 Alexander Reelsen
Alexander ReelsenUsing Elasticsearch Transforms For Product Recommendations
TLDR; This blog post will walk you through the steps go create product recommendations from an index containing order items. The post shows how to use transforms to automatically create this data from constantly updated order items and utilizes the enrich processor to store recommendations when indexing new products.

Four steps to end up with in-document recommendations
In order to get started I use the File Visualizer to import an
ecommerce data set from
kaggle. I downloaded
the olist_order_items_dataset which contains a CSV file with order items.
If you don’t care for the import of our sample data, skip directly to the Steps to transform the data section.
Using File Visualizer to Import Data
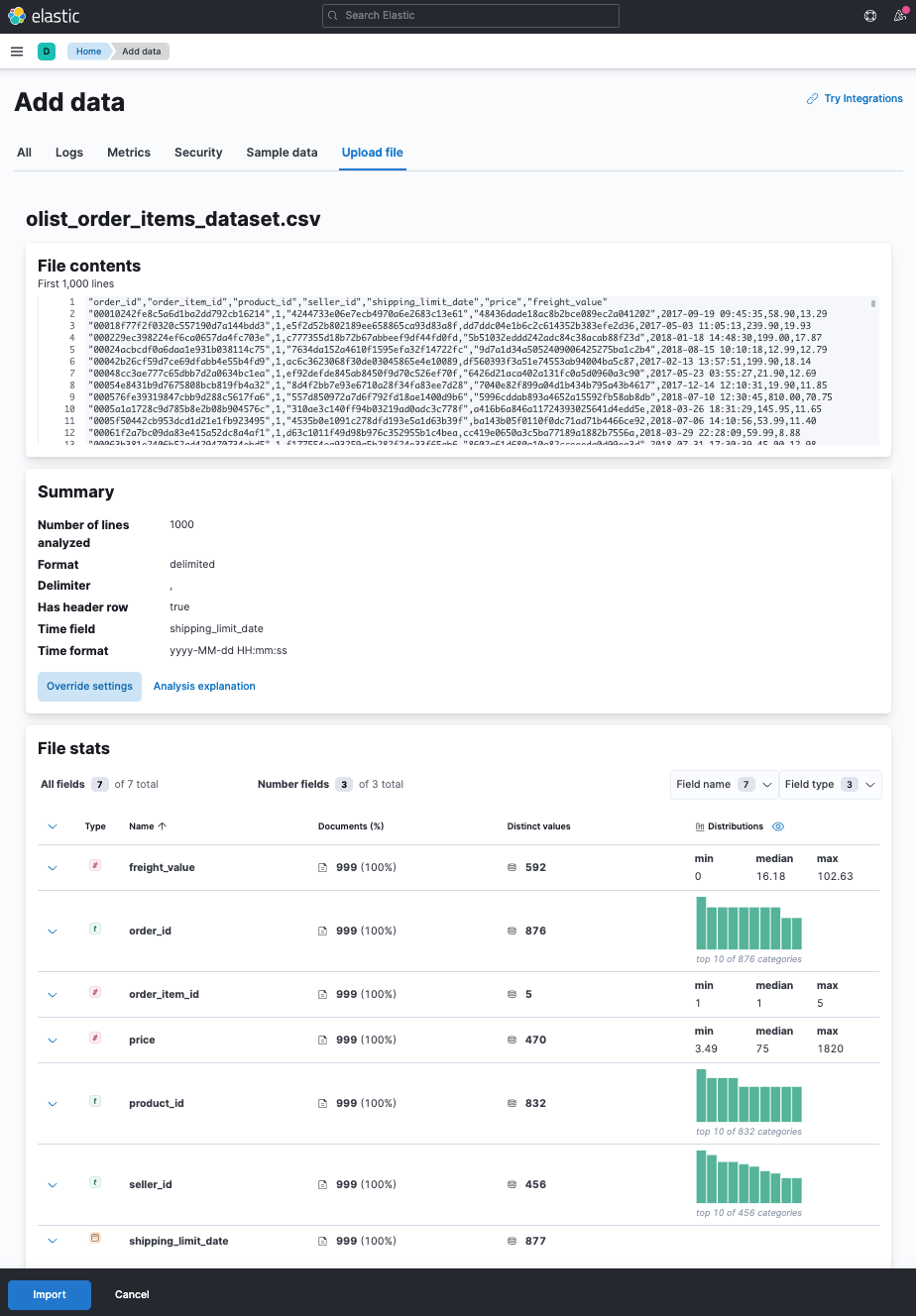
Using the file visualizer you can see some import stats before importing.
