 Alexander Reelsen
Alexander ReelsenElasticCC platform - Part 1 - Application structure
TLDR; This is a series of blog posts x-raying the platform we used to run the Elastic Community Conference 2022 including choices of the platform, technologies and persistence options chosen as well as monitoring and APM capabilities.
In this series we will cover
- Part 1: Application structure
- Part 2: Using the new Elasticsearch Java Client
- Part 3: Upgrading on k8s without downtime
Technologies used
There are a few conference platforms out there, allowing you to organize, prepare and run conferences. Many of those mainly focus on the event registration and execution like providing a stream. However all of those are hard to customize. Trying to use custom login capabilities - like using Elastic Cloud in our use-case - or having certain features like a customizable agenda that can be linked to instead of being only available client side rendering are less seen features. Also some of those platforms have a hefty price tag.
After prototyping around I came up with a small and light java web application helping us to run our platform before and during the conference. A couple of required features
- Registration via that platform
- Show schedule
- Create a customized schedule
- Rate sessions
- Take quizzes
Some non functional requirements
- Low latency and fast rendering: If I need more than 100ms to gather data we’ve done it wrong and should rethink
- Use latest java technologies like Java 17, records and ZGC
- All the java devs in our team should have an easy time adding/removing features
Javalin
Javalin is a well known web framework in the Java space. However well known means it’s absolutely niche compared to the dominating behemoth of Spring Boot. If I needed to create a java application where a team of engineers is working on, Spring Boot is probably a good idea because from an economical perspective getting up and running and being experienced with Spring Boot already might help a lot.
Why Javalin?
There was a tweet just a few days ago asking
Is @springboot still considered as magic by anyone or has it already become a default and understood level of abstraction?
I guess it depends on the definition of magic. Sure it is well tested, but the reflection is still hard to debug for me - which I probably should not do. In any case, check out the thread on the tweet above.
That said, Javalin starts up on my oldish 2017 macbook in less than 120ms. That’s what fuels my developer productivity. Testing is fast as well as application startup. The code can fully be step debugged through in the IDE if needed.
For Javalin I have one big App class, where I read my configuration file,
initialize an Elasticsearch client, services SAML setup and everything else,
making it very readable for me. Few nice helpers to me are in the following
paragraphs.
Javalin - Secure default headers
The OWASP secure headers projects has a list of HTTP headers that increase security. Some time back I created a PR for Javalin to easily add those for every request.
Javalin app = Javalin.create(cfg -> {
cfg.globalHeaders(() -> {
Headers headers = new Headers();
// tell the client to always use HTTPS
headers.strictTransportSecurity(Duration.ofDays(1), false);
// no frame embedding, superceded by frame-ancestors, CSP
headers.xFrameOptions(Headers.XFrameOptions.DENY);
// prevent browser mime sniffing
headers.xContentTypeOptionsNoSniff();
headers.contentSecurityPolicy("frame-ancestors 'self'; script-src 'self' ... 'unsafe-inline'");
return headers;
});
});
Javalin - Rendering using jte
I already mentioned that speed is paramount to me, even when running in slower or shared environments. Some time ago I stumbled over jte, a fast template language. Check out the performance comparisons in the github repo. However one of my favorite features is the compilation of templates and the required definition of types in the templates, so that I have auto completion within my templates.
With the gradle build plugin I can also precompile the templates, so that this does not need to be done on startup of the JVM. The code to load the precompiled template engine code looked like this:
if (isProduction()) {
TemplateEngine templateEngine = TemplateEngine.createPrecompiled(Paths.get("/jte-classes"), gg.jte.ContentType.Html);
JavalinJte.configure(templateEngine);
}
The ensures that templates can be reloaded while developing - this becomes even more important when using htmx and hyperscript later on.
The isProduction() method is used across the application - however as few
times as possible, i.e. when deciding if this is a prod/dev environment for
APM logging or whether the full stack trace should be rendered within a HTML
response or only logged.
