 Alexander Reelsen
Alexander ReelsenThe new generation of data stores
TLDR; This blog post takes a look at the new generation of data stores, that are tied to cloud technologies and thus have a different architecture than those written a decade ago.
Intro
Most data stores operate either at the user’s data center, which was pretty normal some years ago, or on something like an EC2 instance on your cloud provider of choice, sometimes hidden behind some service.
When writing applications in the cloud™️, everyone was always told, that you should utilize the different technologies (queues like SQS or SNS, memory caches like a hosted Redis or execution environments like AWS Lambda) of your cloud provider to really cut costs, instead of just moving over your workloads to the cloud provider (aka lift and shift). For storing data your cloud providers usually had a hosted service as well, that you were supposed to use. When doing the classic migration, you just moved everything to a cloud provider. When being modern, one used the cloud provider k8s infrastructure to spin up services within such a cluster. When modernizing applications, just switch to cloud provider services - and probably enjoy a wee bit of vendor lock-in plus some saved some money in the best case. This was applicable to applications only though.
But what about the data stores? Most of those were either run by yourself with all the administrative overhead, or run by your cloud provider, potentially being an outdated fork or not the version you are after.
Data stores have long stayed away from the cloud native shift. This has changed dramatically in the last two years, and this blog post will shed a little light of what this means in terms of implementations.
The let’s enter the new generation of data stores.
The old school architecture
Let’s take a look at existing architectures. Two systems I have some experience with are Postgres and Elasticsearch, so I may use those as an example.
Postgres is almost a de-facto standard of a SQL database, labeling
itself as the world’s most advanced open source relational database
- turning 25 years old this year. I find it
utterly impressive how it keeps being up-to-date with technology trends:
Never cutting edge, always keeping up. Asynchronous IO, now io_uring -
the current strategy is to improve utilization on a single
node - which is
a really good strategy. You can scale up Postgres to a LOT of data and its
core architecture was always meant to have the data right next to the system
in order to have fast reads and writes in combination with
transactions/visibility.
Postgres is extensible. Not only you can have different kinds of indices (like inverted indices, block ranges or kNN indices) but you have a standardized way of extending Postgres: the foreign data wrapper (FDW), allowing you to have an interface for generic data retrieval. Someone on hackernews used an FDW to call AWS Lambda to query data from S3 backed SQLite indices to model a data warehouse - what an awesome idea.
There are also more ’normal’ extensions like integrating Elasticsearch and Postgres via ZomboDB. Everything is done on a single node when it comes to writing and reading of data, as running transactions and keeping constraints are much easier to write code for. No coordination required.
Elasticsearch is an extensible system (custom queries, aggregations, data types) that on top is natively distributed. Elasticsearch stores data somewhere in a cluster, plus the configured copies and as a user you don’t have to care where this data is. You connect to any node within the cluster and the cluster figures out the rest - primarily where to route this request.
If you index a new document, it is first indexed on the primary shard. If that was successful the document is indexed on all copies of a shard - the user can configure how many that should be. The way Elasticsearch works is, that the same work that has already been done on the primary shard is repeated on the replica. So you are doing the same work as many times as you have shard copies in your cluster. If you index 100k documents per second with two copies, you’re factually indexing 300k documents per second. That is a lot of duplicate work. However this was necessary many years ago because of nodes and their local hard disks possibly failing to ensure availability/durability of your data on potentially failing commodity hardware. The same reason existed for a replication/follower strategy on SQL databases.
One problem of having index and query functionality on a single system is the ongoing battle of competing resources. If there is a huge amount of data constantly written, than executing queries may be limited because of resources required for writing. With regards to IO things got much better since SSDs, but the basic issue still remains.
Many data stores also make trade offs of optimizing the data for one happy path, be it reading or writing. This means you cannot do in-place updates or deletes and thus need to create new write-once data structures and also expunge deletes over time from older data. Apache Lucene (used by Elasticsearch) has the notion of segments, which are immutable, but thus have a clean up process, that makes sure to remove data marked as deleted or changed over time (called merging).