Create an index pattern
Just a reminder to not uncheck the Create Index Pattern box, as this can
be used in Kibana Discover.
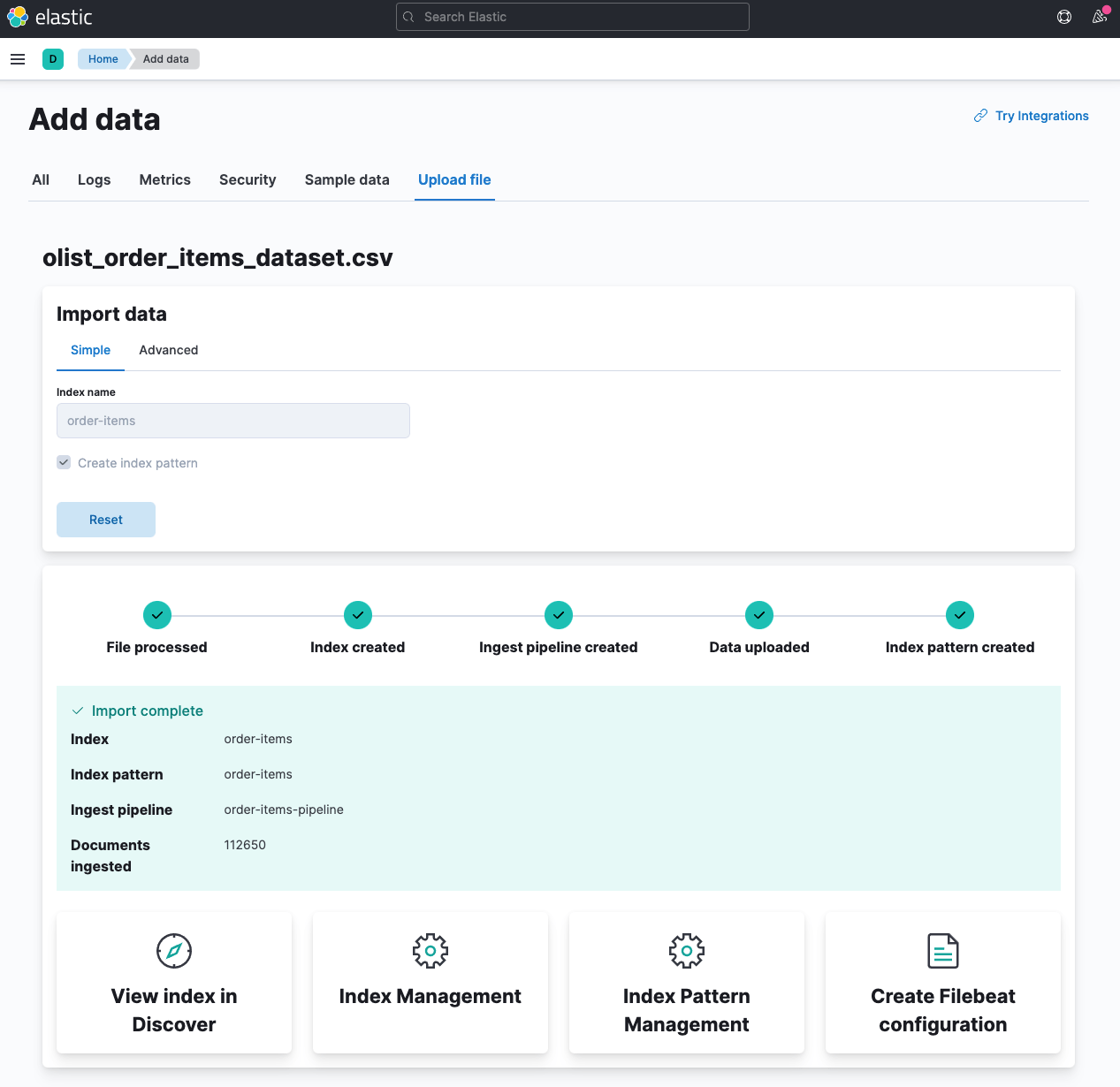
Import going on.
