of the timestamp field
are also taken into account to prevent fetching data from a snapshot
repository if outside of a time range. You can check this via the cluster
state metadata
GET _cluster/state/metadata/.ds-meetup.com-*?filter_path=**.timestamp_range
After a searchable snapshot has been created, this will look like
{
"metadata" : {
"indices" : {
".ds-meetup.com-2021.07.06-000002" : {
"timestamp_range" : {
"unknown" : true
}
},
"restored-shrink-wci4-.ds-meetup.com-2021.07.05-000001" : {
"timestamp_range" : {
"min" : 1625483495849,
"max" : 1625563267347
}
}
}
}
}
The can_match search phase however is doing a little more by checking if a
query can be rewritten to a match_all or match none query, which would
make it also more eligible for caching.
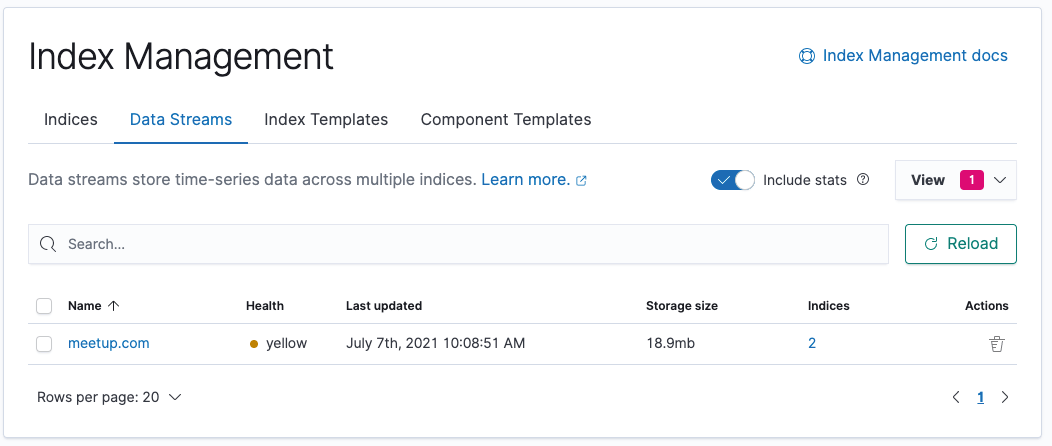
Data Streams in Kibana
There is a Data Streams UI in the Index Management tab, allowing you to
see the existing data streams along with their backing indices - which are
not shown in the regular Indices tab, unless you include hidden indices.
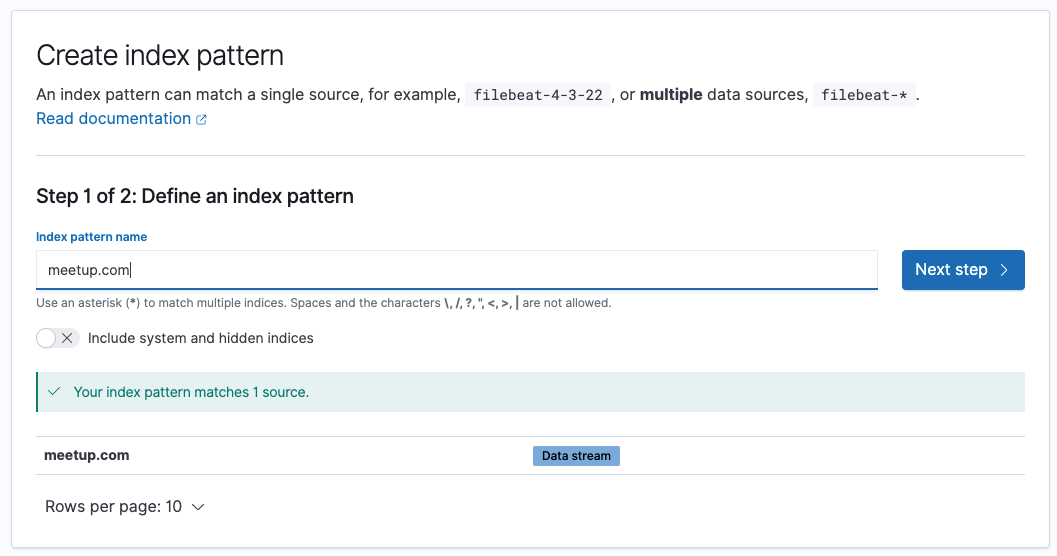
You can also create index patterns based on data streams, which is as easy as specifying indices.
Summary
Data streams are the most modern way to implement time series data with the Elastic Stack, so whenever you encounter a new use-case, you should go with them. Also migrating to data streams will become easier with the next versions.
Data streams are backed by a lot of different concepts that require some understanding like
- Index Lifecycle Management
- Index templates
- Data tiers
- Snapshots
However most of those concepts are already known and data streams are basically a standardization or formalization of these concepts for the concrete time series use-case.
For questions going to the Elastic Stack Discussion Forum is always a good idea. Always remember: There are no stupid questions!
Now go ahead and do cross the streams.
Resources
- Elasticsearch Data streams documentation
- Blog post: Elastic data stream naming scheme
- Elasticsearch Index templates and component templates documentation
- Documentation: How to manage Elasticsearch data across multiple indices with Filebeat, ILM, and data streams
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so and append to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!