Note, that this is no criticism of a particular data store. As a user it’s your obligation to understand such trade offs and make sure this either fits in your architecture or probably rethink the usage of your data store.
So, how do can data stores solve these issues? Imagine being able to write
300k different documents per second with Elasticsearch due to not needing
replicas (and saving a fair share of money or having a much smaller
cluster). This is where it gets buzzwordy. You may have heard of splitting storage and compute layer as this is all the rage. What this often means is
making use of cloud technologies that were not as stable as they are today,
when most storage systems was written.
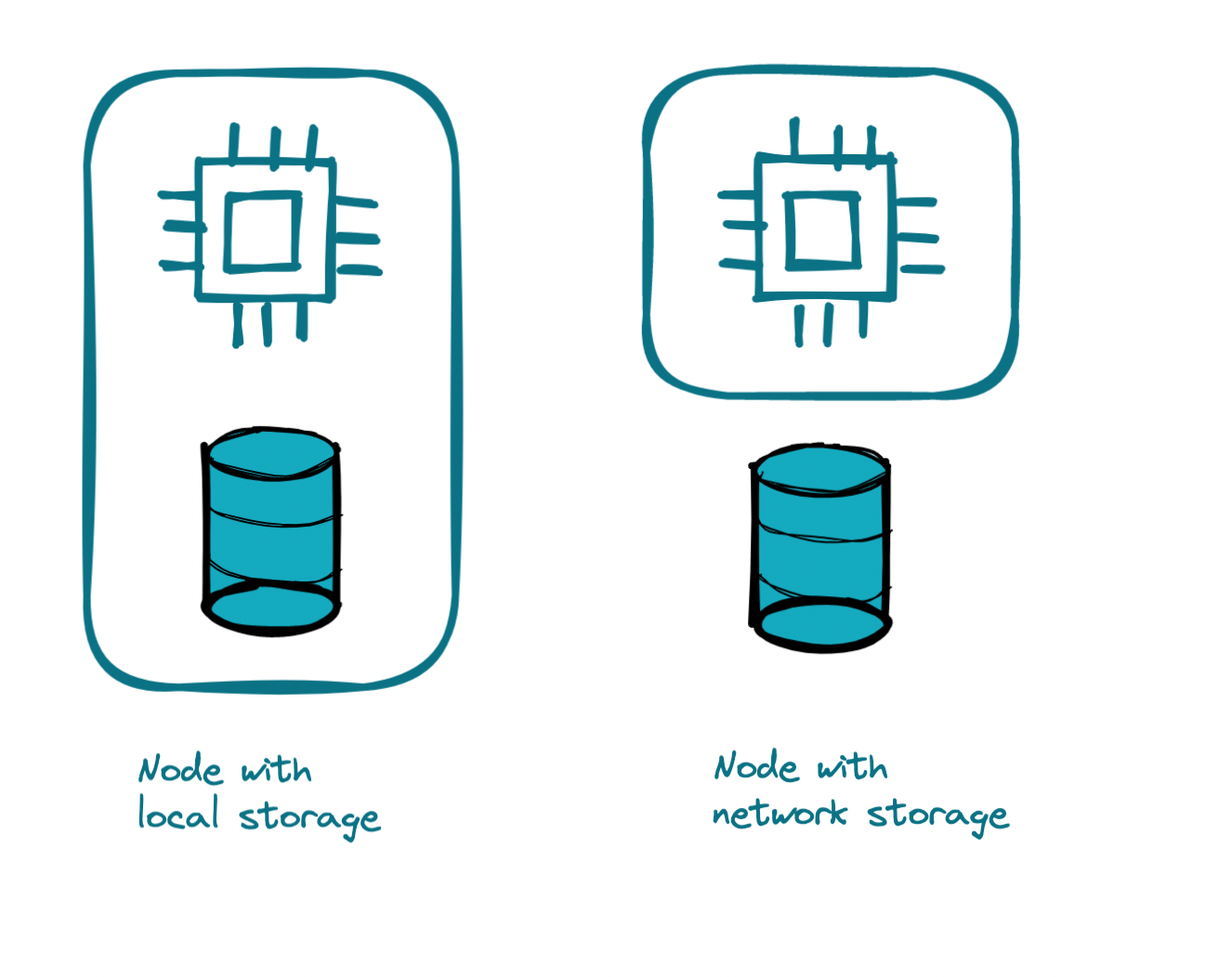
Old school architecture
Just to finally illustrate that from a storage perspective: These two architectures were most common, as local storage used to be the fastest and networked storage at some point was an architectural choice, where application developers sometimes did not have a choice :-)
Why this there a shift now?