The import should take less than a minute, as the total number of documents exceeds a little more than 110k.
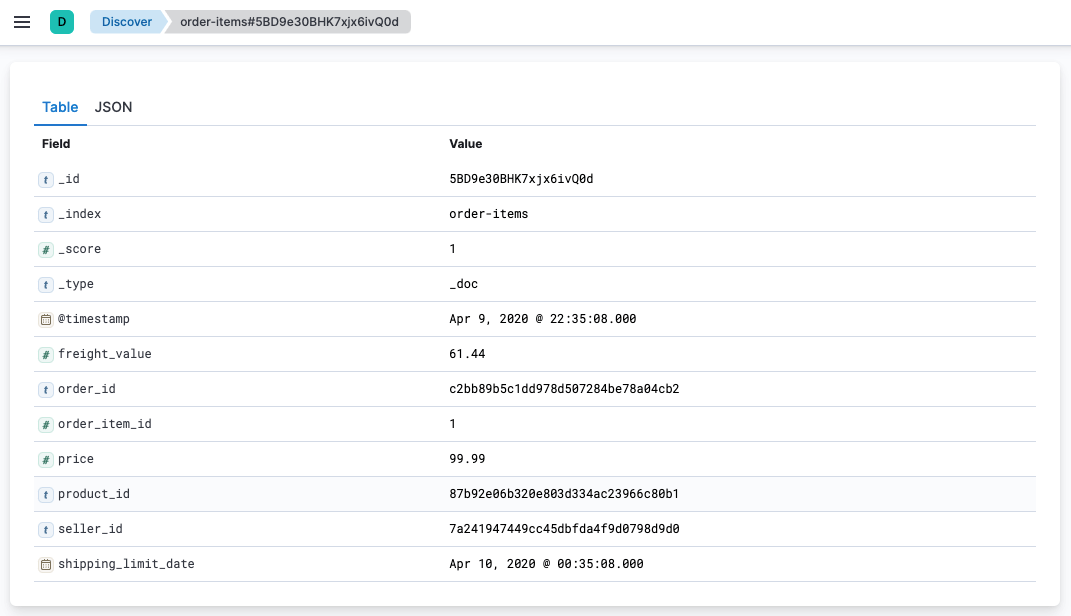
Document details in Kibana Discover
Steps to transform the data
The data set contains order items, so one document for each item of an order. Looking like this:
{
"order_item_id" : 1,
"@timestamp" : "2017-09-26T02:11:19.000+02:00",
"price" : 89.9,
"product_id" : "764292b2b0f73f77a0272be03fdd45f3",
"order_id" : "4427e7da064254d8af538aca447a560c",
"freight_value" : 12.97,
"seller_id" : "bd23da7354813347129d751591d1a6e2",
"shipping_limit_date" : "2017-09-26 02:11:19"
}
Only two fields are important to us, namely order_id and product_id.
So, how do we get from such a data set to the ability to figure out
recommendations on a per-product base? By creating new indices from that
data based on different grouping criteria. So basically we need to get from
order_id -> product_id mapping to a product_id -> recommendation_ids
mapping, completely independent from the product order. Let’s try this with
transforming the data twice like this:
Transforming from order items to product recommendations
So, what does this diagram mean? First, we transform from an ungrouped list of order-items to a list of orders, which contain the products that have been part of that order.
Our second step will be an index of documents resembling products, that contain a list of products that have been ordered together.
Transforming to orders
In order to understand the problem, let’s try to find products that have been ordered together manually.
