 Alexander Reelsen
Alexander ReelsenMirror, mirror, what am I typing next? All about search suggestions
TLDR; This blog post takes a look at various techniques for suggestions (aka search as you type aka autosuggest), using different Java libraries like radix trees and Apache Lucene. We’ll deep dive into implementations and differences. Buckle up for a long read!
Intro
This whole article and following research started when I saw How we built the lightning fast autosuggest for otto.de, where Tobias and Tom talk about their implementation using a pruning radix tree, that I had read about it some time ago but forgot again.
As search-as-you-type has always been a challenge when I implemented a search solution in 2010 for a b2b ecommerce marketplace before I joined Elastic, and even wrote an Elasticsearch plugin, it’s always been a topic of interest to me.
Let’s take a look at the different implementation possibilities using Java, and if they are a good or mediocre fit and what is lacking. Speed is crucial for all of them as responses need to be in the low single digit milliseconds if you want to return data while the user is typing.
What is required for good autosuggest?
Let’s talk about the problem domain first. Basically after a user types one or more letters, a search engine should return suggestions helping the user to find data - ideally showing the most relevant results first. It’s so omnipresent in Google, that users often notice how bad such a functionality in other platforms is. For example many ecommerce platforms have a mediocre suggest strategy.
Imagine you are running an ecommerce shop and would like to suggest on titles of your products, with titles like this:
- wakeboard
- washing machine
- washington wizards basketball
- water glass
- wax crayon
- werewolf mask
- wool socks
So, what is returned when a user types wa? Every term starting with wa -
but what is a good order? Alphabetic? Reversed? Anything else?
Let’s keep that in mind for later and come up with a sample implementation.
Naive implementation
Seeing the terms above, what would be a straight forward solution to this?
How about storing all search terms in a list or a set, optionally make it sorted to be able to exit early. When a user searches for a term, use that term, iterate the list, check if the term begins with the input and exit, once the next term has a different prefix or enough terms have been collected.
Sounds great, time to come up with a zero dependency Java implementation:
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import static org.assertj.core.api.Assertions.assertThat;
public class SimpleListSuggestionTests {
private final List<String> suggest = new ArrayList<>();
@Test
public void testSimpleSuggestions() {
suggest.addAll(List.of("wakeboard",
"washing machine",
"washington wizards basketball",
"water glass",
"wax crayon",
"werewolf mask",
"wool socks"));
suggest.sort(java.lang.String.CASE_INSENSITIVE_ORDER);
List<String> results = suggest("wa", 10);
assertThat(results).containsExactly("wakeboard", "washing machine",
"washington wizards basketball", "water glass", "wax crayon");
results = suggest("was", 1);
assertThat(results).containsExactly("washing machine");
}
private List<String> suggest(String input, int count) {
return suggest.stream()
.filter(s -> s.startsWith(input))
.limit(count)
.toList();
}
}
This implementation has a couple of implicit properties:
- in-memory only
- Searching becomes slower depending on the size of the data set and the number of responses — an immediate show stopping criteria
- The order is defined by the sorting logic - so weighting could be implemented here already!
- Duplicate data is stored. The
waprefix is stored five times. This might not be a lot in this case but think of millions of suggestions. - Support for deletes and updates
So let’s make this more efficient with a radix tree!