This leads to the question, why is there a new generation of storage systems, that do things differently than a standard Postgres or MySQL data store? Economies of scale resulting in lower cost due to requiring less resources. This is also why this is driven so hard by the big cloud providers. Running millions of small to medium data stores holding little data, that even a small instance would result in a major overprovisioning, is an expensive endeavor for any cloud provider.
One of the solutions to overcome this is to heavily use the own cloud infrastructure. Aurora Serverless on AWS and recently AlloyDB on GCP are natural results of trying hard to reduce running compute resources. It’s natural that the big cloud providers are on the forefront for this for general purpose data stores.
Whatever happens in Google, AWS or Azure will usually happen to other data stores a little later. CockroachDB is a good example of a data store created by former google employees - albeit it is tackling a different problem by making sure data is distributed and not yet about saving costs. CockroachDB it’s also a lot older than this recent trend.
However this time the next big move of databases is reducing required resources - potentially on top of being distributed.
Another important point is the change of infrastructure. If you look at k8s being a data center as a service, then this already happening there, as storage is treated separately from compute, when you configure a service.
So, what does it mean from a data store perspective to split storage and compute in data stores?
The split between storage and compute
Let’s tackle the storage part first, as there is a fair share of systems that have done this step already. First, this absolutely will not simplify application architecture, but make it more complex. That’s also a reason why adding this in retrospect is quite the journey - yet a lot of data stores will go that route, especially if they have their own as-a-service offering.
Let’s take a look at storage at cloud providers. There are so many options now at AWS: S3, EFS, storage on EC2 instances, it’s already hard to pick, and even harder to abstract the different implementations away in your own implementations.
However, some of those implementations already bring a few features, that do not need to be implemented (on commodity hardware). Take a look at S3 for example: data is being considered highly durable by default, which means there is likely no need to write data more than once if you are using S3 as data storage. Imagine getting rid of all replication code in your application. Sounds appealing, eh - thank you for noticing that exaggeration, but I hope you get the point of simplification here.
This comes at a cost. Access to many of those storage options might take a little longer being a networked file system and might cost money on top. This means you have to rethink your data structures. If you need to seek and do in-place updates, this might be more expensive then marking a document as deleted and removing it as a batch operation later with many other documents. Also a full table scan might now cost a bit of money, and thus adapting your data structures for minimal access is not only interesting CS problem for nerds, but a cost saving strategy.
There is a fantastic blog post about Husky, the new system used within Datadog to store data, which also lists a trade off, that may not be acceptable for some users, but was in this case
We ultimately decided that a few hundred milliseconds increase in the median latency was the right decision for our customers to save seconds, tens of seconds, and hundreds of seconds of p95/p99/max latency, respectively.
Also there are some systems, where using this kind of storage is more complex, because you also have to read data, when writing to ensure consistency guarantees. Observability data like in the case of Datadog is usually an append-only use-case (that may need additional sorting based on timestamp later on).