First, find the most bought product:
GET order-items/_search
{
"size": 0,
"aggs": {
"by_product_id": {
"terms": {
"field": "product_id",
"size": 10
}
}
}
}
This shows one product ordered 527 times. Let’s filter for that
GET order-items/_search
{
"query": {
"term": {
"product_id": {
"value": "aca2eb7d00ea1a7b8ebd4e68314663af"
}
}
}
}
So this returns 10 order items from 527 results. We could go naive and collect all order ids on the client side via
GET order-items/_search?filter_path=**.order_id
{
"size": 10000,
"query": {
"term": {
"product_id": {
"value": "aca2eb7d00ea1a7b8ebd4e68314663af"
}
}
}
}
and then use the terms filter to filter for those by adding all the
order_id from the previous response to the terms filter in the following
query:
GET order-items/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{ "terms": {
"order_id": [
"44676f5946200b6318a3a13b081396bc",
"..."
]
}}
]
}
},
"aggs": {
"by_order": {
"terms": {
"field": "product_id",
"size": 10
}
}
}
}
This will give us a list of three product ids in the aggs response
{
"aggregations" : {
"by_order" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "aca2eb7d00ea1a7b8ebd4e68314663af",
"doc_count" : 527
},
{
"key" : "28b4eced95a52d9c437a4caf9d311b95",
"doc_count" : 1
},
{
"key" : "7fb7c9580222a2af9eb7a95a6ce85fc5",
"doc_count" : 1
}
]
}
}
}
The first hit is the product itself and needs to be removed. That leaves us with two products that have been bought together. We involved a lot of queries. Let’s try to solve with this a transform and explain it step-by-step:
PUT _ingest/pipeline/orders-set-id
{
"description": "Sets _id to order id",
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx._id = ctx.order_id;"
}
}
]
}
PUT _transform/order-item-transform-to-orders
{
"source": { "index": "order-items" },
"dest": { "index": "orders", "pipeline": "orders-set-id" },
"frequency": "1h",
"pivot": {
"group_by": {
"order_id": {
"terms": {
"field": "order_id"
}
}
},
"aggregations": {
"products": {
"scripted_metric": {
"init_script": "state.docs = [:];state.docs.products = []",
"map_script": """
state.docs.products.add(doc['product_id'].value);
""",
"combine_script": "return state.docs",
"reduce_script": """
def products = new HashSet();
for (state in states) {
products.addAll(state.products);
}
return ['ids': products, 'length':products.size()];
"""
}
}
}
}
}
POST _transform/order-item-transform-to-orders/_start
# wait a second for the first run to finish, then run
GET orders/_count
With the data set we had 112650 initial order items. Reducing them to a
list of orders leads to 98666 orders. So most of our orders have been
single product orders.
Let’s go through the transform step by step. First, we define a
source.index to get the data from and a dest.index to write the data to.
Then the frequency determines how often the transform runs in the
background. The pivot.group_by criteria is the field to group by. As we
want to group by order to collect all product ids, the order_id is the
initial grouping criteria.
Now comes the fancy part - the scripted metric aggregation. A very powerful
way to collect data for aggregations in the most customized way. The
scripted metric aggregation consists of four phases, and each phase is
scriptable. The first phase allows to initialize data structures that are
reused in other phases. In this example a sample docs map, that contains
an empty products array is created in the init_script.
state.docs = [:];
state.docs.products = [];
The next phase is the map_script, which is executed once for every
document matching the query (so every document in this example).
state.docs.products.add(doc['product_id'].value);
The next phase named combine_script is executed once per shard and would
allow to reduce data sent to the coordinating node by doing some more work
before it is send.
return state.docs;
The final step is to collect all the data from different shards from all the order items and create the final data structure for this single order. In this example we collect the product ids in a set (to prevent duplicates) and also store the size of that set to allow for easier range queries.
def products = new HashSet();
for (state in states) {
products.addAll(state.products);
}
return ['ids': products, 'length':products.size()];
Let’s take a look at a single order
GET orders/_search
{
"size": 1
}
shows
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "orders",
"_type" : "_doc",
"_id" : "00010242fe8c5a6d1ba2dd792cb16214",
"_score" : 1.0,
"_source" : {
"order_id" : "00010242fe8c5a6d1ba2dd792cb16214",
"products" : {
"length" : 1,
"ids" : [
"4244733e06e7ecb4970a6e2683c13e61"
]
}
}
}
]
}
}
The shown order consists of a single order item With this index finding
products that have been ordered together is only a single query away, once
we know a product id, like 0bcc3eeca39e1064258aa1e932269894 in this
example.