Radix trees
One of the first data structures that come to mind for efficient look-ups are trees, and this use-case is no difference. Imagine building a tree from the above data structure. The basic approach would be to split each product title into single characters and build a tree out of that like this (open in a new tab for a bigger image):
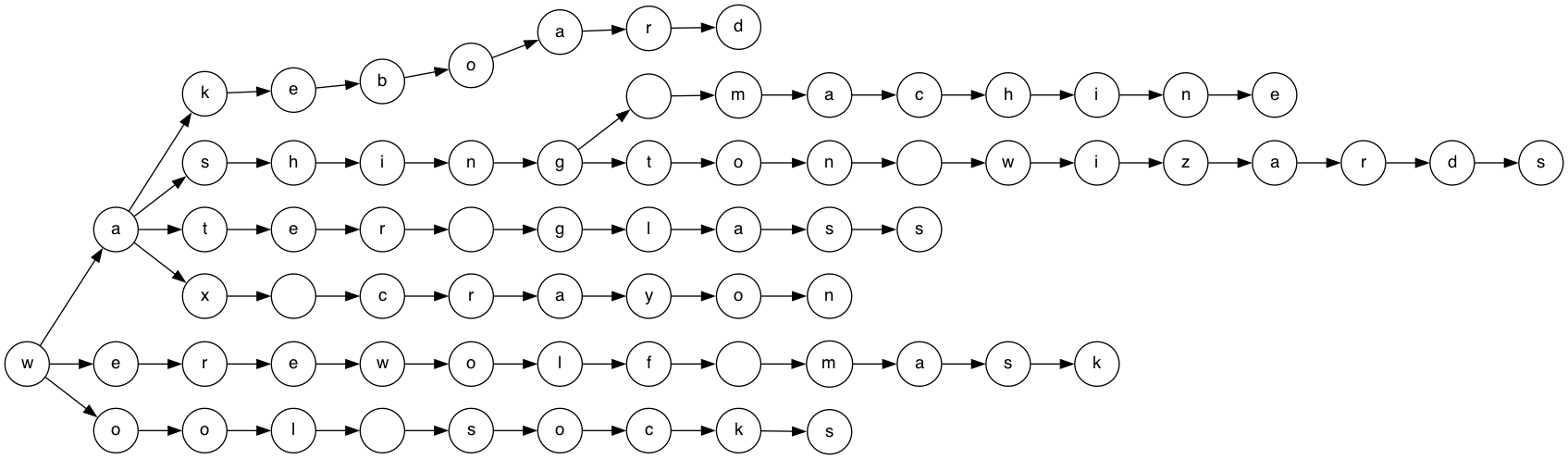
For the sake of simplicity this goes from right to left instead of top down,
otherwise this would take up too much space. Also the basketball term is
cut to keep the tree small enough to read.
Using such a data structure for every input you can basically ‘walk’ the tree - no need for checking irrelevant suggestions like in the naive implementation. Also, look-ups are no more based on the size of the total data set compared to the initial implementation.
Inserts and deletes can be implemented by adding or removing a child to a single node.
So, while this would be much faster, let’s simplify this even more before churning out some code.
Adaptive radix tree
Looking at this you may have noticed a possible optimization. If a node has only a single child, these could be grouped together, if the node supports storing more than a character.
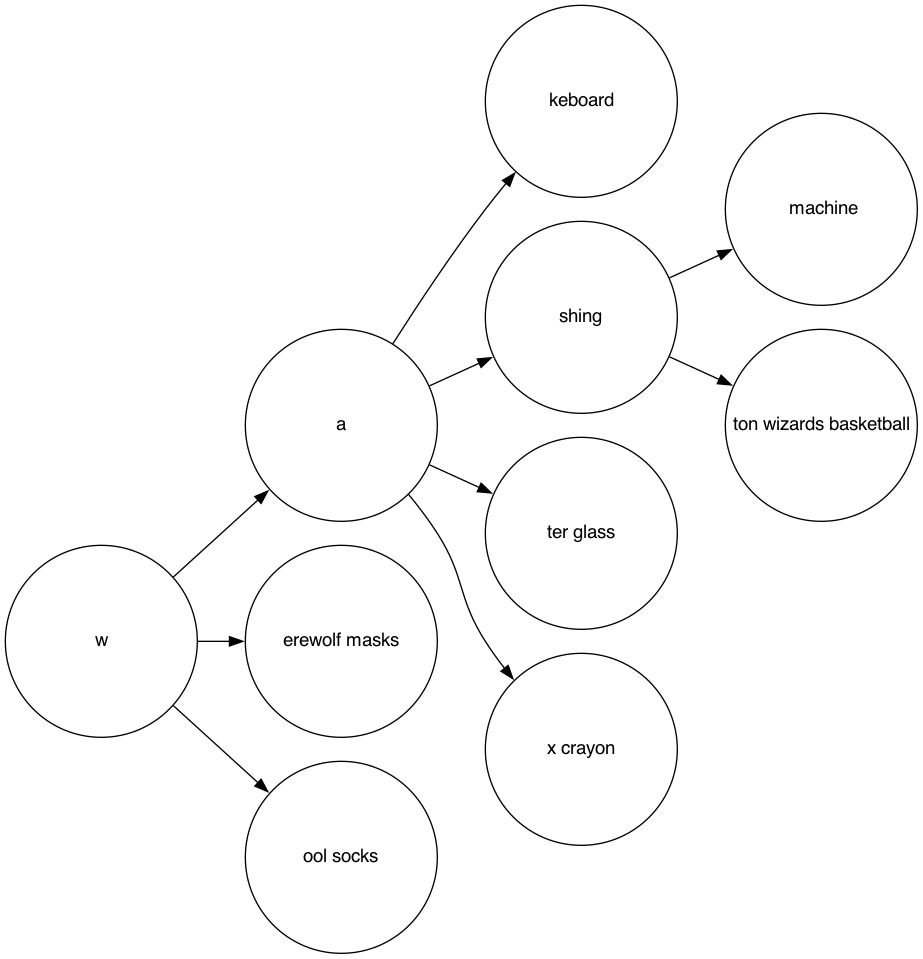
This nodes has a lot less nodes. This means less memory for your implementation and faster walking times. Now we could go full learning mode and write our own tree, but as usual the Java ecosystem has us covered. There is a great library named concurrent-trees (which has not been updated since 2019, but good enough for our example). That one features a concurrent radix tree. Let’s use this one for our implementation:
@Test
public void testRadixTree() {
ConcurrentRadixTree<Character> radixTree =
new ConcurrentRadixTree<>(new DefaultCharArrayNodeFactory());
for (String input : List.of("wakeboard", "washing machine",
"washington wizards basketball", "water glass",
"wax crayon", "werewolf mask", "wool socks")) {
radixTree.put(input, '\0');
}
Iterable<CharSequence> suggestions = radixTree.getKeysStartingWith("wa");