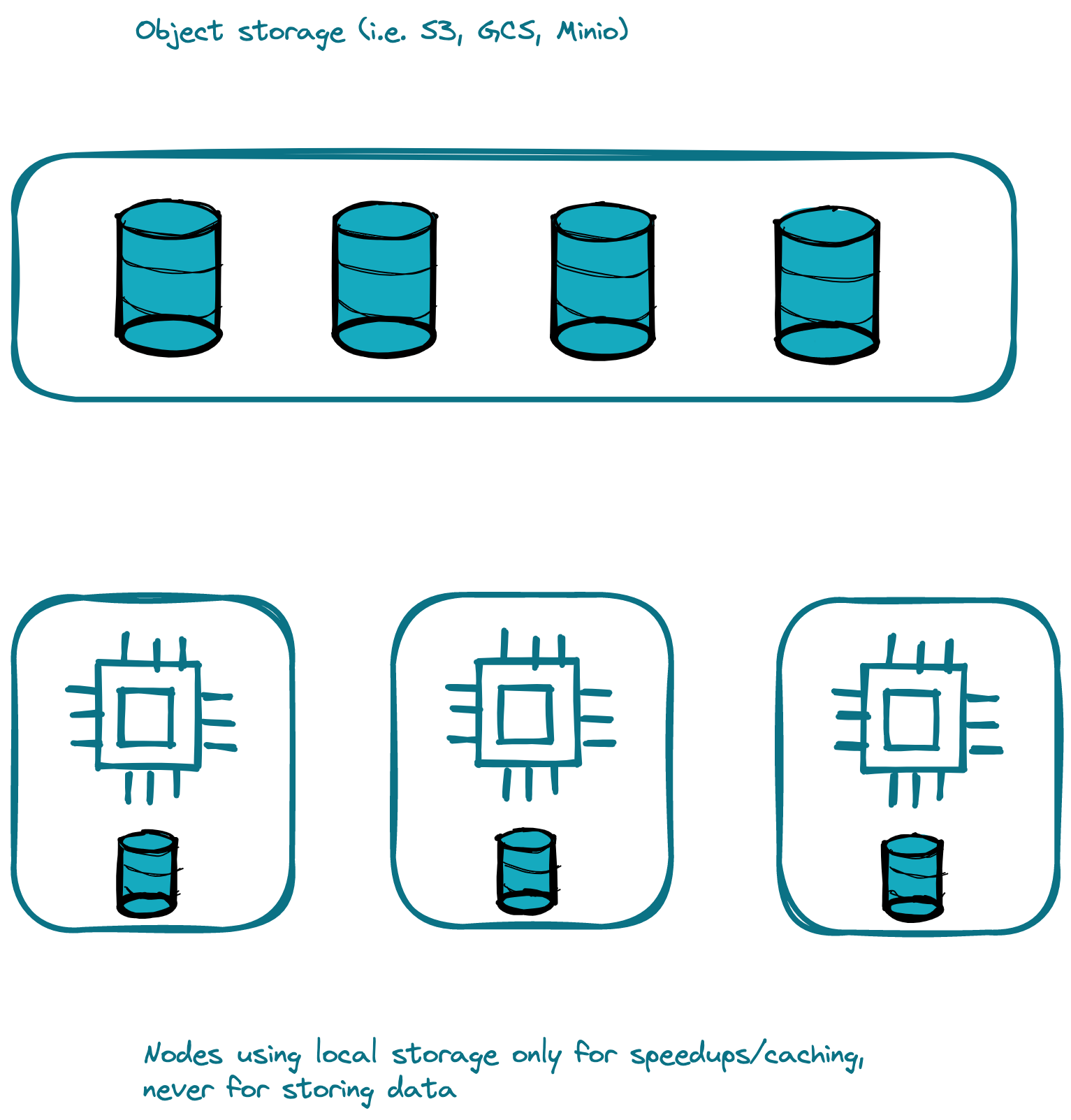
Storage and compute split
Just to make sure, the above is a gross simplification, that many data stores will not be able to hold this way due to consistency guarantees, but let’s stick with that as an example.
Compute - Home alone
Once you have the storage separated from the system writing your data, everything CPU intensive when writing your data is separated from reading and you can have dedicated resources for tasks like enriching your data before writing, including doing expensive look-ups resulting in higher wait times per written document.
Doing this, you get one more nice free feature, and that is the ability to scale out your writes, if coordination allows for this. Think of a data store having an arbitrary amount of configured writers, that can scale up or down based on the current load, and is also doing this automatically, whenever the number of incoming documents increases. Those writers can also be completely shutdown if no write operations happen.
If you can scale your writers, you can probably scale reading data from your data store as well. Again this would allow you to scale up your read to whatever is needed at any point in time, scaling down to 0 if no-one uses that data.