@if(configuration.isProduction() == false)
<h2 class="text-xl text-red-500">Message: ${exception.getMessage()}</h2>
<pre><code>${stack_trace}</code></pre>
@else
<p>If this is a permanent error, ping us at community@elastic.co anytime!</p>
@endif
Another nice feature of Javalin is the baseModelFunction, that allows to
insert certain variables in every rendering without specifying them as part
of the template rendering. This way things like the configuration or the
current APM transaction are always available:
JavalinRenderer.baseModelFunction = ctx -> {
Map<String, Object> data = new HashMap<>(4);
data.put("user", ctx.sessionAttribute("user"));
data.put("csrfToken", ctx.sessionAttribute("pac4jCsrfToken"));
data.put("configuration", ctx.appAttribute("configuration"));
data.put("transaction", ElasticApm.currentTransaction());
return data;
};
Quiz: Why haven’t I gone with Map.of() in the code snippet?
Map.of() does not allow null values.
Javalin - JSON or text logging?
Well, why not both? JSON for production and text logging when running things
local? All you need is a check for an environment variable in your log4j2.xml
<Configuration>
<!--
small hack to allow for text or JSON based loggers with an environment variable
defaults to JSON by default
setting LOGGING_FORMAT="text" will return text based logging for local development
-->
<Properties>
<Property name="appenderToUse">console_${sys:LOGGING_FORMAT:-json}</Property>
</Properties>
<Appenders>
<Console name="console_text" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd'Z'HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
<Console name="console_json" target="SYSTEM_OUT">
<EcsLayout serviceName="my-app" />
</Console>
</Appenders>
<Loggers>
<Logger name="org.elasticsearch.client.RestClient" level="WARN"/>
<Root level="info">
<AppenderRef ref="${appenderToUse}"/>
</Root>
</Loggers>
</Configuration>
Javalin - ECS request logging
The Elastic Common
Schema defines
a common set of fields when storing event data in Elasticsearch. In Javalin
you can log every request using a RequestLogger.
Javalin app = Javalin.create(cfg -> {
cfg.requestLogger(new EcsRequestLogger(logger));
});
This request logger uses log4j2’s StringMapMessage to create a mapping of keys which roughly fits the ECS schema, so I can search for it, once that data is indexed into Elasticsearch.
public class EcsRequestLogger implements RequestLogger {
public static final String DEFAULT_PATTERN = "^/(favicon.ico|liveness/.*)$";
private final Logger logger;
private final Pattern ignorePattern;
public EcsRequestLogger(Logger logger, String ignoreRegex) {
this.logger = logger;
this.ignorePattern = Pattern.compile(ignoreRegex);
}
@Override
public void handle(@NotNull Context ctx, @NotNull Float executionTimeMs) throws Exception {
final String path = ctx.path();
if (ignorePattern.matcher(path).matches()) {
return;
}
final StringMapMessage message = new StringMapMessage()
.with("message", "processed http request")
.with("http.request.method", ctx.method())
.with("url.full", ctx.fullUrl())
.with("url.path", path)
.with("url.matched_path", ctx.matchedPath())
.with("event.duration",
Float.valueOf(executionTimeMs * 1000000).longValue())
.with("event.duration_in_ms", executionTimeMs)
.with("event.kind", "event")
.with("http.response.status_code", ctx.status());
// cannot use ctx.sessionAttribute() as this tries
// to create a session if it has not been
// and throws an exception as we're already done with the request
final HttpSession session = ctx.req.getSession(false);
if (session != null && session.getAttribute("user") instanceof User user) {
message.with("url.username", user.getUsername());
}
final String userAgent = ctx.userAgent();
if (userAgent != null) {
message.with("user.agent_original", ctx.userAgent());
}
if (ctx.queryString() != null) {
message.with("query_string", ctx.queryString());
}
logger.info(message);
}
}
There is a small addition to not log super common requests like the favicon or the URL that the k8s cluster uses for liveness checks. There are also some extra checks for optional fields like the query string, the user agent and if the user is logged in.
The result is an output like this:
{
"@timestamp": "2022-02-23T13:39:36.856Z",
"log.level": "INFO",
"event.duration": 4553461,
"event.duration_in_ms": 4.553461,
"event.kind": "event",
"http.request.method": "GET",
"http.response.status_code": 200,
"message": "processed http request",
"url.full": "http://localhost:8080/static/favicon/manifest.webmanifest",
"url.matched_path": "/static/*",
"url.path": "/static/favicon/manifest.webmanifest",
"user.agent_original": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36",
"ecs.version": "1.2.0",
"service.name": "my-app",
"event.dataset": "my-app",
"process.thread.name": "JettyServerThreadPool-51",
"log.logger": "co.elastic.community.App"
}
Alternatively you can also take a look at the ecs-logging-java implementations.