assertThat(suggestions).containsExactly("wakeboard", "washing machine",
"washington wizards basketball", "water glass", "wax crayon");
}
This implementation is a little different, as it supports storing a key/value
pair for each entry, so that you can store some sort of metadata, when a key
is found and also retrieve that with different methods. So far this
is not needed and a \0 is used for all values. If a radix tree is used for
something like URL mapping, then the value could be a reference to the
method that should take care of request processing.
Apart from that the radix tree is doing exactly what we want. A nice side effect of using this is the ability to inspect the tree by pretty printing
System.out.println(PrettyPrinter.prettyPrint(radixTree));
returns
○
└── ○ w
├── ○ a
│ ├── ○ keboard (\0)
│ ├── ○ shing
│ │ ├── ○ machine (\0)
│ │ └── ○ ton wizards basketball (\0)
│ ├── ○ ter glass (\0)
│ └── ○ x crayon (\0)
├── ○ erewolf mask (\0)
└── ○ ool socks (\0)
Much more readable than my mediocre graphviz skills above! ASCII art FTW!
So, now we got a data structure, that is fast, supports updates and removals and even values for a matching key or several. Now, this can be used as a fancy suggest data structure? All we need are product titles! Well… not so fast!
Supporting weights with a pruning radix tree
So far, there is no sorting in our radix trees. Responses are sorted
alphabetically, which is some kind of sorting — but has nothing to do with
relevancy from a user’s or search provider perspective. Let’s take a look at
a known German ecommerce engine, searching for sp
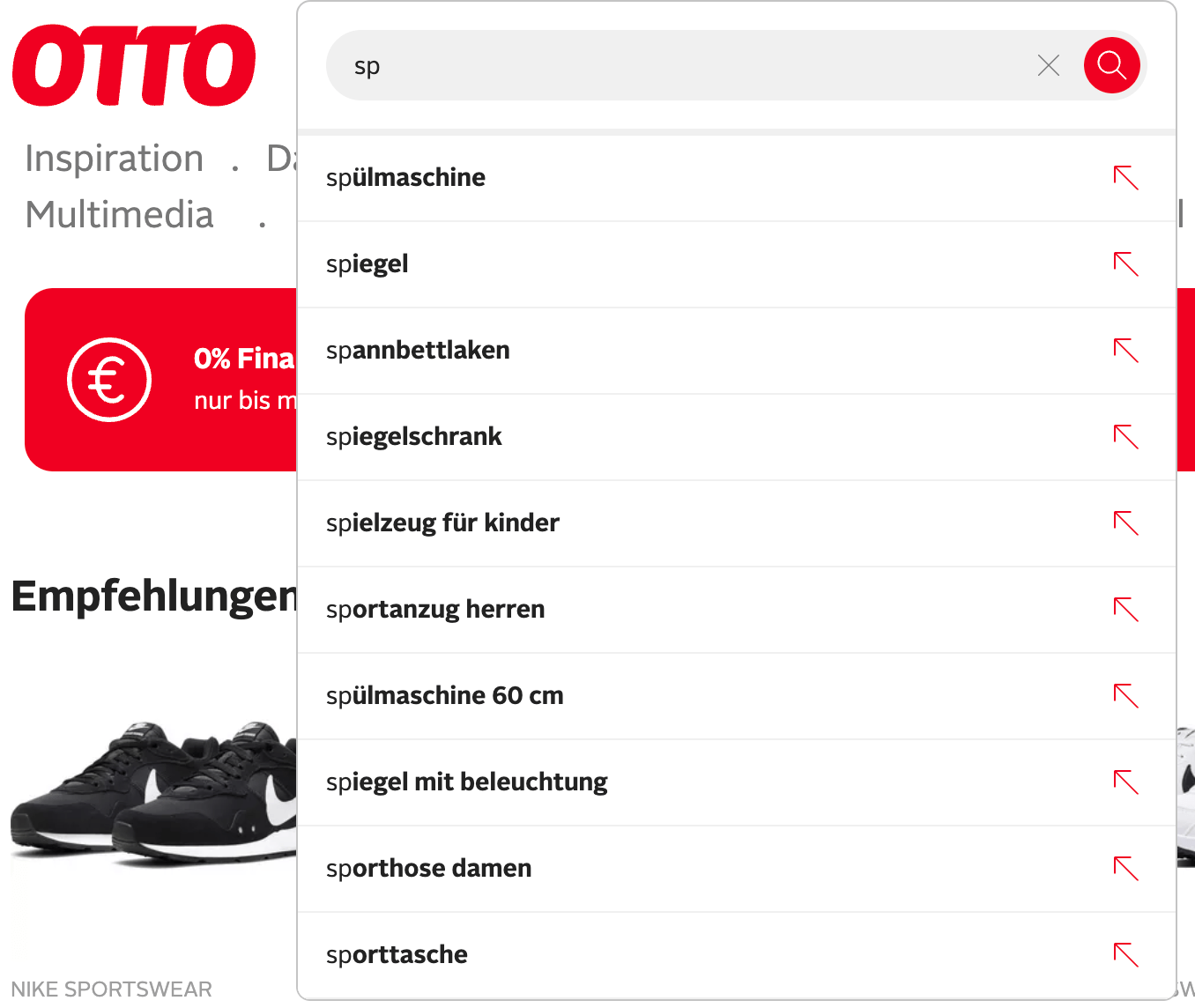
Top responses are spülmaschine (dish washer), spiegel (mirror),
spannbettlaken (fitted sheet), spiegelschrank (mirror cabinet),
spielzeug für kinder (toys for kids). Those are definitely not ordered
alphabetically. Probably they are sorted for most common searches, most
sales, or products making most money — a dish washer seems to be the most
expensive thing.
A possible solution is to add a weight to each final node. With the concurrent radix tree shown we could change the implementation like this:
@Test