Now the cloud providers have a mechanism to remove any running process if no-one accesses your data, or run lightweight processes when there is no access. That’s cost effective, if your data is only stored when not being used.
Let’s dive into the drawbacks of this.
Now everything is a distributed system
This complicates development. Instead of one big system, where communication can be done within the process or via IPC at most - the new architecture brings all the drawbacks of a network: acknowledgments, unstable networks, timeouts, etc. So you have to have different recovery modes and deal with those failures as well. Everything will be dynamic, adding or removing writers, readers and potentially even storage can happen anytime, there is no such thing as planned downtime.
In the best case you create a stateless system, that does not require any coordination. This is hard. It’s not impossible, but the amount of work is substantially higher.
There is an interesting article about OKLog, a distributed and coordination-free log management system. Neither the post nor the system shown is not about splitting storage and compute, but gives a little bit food for thought in general about trying to get rid of coordination in software.
Outsourcing cleanups/merging
A fair share of data stores does not do in-place updates, as they are expensive and resort to soft deletes, that gets cleaned up at a later point in time. Apache Lucene’s merging is a good example of that. The smallest data structure containing several documents within an index is called a segment, and the process of merging takes several of such segments, removes deleted documents and creates a new segment out of that, which then is made available for search. You could run that merging on a completely different system, and the searching part could switch over to those new segment once it is finished.
Another fictitious example: The VACUUM command in Postgres. No need to run
on the same node, if the storage is somewhere else anyway. At the expense of
proper locking and keeping the WAL available while this is running,
increasing the complexity here.
Smarter query plans
With storage, that has a price attached to every access, the primary goal is make sure the money spent reading or writing is reduced. As every data store comes with a query planner, those can be smarter by automatically adding or removing indices over time by just looking at the queries coming in - you wouldn’t even need ML or AI for that 😀
Another thing that becomes easier is to increase/reduce compute resources based on query response times - if the user has the requirement of halving response times, it would be possible to suggest how much the bigger node would cost to achieve that - that would require the ability to scale based on CPU and/or worker nodes.
Ultimate goal: Assign exact costs to queries and inserts
You may have heard of the wonderful term serverless. You could also say
pay-for-execution, but I guess that sounds less fancy. However, what this
mode of operations allows you when running your own code, is the ability to
exactly calculate what a single operation for a certain user or tenant was
costing you. This is not only interesting for compute only services like AWS
Lambda, but also for data store providers. And this is a common reason
for that storage/compute split: the ability to figure out what a single user
is costing you, adding some premium on top and come up with a good
pricing model. Unfortunately nowadays this is extra ordinarily rare. Often
the costs are made in a way, that getting your data out is getting complex
(egregious egress anyone?).
So there is still a split between the potential ability to figure out an exact cost of a single paying user internally and showing that to the user, because there are still parts that cannot be calculated exactly. How about a cached query on a node, that did not need to fetch anything from the data store not incurring any storage transfer costs. Would you bill this differently to your customers, potentially making your pricing way more complex to explain instead of always billing the same? Or would you just go with an hourly rate of whatever sized instance and be done? This is a tough topic, and I guess there will be a lot of confusion for users across different implementations of that in the future. So don’t bet on that.
The tech stores of the new generation
So, there is a fair share of data stores being only available as a Service and those that can be run locally and are optionally Open Source. Let’s start with the NoSQL ones.
ClickHouse is an interesting one. Being used by a few of recently developed data warehouses because of it’s architecture and being a column store currently it does not have any serverless capabilities, despite being offered as a serverless service by the company itself. This is probably the SaaS differentiator and we will see over time, if that part moves back into ClickHouse. There are a few modern data warehouses, that at least started as a ClickHouse fork, albeit being changed heavily over time, that already have finished with the split of storage and compute. Firebolt is one of them.