Using the sessionize.com API as backend
How to store your data? I am highly biased and tend to think about everything in terms of Elasticsearch - but sometimes this is not even necessary.
As we ran our CfP via sessionize.com and figured out they have a decent API endpoint plus the ability for customization via additional fields, we just resorted to polling this API endpoint on startup and retrieve all the data about the sessions that had been accepted. This way we could easily display the schedule and sort.
A service polled every 10 minutes in the background for new data and updated its internal representation. This way rendering the schedule or the information about a speaker became an in memory event. With less than 150 sessions and speakers in total there was no need to think about any memory issues either.
Looking at this via the Elastic APM service map showed the following:

Performance was great. Showing the /schedule endpoint here:
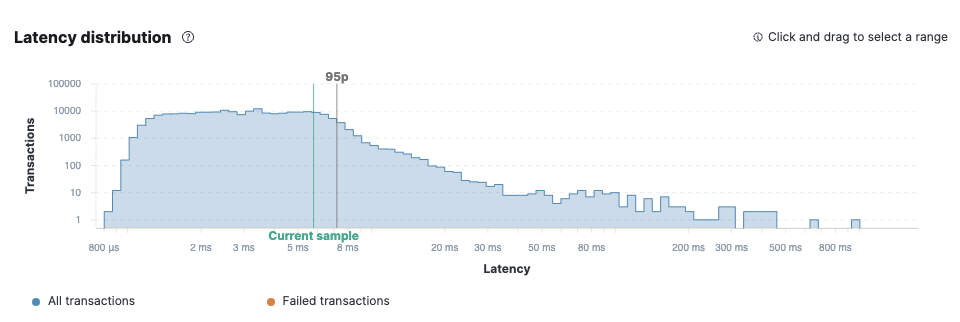
Checking the Latency it was 3.8ms on average, 99th percentile was 8.2ms.
However that API is read only and there is definitely data that requires to be stored like registrations or session ratings. So for that we went - surprise - with Elasticsearch.
You can see one of the longer running request, that took 94ms. First, it queries Elasticsearch, second it seems to take a lot of time after the rendering - it’s not possible to tell where the 60ms actually went.
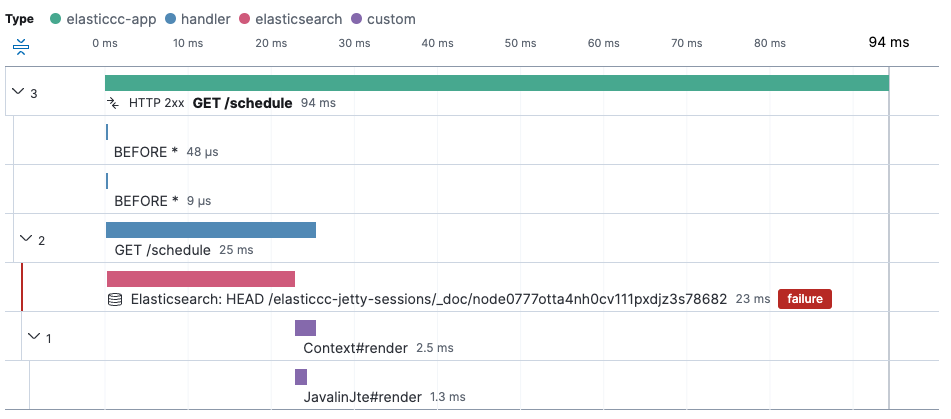
Using Elasticsearch as a data store
Using Elasticsearch was not only done for the sake of it, but also features two reasons. First, running an Elastic Cloud cluster yourself in production and feel the software as a service yourself is something I consider highly important - just like keep trying out your competitors.
Second, with the new Elasticsearch Java Client being freshly released there was another piece of software that I wanted to give a go to make sure I understood its pros and contras.