public void testRadixTreeWithWeight() {
ConcurrentRadixTree<Integer> radixTree =
new ConcurrentRadixTree<>(new DefaultCharArrayNodeFactory());
final AtomicInteger counter = new AtomicInteger(100);
for (String input : List.of("wakeboard", "washing machine", "washington wizards basketball", "water glass",
"wax crayon", "werewolf mask", "wool socks")) {
radixTree.put(input, counter.getAndDecrement());
}
Iterable<KeyValuePair<Integer>> unsorted = radixTree.getKeyValuePairsForKeysStartingWith("wa");
assertThat(unsorted).hasSize(5);
// complex transformation, required due to lazy iterator
List<KeyValuePair<Integer>> results = new ArrayList<>();
unsorted.forEach(results::add);
// sort by integer
results.sort(Comparator.comparing(KeyValuePair::getValue));
assertThat(results).map(KeyValuePair::getKey).containsExactly("wax crayon", "water glass",
"washington wizards basketball", "washing machine", "wakeboard");
}
As you can see, the results at the bottom are now sorted by the integer
stored in the value. This however is a pretty bad solution to this problem,
as it requires walking through all results and resorting the list a second
time after it is returned. This also means, that if you get back thousands
of results, all of these need to be resorted — making this solution
exceptionally slow for short terms like wa. Take a look at the issue when
pretty printing
○
└── ○ w
├── ○ a
│ ├── ○ keboard (100)
│ ├── ○ shing
│ │ ├── ○ machine (99)
│ │ └── ○ ton wizards basketball (98)
│ ├── ○ ter glass (97)
│ └── ○ x crayon (96)
├── ○ erewolf mask (95)
└── ○ ool socks (94)
This shows, that the tree is sorted exactly like before, but contains the weights, which requires a post retrieval step.
Luckily there is a solution to this problem! And that is adding weights not just in the final node, but on a parent having child nodes. This is exactly what the pruning radix trie does. This way one can exclude certain child nodes immediately when walking through the trie.
For a better explanation, let’s show the follow radix trie (again as ASCII art). Note: I changed the weights here slightly compared to above to make a point.