GET orders/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"term": {
"products.ids.keyword": "0bcc3eeca39e1064258aa1e932269894"
}
}
]
}
},
"aggs": {
"products": {
"terms": {
"field": "products.ids.keyword",
"size": 10
}
}
}
}
This returns the following aggregations response:
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 4,
"buckets" : [
{
"key" : "0bcc3eeca39e1064258aa1e932269894",
"doc_count" : 100
},
{
"key" : "422879e10f46682990de24d770e7f83d",
"doc_count" : 6
},
{
"key" : "368c6c730842d78016ad823897a372db",
"doc_count" : 4
},
{
"key" : "389d119b48cf3043d311335e499d9c6b",
"doc_count" : 3
},
{
"key" : "53759a2ecddad2bb87a079a1f1519f73",
"doc_count" : 3
},
{
"key" : "b0961721fd839e9982420e807758a2a6",
"doc_count" : 3
},
{
"key" : "3773a3773f5978591cff7b3e614989b3",
"doc_count" : 1
},
{
"key" : "4b5df063d69ffafb87c279672ecb4191",
"doc_count" : 1
},
{
"key" : "4e1346d7b7e02c737a366b086462e33e",
"doc_count" : 1
},
{
"key" : "774e21c631ca26cba7b5606bdca7460f",
"doc_count" : 1
}
]
}
}
So, we have a bunch of other products bought with this product! The first product is the product we queried for - you could either filter this out manually or change the aggregation to exclude it like this:
"aggs": {
"products": {
"terms": {
"field": "products.ids.keyword",
"size": 10,
"exclude": "0bcc3eeca39e1064258aa1e932269894"
}
}
}
The rest of that list is a sorted list, which products have been bought together, including a weighting based on the number of orders these documents have been combined. Pretty neat!
We could also require a minimum doc count in order to be in the result list like this:
"aggs": {
"products": {
"terms": {
"field": "products.ids.keyword",
"size": 10,
"exclude": "0bcc3eeca39e1064258aa1e932269894",
"min_doc_count": 2
}
}
}
This would reduce our results to five in this example and make sure there is a somewhat stronger correlation between products being bought.
So, basically we’re done now, aren’t we? If you have a small data set, this is probably good enough to run an aggregation every time a user watches your page including such recommendations. You could also go simple and just cache the above result for 10 minutes to prevent a thundering herd issue when a lot of users take a look at the same product.
However, we could also go on and instead of basing our data on orders, we could have a product centric index. It’s just one more transform away!
Transforming to product recommendations
To save you some time tinkering around, let’s add an ingest pipeline first, to fix some minor issues
PUT _ingest/pipeline/products-remove-own-id-pipeline
{
"description": "Removes the own product id from the list of recommended product ids and renames the 'ids' field",
"processors": [
{
"script": {
"lang": "painless",
"source": """
ctx.ids.removeAll([ctx.product_id]);
ctx['recommendation_ids'] = ctx.remove('ids');
ctx._id = ctx.product_id;
"""
}
}
]
}
This pipeline removes duplicates in the ids element and then renames ids
to recommendation_ids. The last part is to the set _id to the id of the
product instead of an auto generated one.
OK, now let’s create a transform using the previously transform created index as an input:
PUT _transform/orders-transform-to-products
{
"source": {
"index": "orders",
"query": {
"range": {
"products.length": {
"gt": 1
}
}
}
},
"dest": {
"index": "product-recommendations",
"pipeline" : "products-remove-own-id-pipeline"
},
"frequency": "1h",
"pivot": {
"group_by": {
"product_id": {
"terms": {
"field": "products.ids.keyword"
}
}
},
"aggregations": {
"ids": {
"scripted_metric": {
"init_script": "state.docs = [:];state.docs.products = []",
"map_script": """
for (def i = 0; i< doc['products.ids.keyword'].size();i++) {
def id = doc['products.ids.keyword'].get(i);
state.docs.products.add(id);
}
""",
"combine_script": "return state.docs",
"reduce_script": """
def products = new HashSet();
for (state in states) {
products.addAll(state.products);
}
return products;
"""
}
}
}
}
}
POST _transform/orders-transform-to-products/_start
The major difference here is the map_script containing most of the logic
as well as the group_by grouping criteria. First, the orders index is
used, but only those orders, that have more than one order item are used as
input, otherwise there will not be a link to other products. This time the
group_by criteria is the product id, as this is what we want to be our new
index based on.