Paul, author of Tantivy and founder of the company named Quickwit is working on an somewhat Elasticsearch compatible API, that indexes and searches data on an object storage. He tweeted after the above mentioned husky blog post, that they are using a similar architecture.
meilisearch is another interesting new search engine, but I do not see any move towards splitting storage and compute so far, as they are still ramping up their cloud service. As meilisearch uses LMDB under the hood, I don’t expect that core library to split storage and compute, so this will be done within meilisearch probably.
QuestDB is a time series database having an SQL frontend, featuring SIMD optimization and vectorized query execution. QuestDB uses memory mapping heavily and currently does not seem to split any storage and compute.
Before having more candidates like QuestDB and meilisearch, let’s shortcut on data stores, where I have not found any information of moving to separation from compute and storage: Cassandra, ScyllaDB and Timescale (there is a post on their HyperTables implementation from 2019, sharding with a time series twist 😀). I have not looked in detail into TiDB, SkySQL or Citus, but assume they are somewhat older already and thus do not have a full split between storage and compute.
Update: Frank Pachot from Yugabyte corrected my wrong assumption above and mentioned via twitter that the storage/compute split is actually in the design with a link to a blog post about YugabyteDB’s Two Layer architecture. Thank you, Frank!
Keep in mind, that the above does not mean, that any of those are repeating the indexing work on all the copies of their data, that was mentioned above. Some systems can copy the data after the work and thus save on CPU - again, looking at each capabilities of each data store is crucial and I really only checked for splitting storage and compute. This is naturally harder to SQL in order to retain ACID guarantees compared to some NoSQL data stores, that just make data available for querying, but do not know the notions of transaction isolation levels.
Cockroach Labs (still one of my favorites with regards to product naming) offers a free tier of their service. There is a reason why many storage providers do not offer a free tier: it is prohibitively expensive. Cockroach however offers a serverless service of their database, which is also free up to a certain storage and compute size (aka number of requests). This is rare! Unless they permanently operate at a significant loss model with hopes of a few customers going big, they found a way to scale to zero, which is my assumption
In fact, we expect most tenants to not need any CPU at all.
Check out Cockroach’s blog post How we built a forever-free serverless SQL database, it’s a great read. However, in total I do not expect that there is a full split of storage and compute, but rather the ability to hibernate a service and ramp it back up if needed - however if up and running, both is tied together.
On top of Postgres there is a new kid on the block and just announced: Neon, a serverless Postgres under Apache License. The claim is
Neon: Serverless Postgres. We separated storage and compute to offer autoscaling, branching, and bottomless storage.
Check out the GitHub repository.
Neon is written in Rust. The
architecture
is dividing between SafeKeepers to ensure durability by delivering a WAL
stream to Pageservers. The Pageservers are responsible for querying and
storing data on cloud object storage. Neon seems to be a really interesting
development on top of Postgres that I will definitely follow. So far, Neon
seems to have focused running on AWS - do not underestimate the complexity
of getting up and running on another major cloud provider.
Firebolt has started out as a ClickHouse fork, but has moved faster into a different direction, especially due to splitting storage and compute. There is a fantastic CMU talk by Benjamin, one of the members of the query team. The decoupling allows to spin up compute resources dynamically, depending how much money you want to spent to solve a data challenge in a certain amount of time.
Yellowbrick is a commercial data warehouse, that I found via another CMU Database Group talk. Yellowbricks used to run on specialized hardware due to performance reasons but now has moved into the cloud. Judging from the talk and their homepage they also seem to have finished the move to split storage and compute already.
Judging from the founders, I also suppose MotherDuck to run in that category, but it’s only been announced recently.
More questions
I tweeted what people expect from a blog post like this and got two answers from Jo from Vespa and Ivan (hi 👋 & thx!). Those contained topics like
- IOPS/bandwidth from remote storage
- Required network
- Autoscaling
- Self-managing & self-balancing
- Performance stability and predictability
- Multi tenancy
- Geo-replication
- New modern paxos
Those are excellent points and would probably each warrant their own blog post. The hard dependency on the cloud provide comes with the trust into the performance numbers that are available - especially if those numbers are consistent under load or just peak numbers. When using smaller instances the fluctuation of the promised performance might change more than your SLA says, so extensive testing is absolutely crucial.