The application features four Elasticsearch indices
userscontaining users who logged in via the applicationratingscontaining ratings for sessionsquiz-answerscontaining answers for quizzesjetty-sessionscontaining session data for logged in users, so that the application could be rebooted, but the state could be restored
We will cover more of Elasticsearch usage in the next posts.
Login via Elastic Cloud
This was a crucial feature from our perspective. I implemented this in another spring boot based app two years ago already and was pleasantly surprised how easy it was with Spring Security to get up and running.
But, what if you’re not using Spring and Spring Boot? Turns out, there is basically a defacto standard for this already outside of the spring universe: pac4j. Pac4j is a generic authentication and authorization library available for more than a dozen frameworks. One of those frameworks is Javalin and one of those authentication mechanisms is SAML: so everything we got. javalin-pac4j features a full set of examples, that you can use to get started.
I am only halfway happy with the implementation, as the configuration is
spread among several files: The configuration file above, the
dev-metadata-elastic-cloud.xml file containing the EntityDescriptor and
the X509 cert plus the saml-cert.jks file that needed manual creation
first. However I got it up and running and deemed it good enough for now.
All in all the spring security integration feels sleeker, as I have another
Spring Boot app running in production.
This is how the flow looks like in the app
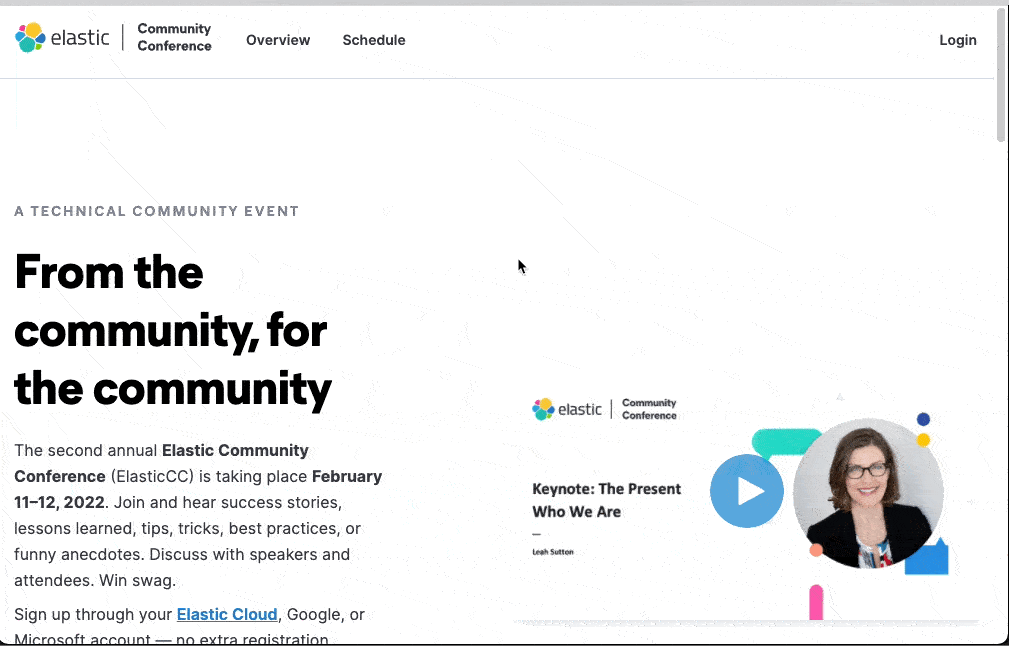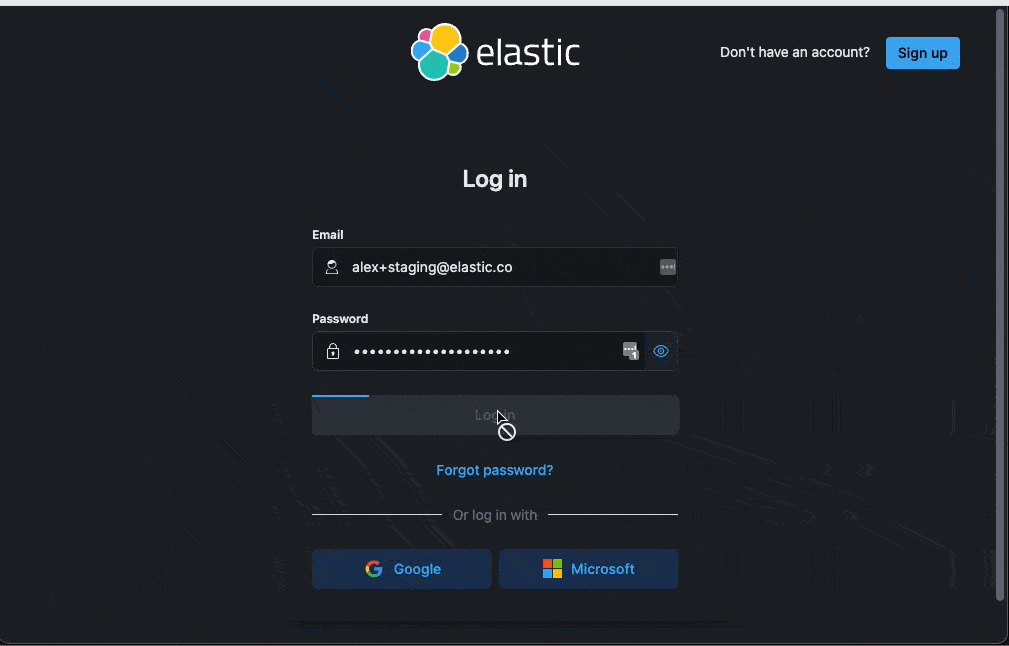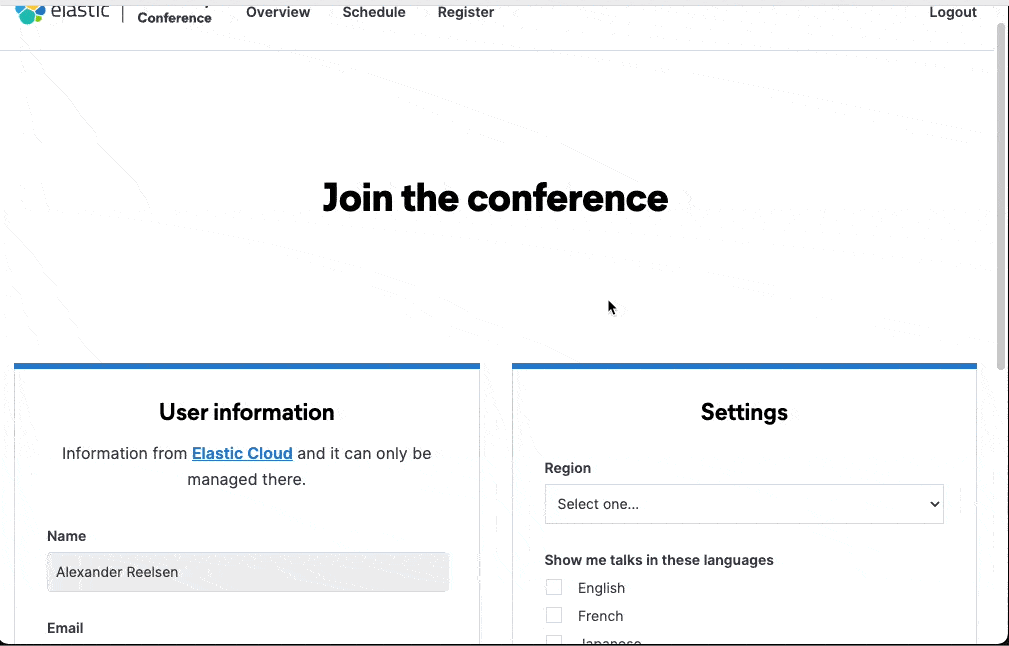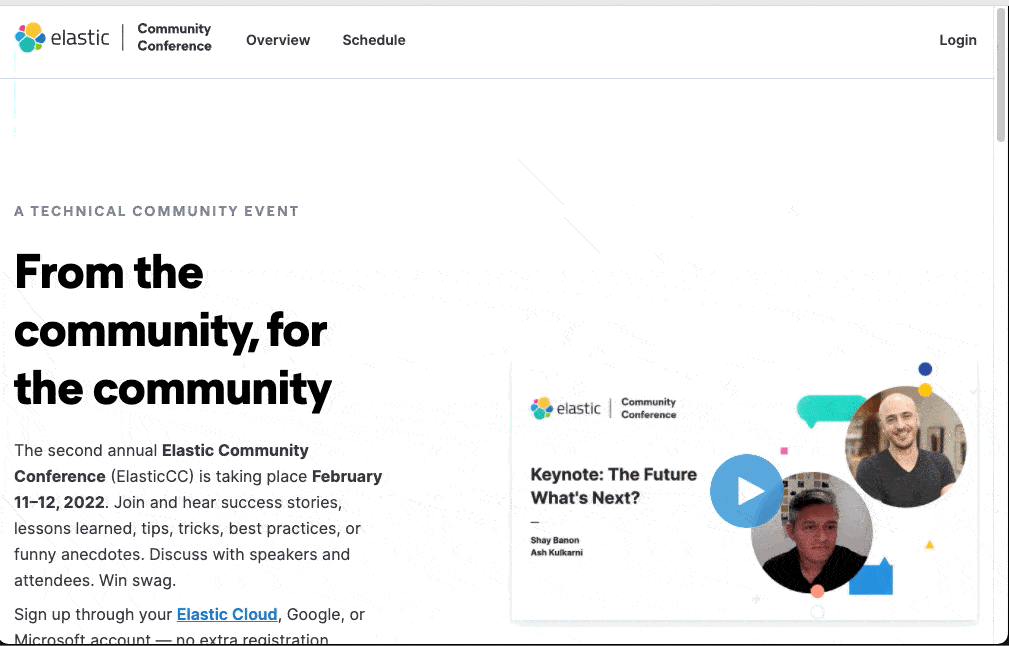
Now the last step is to extract the Elastic Cloud user out of the session attributes of the request and use it, whenever you want to check if a user is logged in:
app.after("/my-login-endpoint", ctx -> {
User user = ctx.sessionAttribute("user");
if (user == null) {
final Optional<SAML2Profile> profile = new ProfileManager(
new JavalinWebContext(ctx),
JEESessionStore.INSTANCE).getProfile(SAML2Profile.class);
if (profile.isEmpty()) {
logger.error("No SAML2Profile after logging in via Elastic Cloud");
return;
}
SAML2Profile saml2Profile = profile.get();
String firstName = saml2Profile.extractAttributeValues("user.firstName").get(0);
String lastName = saml2Profile.extractAttributeValues("user.lastName").get(0);
// persist user via userService and in session...
User user = new User(lastName, firstName);
userService.save(user);
ctx.sessionAttribute("user", user);
}
});
Feature flags via configuration file
In order to ease reading different configurations between development and prod I went with the lightbend/typesafe config library, which had some nice features I could make use of right in the next chapter.
This is what the configuration file named my-application.conf looked like
# development SAML profile, for localhost authentication
dev.saml {
...
}
# production profile
prod.saml {
...
}
# feature flag for showing the schedule
prod.features {
show-schedule = true
show-custom-schedule = false
show-quiz = false
show-rating = false
}
dev.features {
show-schedule = true
show-custom-schedule = true
show-rating = true
show-quiz = true
}
# Elasticsearch configuration, defaults to localhost, and falls
# back to the environment variable if available
elasticsearch {
host = "http://localhost:9200"
host = ${?ELASTICSEARCH_HOST}
user = ${?ELASTICSEARCH_USER}
password = ${?ELASTICSEARCH_PASSWORD}
}
There are a few differently configured features based on the prod or dev
profile, so we could try out things while testing locally, before rolling it
out in production.
One nice feature can be seen in the elasticsearch section, where the host
defaults to localhost:9200 unless specified in an environment variable.
This was super useful, as in production we could just set that environment variable
together with the user/password.