Because of the product.length query filter, we already know that the
product.ids array will be bigger than a single element. So in the
map_script we walk through that array and for each product id found we
append it to the stats.docs.products array. The final reducing in case of
several shards, happens in the reduce script by using a set again to
prevent duplicates.
Time to check out the product we used above
GET product-recommendations/_doc/0bcc3eeca39e1064258aa1e932269894
returns
{
"_index" : "product-recommendations",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 227,
"_primary_term" : 1,
"found" : true,
"_source" : {
"recommendation_ids" : [
"dfc9d9ea4c2fbabe7abb0066097d9905",
"368c6c730842d78016ad823897a372db",
"98e0de96ebb0711db1fc3d1bad1a902f",
"3773a3773f5978591cff7b3e614989b3",
"4e1346d7b7e02c737a366b086462e33e",
"4b5df063d69ffafb87c279672ecb4191",
"53759a2ecddad2bb87a079a1f1519f73",
"b0961721fd839e9982420e807758a2a6",
"389d119b48cf3043d311335e499d9c6b",
"9d1893083966b9c51109f0dc6ab0b0d9",
"422879e10f46682990de24d770e7f83d",
"774e21c631ca26cba7b5606bdca7460f",
"d1c427060a0f73f6b889a5c7c61f2ac4"
],
"product_id" : "0bcc3eeca39e1064258aa1e932269894"
}
}
You can see that the ingest pipeline has worked, because of the _id being
equal to the product_id and the product_id is not part of the
recommendation_ids array.
There is one weakness in this particular approach, compared to the query
earlier: We lost all the weighting. There is no indication if one product
had been bought together once or eight times compared to the query, also the
recommendation_ids field is not sorted by this. We should probably fix that
first, before going further.
Adding back weights in the transform
All we need is a map with counts, it seems. So let’s work on the transform via the preview functionality (don’t forget to store the transform if you run it later, it’s not shown in this post):
First, stop the transform, delete the transform, delete the index
POST _transform/orders-transform-to-products/_stop
DELETE _transform/orders-transform-to-products
DELETE product-recommendations
Next update the ingest pipeline due to a different data structure than just an array of ids:
PUT _ingest/pipeline/products-remove-own-id-pipeline
{
"description": "Removes the own product id from the list of recommended product ids and renames the 'ids' field",
"processors": [
{
"script": {
"lang": "painless",
"source": """
ctx.ids.removeIf(p -> p.id.equals(ctx.product_id));
ctx['recommendation_ids'] = ctx.remove('ids');
ctx._id = ctx.product_id;
"""
}
}
]
}
Now let’s adapt the transform:
POST _transform/_preview
{
"source": {
"index": "orders",
"query": {
"range": {
"products.length": {
"gt": 1
}
}
}
},
"dest": {
"index": "product-recommendations",
"pipeline": "products-remove-own-id-pipeline"
},
"frequency": "1h",
"pivot": {
"group_by": {
"product_id": {
"terms": {
"field": "products.ids.keyword"
}
}
},
"aggregations": {
"ids": {
"scripted_metric": {
"init_script": "state.docs = [:];state.docs.products = [:]",
"map_script": """
// push all products into an array
for (def i = 0; i< doc['products.ids.keyword'].size();i++) {
def id = doc['products.ids.keyword'].get(i);
state.docs.products.compute(id, (k, v) -> (v == null) ? [ 'id':id, 'count': 1L] : [ 'id':id, 'count': v.count+1]);
}
""",
"combine_script": "return state.docs",
"reduce_script": """
// merge same ids together
def products = [];
for (state in states) {
for (product in state.products.values()) {
def id = product.id;
def optional = products.stream().filter(p -> id.equals(p.id)).findFirst();
if (optional.isPresent()) {
optional.get().count += product.count;
} else {
products.add(product);
}
}
}
// sort list by count of products!