On top of that users of cloud providers are not fully aware of the underlying hardware. Especially with disks this might be tricky, as different SSDs tend to have different write amplifications and garbage collections making it incredibly tough to come up with reliable benchmarks.
What about the hyperscalers and OSS?
I’m glad you asked! I am kinda sure that we will see cloud native data stores heavily utilizing hyperscaler technologies without the hyperscalers offering them as a service. The new generation of data store companies will have different licenses to protect against AWS like Mongo, Elastic, CockroachDB, Graylog, Grafana, Redis and Confluent.
Those are all companies who started with Open Source compatible licenses and then became more strict over time to protect against the hyperscalers.
New data store companies will have SSPL like licenses from the start to not run into this and eliminate potential competition for their own SaaS implementation from the start.
This might also mean less free & open software in the near-term until the hyperscaler money-making problem is resolved, when it comes to splitting storage and compute. For the hyperscalers this is not too much of a problem anyway, because they even earn a lot of money, when those data stores are exclusively working on those. It might just mean another service with a similar but not exact same API in your cloud provider next two the other five-hundred-something.
You may want to read the blog post Righteous, Expedient, Wrong from Kyle Mitchell about the Elastic License in 2021 and also what happened when Mongo tried to submit SSPL for OSI approval.
In addition I do expect that even rather open data stores will have their control plane used for their offering as a service completely closed or even potentially have a different license to their k8s operators to prevent other companies from running their software as a service.
Summary
The biggest shift can currently be seen for data warehouses from my limited perspective. Why? Because the cost savings to run on cloud native infrastructure (and not even offer an on-premise solution) will be massive due to the amounts of data. ClickHouse seems to be a foundation here, as is Postgres.
Will data stores be tied to a single cloud provider or to the big three and you will not have a chance to run your workloads locally anymore? I think so. The move from OSS monetization to SaaS monetization has happened in the last years, and cloud infrastructure basically fuels this - a different kind of vendor lock-in, that also leaves smaller cloud provider like Digital Ocean, Cloudflare, Vultr, OVH, Clever Cloud under pressure. They have to make sure to find their own niche.
The best use-case are probably append-only create-once workloads for this - however those are dying. Everything is becoming real-time and updateable. Even data warehouses - some just relabel this as analytics, as this apparently has to be realtime - amirite?!
Another big differentiator is the definition of real-time. If real-time means, data needs to be accessible after committing a SQL transaction, this will be much harder with a split of storage and compute than saying that it may take up to 30 seconds for data to become available - and then responding to any query is much faster. Ask your users what their acceptable behavior and cost is to make data available for search.
Apache Lucene is a good candidate to split between storage and compute. I do know of a Solr users utilizing this pattern for faster indexing and using S3 to restore snapshots into a live system. Searchable Snapshots from Elasticsearch move into the same direction for querying. Check out the talk from Michael Sokolov and Mike McCandless about E-Commerce search at scale from Berlin Buzzwords talking about segment replication and concurrent searches on a per-segment base to increase concurrency.
Keep in mind that all of this will affect your application development. You will think of splitting storage and compute at that level already.
Some concepts like the split between data and control planes, are valid for application development as well. Those terms would warrant another major blog post, but I usually simplify those in my mind as management component (that needs much less compute and storage resources) and data component.
I hope you enjoyed this ride across data stores. I am sure, there are many facets to discuss. I wrote this during the 40℃ heatwave across Europe, so bear with me regarding typos and repetition.
Resources
I only linked resources, that are not linked somewhere else within the article, but may be worth another read.
- Blog post: Database on Fire: Reflections on Embedding ClickHouse in Firebolt
- Video: The fantastic CMU Database Group YouTube channel
- Documentation: Quickwit Architecture
- Book: Understanding Distributed Systems, a good introduction into distributed systems (not to compare with something like Designing Data-Intensive Applications, but great for beginners)
- Ebook: Postgres 14 Internals
Final remarks
Thanks to Torsten for providing initial feedback to this post - owing you another drink.
If you made it down here, wooow! Thanks for sticking with me. You can follow or ping me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so and append to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!