In order to read the above file I am using a Configuration class
public class Configuration {
private final Config config;
private final boolean isProduction;
public Configuration(boolean isProduction) {
this.isProduction = isProduction;
final Config global = ConfigFactory.load("my-application.conf");
this.config = global.getConfig(isProduction ? "prod" : "dev")
.withFallback(global);
}
// SAML config parsing
// Elasticsearch config parsing
public Features features() {
return new Features(config.getConfig("features"));
}
public record Features(Config features) {
public boolean enableSchedule() {
return features.getBoolean("show-schedule");
}
public boolean enableCustomSchedule() {
return features.getBoolean("show-custom-schedule");
}
public boolean enableRating() {
return features.getBoolean("show-rating");
}
public boolean enableQuiz() {
return features.getBoolean("show-quiz");
}
}
}
The most interesting part is the last part of the constructor, which prefers
profile configurations like prod or dev, and if those are not set uses
defaults.
While probably not the best spot to create classes from that Configuration, I created the Elasticsearch client right within the configuration class, so I don’t have to expose single settings somewhere.
public record Elasticsearch(Config elasticsearch) {
public ElasticsearchClient toElasticsearchClient() {
final RestClientBuilder builder = RestClient.builder(
HttpHost.create(elasticsearch.getString("host")));
if (elasticsearch.hasPath("user") && elasticsearch.hasPath("password")) {
// ... create Basic Auth CredentialsProvider
builder.setHttpClientConfigCallback(
b -> b.setDefaultCredentialsProvider(credentialsProvider));
}
RestClient restClient = builder.build();
ElasticsearchTransport transport = new RestClientTransport(restClient,
new JacksonJsonpMapper(mapper));
return new ElasticsearchClient(transport);
}
}
Also using the configuration class or parts of it can be done in
templates:
@if(configuration.features().enableSchedule())
<nav role="navigation">
<a href="/schedule" class="nav-link-text w-nav-link">Schedule</a>
</nav>
@endif
Or in Java code
if (configuration.features().enableSchedule()) {
SpeakerController speakerController = new SpeakerController(sessionService);
// ...
}
Docker image creation & build
There are a few important tidbits when creating the docker images
- Use certain java options
- Precompile templates
- Have a multilayered image, so that dependencies are in their own part compared to the application code. This reduces the number of bytes required to push when no dependencies are updated (which is the majority of the times)
gradle has a fantastic application plugin, that allows to build a
distribution consisting of all the jars as well as the project code, plus
shell scripts to start the application. All you have to do is to run
./gradlew installDist and you will end up with a
./build/install/app-name/bin directory containing shell scripts and a
./build/install/app-name/lib directory containing all the libraries.
The trick was to have three separate tasks to copy dependencies, scripts and own code:
task copyDepsToLib(type: Copy) {
from configurations.runtimeClasspath
into "$installDist.destinationDir/lib"
}
task copyAppToLib(type: Copy) {
dependsOn(jar)
from jar.destinationDirectory
into "$installDist.destinationDir/app"
}
task copyStartScriptsToBin(type: Copy) {
dependsOn(startScripts)
from startScripts.outputDir
into "$installDist.destinationDir/bin"
}
Call those in your Docker file
FROM gradle:7.4-jdk17 AS build
COPY --chown=gradle:gradle . /home/gradle/src
WORKDIR /home/gradle/src
RUN gradle clean --no-daemon
RUN gradle copyDepsToLib --no-daemon
RUN gradle check --no-daemon
RUN gradle precompileJte --no-daemon
RUN gradle copyStartScriptsToBin --no-daemon
RUN gradle copyAppToLib --no-daemon
###############
FROM --platform=linux/amd64 openjdk:17.0.2-slim-bullseye
RUN addgroup --system elasticcc && adduser --system elasticcc --ingroup elasticcc
USER elasticcc:elasticcc
WORKDIR /my-app
COPY --from=build /home/gradle/src/build/install/my-app/lib \
/my-app/install/my-app/lib
COPY --from=build /home/gradle/src/src/main/resources/ \
/my-app/src/main/resources
COPY --from=build /home/gradle/src/build/install/my-app/bin \
/my-app/install/my-app/bin
COPY --from=build /home/gradle/src/jte-classes/ \
/jte-classes
COPY --from=build /home/gradle/src/build/install/my-app/app \
/my-app/install/my-app/lib
EXPOSE 8080
ENTRYPOINT [ "/my-app/install/my-app/bin/my-app" ]
This also means, there is an entry point ready to be run. Because this is built into
gradle via the application plugin, setting JVM options also is a breeze
and is also applied when running those start scripts outside of docker.