Collections.sort(products, (o1,o2) -> o2.count.compareTo(o1.count));
return products;
"""
}
}
}
}
}
# Change the above request to save the transform instead of preview, then start
PUT _transform/orders-transform-to-products
{
..
}
POST _transform/orders-transform-to-products/_start
Now after restarting the transform, we can run a simple GET request on the product id
GET product-recommendations/_doc/0bcc3eeca39e1064258aa1e932269894
which returns
{
"_index" : "product-recommendations",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 227,
"_primary_term" : 1,
"found" : true,
"_source" : {
"product_id" : "0bcc3eeca39e1064258aa1e932269894",
"recommendation_ids" : [
{
"count" : 6,
"id" : "422879e10f46682990de24d770e7f83d"
},
{
"count" : 4,
"id" : "368c6c730842d78016ad823897a372db"
},
{
"count" : 3,
"id" : "53759a2ecddad2bb87a079a1f1519f73"
},
{
"count" : 3,
"id" : "b0961721fd839e9982420e807758a2a6"
},
{
"count" : 3,
"id" : "389d119b48cf3043d311335e499d9c6b"
},
{
// more documents with a count of 1
}
]
}
}
Now by retrieving such a document the client side can decide if a count of
1 is sufficient for a product to be displayed.
There is one more advantage of putting this into an own index. With the ability to query for documents that contain its together bought products, we can even go further and add this information at index time, when a product is indexed by using an enrich policy.
If you want to get some more statistics about your transform, you can run
GET _transform/order-item-transform-to-orders/_stats
GET _transform/orders-transform-to-products/_stats
Creating an Enrich Policy
Imagine we are storing the products of our storefront in the products
index. Whenever a component updates a product we could enrich it with the
ids of the products being bought together. Now that we have a ready made
product-recommendations index, the next step is to create an enrich policy
out of that.
PUT /_enrich/policy/product-recommendation-policy
{
"match": {
"indices": "product-recommendations",
"match_field": "product_id",
"enrich_fields": ["recommendation_ids"]
}
}
POST /_enrich/policy/product-recommendation-policy/_execute
This creates an intermediary index within that policy. Note that this needs to be executed after changes in order for the policy to stay up-to-date with the indices in the background.
Next up is an ingestion pipeline, that queries the above policy using the
_id field of the document. The rename and remove processors are just
for some cleanup of the data structure, but are fully optional.
PUT _ingest/pipeline/product-recommendations-pipeline
{
"processors": [
{
"enrich": {
"policy_name": "product-recommendation-policy",
"field": "_id",
"target_field": "ids"
}
},
{
"rename": {
"field": "ids.recommendation_ids",
"target_field": "recommendation_ids"
}
},
{
"remove": {
"field": "ids"
}
}
]
}
And finally time for some indexing and then retrieving the document to see that the pipeline was applied properly
PUT products/_doc/0bcc3eeca39e1064258aa1e932269894?pipeline=product-recommendations-pipeline
{
"title" : "My favourite product"
}
GET products/_doc/0bcc3eeca39e1064258aa1e932269894
Getting the product returns
{
"_index" : "products",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "My favourite product",
"recommendation_ids" : [
{ "count" : 6, "id" : "422879e10f46682990de24d770e7f83d" },
{ "count" : 4, "id" : "368c6c730842d78016ad823897a372db" },
{ "count" : 3, "id" : "53759a2ecddad2bb87a079a1f1519f73" },
{ "count" : 3, "id" : "b0961721fd839e9982420e807758a2a6" },
{ "count" : 3, "id" : "389d119b48cf3043d311335e499d9c6b" },
{ "count" : 1, "id" : "dfc9d9ea4c2fbabe7abb0066097d9905" },
{ "count" : 1, "id" : "3773a3773f5978591cff7b3e614989b3" },
{ "count" : 1, "id" : "98e0de96ebb0711db1fc3d1bad1a902f" },
{ "count" : 1, "id" : "4e1346d7b7e02c737a366b086462e33e" },
{ "count" : 1, "id" : "4b5df063d69ffafb87c279672ecb4191" },
{ "count" : 1, "id" : "9d1893083966b9c51109f0dc6ab0b0d9" },
{ "count" : 1, "id" : "774e21c631ca26cba7b5606bdca7460f" },
{ "count" : 1, "id" : "d1c427060a0f73f6b889a5c7c61f2ac4" }
]
}
}
Reiterating the journey
So, this was quite the punch, let’s quickly reiterate what we did here - and why we did it.
- Import CSV data of order items, one line per item resulting in one document per order item
- Use a transform to group order items to single orders, being able to aggregate products that have been bought together via a query
- Use a transform to group products together, that have been bought together, so that no query but a retrieval of a single document is all it takes
- Revamp that transform to get information which product has been bought together how many times with other products, grouping most bought together products together
- Create an enrich policy out of that final transform index, so that products can be enriched on index time with products that have been bought together
Four steps to end up with in-document recommendations
Taking recency into account
Recency is something we have not taken into account yet in this example in
order to keep it small. In this example, we used all of the data from the
order-items index in order to create an orders index. We could have used
the data from the last 1d as a range query in order to only take recent
order items into account. In addition every transform supports a
retention_policy field, allowing you to delete data that is older than a
certain timestamp. If you also change the two pipelines being used to store
the ctx._timestamp field in the document, so you know when a document is
too old.
On the other hand there might be a use-case for products that have not been bought for sometime to keep the historic data around instead of not offering any recommendations at all as well as the possibility to exclude certain dates of your order-items (black Friday or Christmas or when you did that one TV ad) if want to exclude this data to not skew the results - which I would always include.
Summary
As usual, the summary is about food for thought. And the first part is not so much about technical issues like the inefficient scripting in aggregations, which have room for improvement.
The biggest hurdle to this might be data quality and data trustworthiness.
First, data quality. Do you have enough orders and order items that such an enrichment actually makes sense? Are you sure you data is not skewed by a dozen people ordering the same things?
Second, data trustworthiness. Is this actually the correct data to look for? Do you want to display recommendations for orders or maybe do this somewhat earlier by displaying recommendations based on what users were visiting, instead of buying as you may have more such data.
Third, this is a classic “winner takes it all approach” for recommendations,
making it really hard to get newcomer products scored up if you only look
into past data. Also, if you have a few common goods that are always bought
together (like milk and bread in a food store), then those would totally
skew the results towards those common goods, despite them not being a good
match to be bought together. This is what the significant_terms
aggregation could be used for instead - which is not supported in transforms
currently, requiring another process to create those recommendations.
One advantage of this approach is having a closed loop. The moment you index all the order items in your cluster, you basically have a closed loop of creating those transforms - even though creating an enrich policy is still a manual task and you would need to trigger it via a cronjob.
Running on your up-to-date order items data could also take returns into account, so that you ignore those when products are often returned in combination with another product (maybe the two don’t fit well).
There are some limitations to the current approach. First, there is no possibility to chain transforms, running one after the other, so that once you need to trigger the enrich policy, you can be sure you are running on the most up-to-date data. Second, as already mentioned, you would need a cronjob to trigger the policy enrichment.
One more thing: This approach assumes that the products index is updated
often, otherwise those recommendations would not get updated and a query to
the product-recommendations index is more efficient. Keep in mind, that
even with a single transform we are already at the stage of retrieving
recommendations via a query.
Hope this helps you to get an idea, what else you could possibly do with transforms in order extend your own data.
Many common examples talk about web server logs (and creating summarizing sessions), but transforms - especially multi staged ones - are much more powerful and will probably surface information in your data you were not aware of.
Happy transforming!
Resources
- Elasticsearch Docs: Transforming data
- Elasticsearch Docs: Enrich data Example
- Elasticsearch Docs: Transform stats
- Mark Harwood about Entity Centric Indexing, video, slides. Helps to understand what problems is tried to be solved, even though this is from 2015
- Kaggle Ecommerce Data set
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so and append to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!