This is also a good position to add a JVM agent, if you do not attach it
programmatically.
def jvmOptions = [ "-XX:+UseZGC", "-Xmx768m" ]
startScripts {
defaultJvmOpts = jvmOptions
}
There is even a custom environment variable to set JVM options just for your application, instead for all applications on that node, if needed.
Testing
Before we dive into testing, let’s take a look at the used dependencies to give you a first impressions
testImplementation 'nl.jqno.equalsverifier:equalsverifier:3.9'
testImplementation "io.javalin:javalin-testtools:${javalinVersion}"
testImplementation 'org.assertj:assertj-core:3.22.0'
testImplementation 'org.mockito:mockito-core:4.3.1'
testImplementation 'org.testcontainers:elasticsearch:1.16.3'
testImplementation "org.junit.jupiter:junit-jupiter-api:${junitVersion}"
testRuntimeOnly "org.junit.jupiter:junit-jupiter-engine:${junitVersion}"
Let’s take a look at the lesser known ones.
equalsverifier ensures that equals()
and hashCode methods are correctly implemented. As most of my classes are
records, that’s rather simple, but still, you want to be sure if that is not
the case.
A simple test looks like this
@Test
public void testEqualsVerifier() {
EqualsVerifier.forClass(User.class)
.suppress(Warning.STRICT_INHERITANCE, Warning.NONFINAL_FIELDS)
.verify();
EqualsVerifier.forClass(Rating.class).verify();
EqualsVerifier.forClass(QuizAnswer.class).verify();
EqualsVerifier.forClass(QuizQuestion.class).verify();
EqualsVerifier.forClass(QuizQuestionAnswer.class).verify();
}
Not much to say about assertJ, except that I wrote some custom asserts for template rendering to check if certain variables are in the passed map and I am always happy to see how readable and expressive assertJ is, one of my favorite libraries within the JVM ecosystem.
class ExceptionHandlerControllerTests {
private final Logger logger = mock(Logger.class);
private final Context ctx = mock(Context.class);
private final RuntimeException e = new RuntimeException("this is a test");
@Test
public void testStackTraceIsCreatedInDevelopmentMode() {
ExceptionHandlerController handler =
new ExceptionHandlerController(new Configuration(false), logger);
handler.handle(e, ctx);
assertThat(ctx).hasRenderTemplate("error").renderMap()
.containsEntry("exception", e)
.containsKey("stack_trace");
}
}
There is one specialty regarding Testcontainers. As I want to run unit tests when creating the docker image. Likely not best practice, but a best practice for my sleep. However you have to differentiate between unit tests and tests using Testcontainers in that case to prevent running docker in docker containers.
def testReporter = { desc, result ->
if (!desc.parent) {
def duration = java.time.Duration.ofMillis(result.endTime - result.startTime)
println "\nTest summary: ${result.resultType}, ${result.testCount} tests, " +
"${result.successfulTestCount} succeeded, " +
"${result.failedTestCount} failed, " +
"${result.skippedTestCount} skipped, took ${duration}"
}
}
tasks.named('test') {
useJUnitPlatform {
excludeTags 'slow'
}
afterSuite testReporter
}
task integrationTest(type: Test) {
useJUnitPlatform {
includeTags 'slow'
}
afterSuite testReporter
}
The test reporter is just a small helper for me to see the test result runs like this:
Test summary: SUCCESS, 86 tests, 86 succeeded, 0 failed, 0 skipped, took PT6.19S
The more interesting part are the exclusion and inclusion of certain jUnit
tags. By only including slow tests when running ./gradlew integrationTest
I declare a Testcontainers test like this using the @Tag annotation:
@Tag("slow")
@Execution(ExecutionMode.SAME_THREAD)
public class MyElasticsearchContainerTest {
}
This way I can differentiate between unit and integration tests (if there is anything built into gradle that I might have missed, feel free to give me a ping).
Summary
We covered quite a bit in here, with lots of examples across code and gradle and I hope you you could make some sense out of this and just use something for your own projects. Don’t worry, we’re not finished yet and will cover much more over the next posts.
Next up we will cover the new Elasticsearch Java Client.
Resources
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so and append to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!