○
└── ○ w 20
├── ○ a 10
│ ├── ○ keboard (4)
│ ├── ○ shing 6
│ │ ├── ○ machine (6)
│ │ └── ○ ton wizards basketball (1)
│ ├── ○ r 3
│ │ ├── ○ drobe (2)
│ │ ├── ○ ehouse (3)
│ ├── ○ ter glass (10)
│ └── ○ x crayon (2)
├── ○ erewolf mask (8)
└── ○ ool socks (20)
Now let’s walk through a lookup for typing wa and retrieve the top 2
hits.
- Go to
w -> a - Retrieve
keboard, putwakeboard/4into priority queue - Check
shingwith max score of 6, so enter sub nodes - Retrieve
shing machine, putwashing machineinto priority queue (1st) - Ignore
ton wizards basketball - Ignore
rand all its child nodes due to lower score than lowest in priority queue (3 vs. 4) - Check
ter glass, putwater glass/10into priority queue (1st),wakeboard/4falls out - Ignore
x crayon, score lower than 6
You can check the blog post about the pruning radix trie by Wolf Garbe (who also invented SymSpell) to get some really awesome performance stats, especially for short inputs.
Let’s take a look how this looks using the JPruningRadixTrie dependency:
@Test
public void testPruningRadixTree() {
PruningRadixTrie prt = new PruningRadixTrie();
final AtomicInteger counter = new AtomicInteger(1);
for (String input : List.of("wakeboard", "washing machine",
"washington wizards basketball", "water glass",
"wax crayon", "werewolf mask", "wool socks")) {
prt.addTerm(input, counter.incrementAndGet());
}
List<TermAndFrequency> results = prt.getTopkTermsForPrefix("wa", 2);
assertThat(results).map(t -> t.term() + "/" + t.termFrequencyCount())
.containsExactly(
"wax crayon/6",
"water glass/5"
);
}
The sample implementations of this pruning radix trie are reading from a
file, that contains terms and a weight and add those item by item to the
radix trie, resulting in a fair amount of splitting. There is no
serialization format of the trie that would prevent this. Also there is no
remove() method to remove items from the trie, though that could be
implemented.
While looking at that implementation I remembered that Lucene has a weighted FST, that would work similar — apart from the ability to be updated while running.
FSTs
This brings us to FSA/FSTs and the Lucene suggest package. If you need to solve any search problem, your first reaction should always be to look at Apache Lucene - the likelihood that someone has tackled this already is high. Apache Lucene has a whole fantastic suggest package.
Some boring theory before we dive into some Java code. What are FSA/FSTs? Well, luckily Mike McCandless has us covered with blog posts (1, 2) and this web application to visualize sample FSTs. Those blog posts are from 2011, so this has been in Lucene for a long time. There is also a great presentation from Mike and Robert about Automata Invasion and how Automatons were added to Lucene.
The basic class to start with is the FSTCompletionBuilder, but we want weights, so we want weighted FST to have the same behavior than the pruning radix tree.
Let’s take a look at some java code:
@Test
public void testLuceneWFST() throws Exception {
Directory directory = new NIOFSDirectory(Paths.get("/tmp/"));
String data = """
wakeboard\t1
washing machine\t2
washington wizards basketball\t3
water glass\t4
wax crayon\t5
werewolf mask\t6
wool socks\t7
""";
FileDictionary fileDictionary = new FileDictionary(new StringReader(data));
WFSTCompletionLookup lookup = new WFSTCompletionLookup(directory, "wfst", true);
lookup.build(fileDictionary);
List<Lookup.LookupResult> results = lookup.lookup("wa", null, false, 10);
assertThat(results).hasSize(5);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("wax crayon/5",
"water glass/4",
"washington wizards basketball/3",
"washing machine/2",
"wakeboard/1");
}
This pretty much resembles the functionality of the pruning radix tree. With one difference due to the WFSTCompletionLookup constructor which prefers exact hits and puts them automatically on the first position.
Note: For the sake of simplicity this uses a FileDirectory to read
data from strings, however usually this is read from a Lucene index.
The input is a file/string that splits scores and terms via tab. This file format can also be read by the pruning radix trie class, so you can reuse those for performance tests.
In my non-professional performance tests the WFST lookup was a lot faster for longer terms, but the pruning radix tree was a little faster on three letter inputs. As usual test with your own data to reach your own conclusions.
The Lucene implementation comes with a few advantages and drawbacks. On the one hand it is immutable once generated, on the other hand it can be serialized and deserialized like
lookup.store(new DataOutputStream(new FileOutputStream("/tmp/foo.out")));
WFSTCompletionLookup fromDiskLookup =
new WFSTCompletionLookup(directory, "wfst", true);
fromDiskLookup.load(new DataInputStream(new FileInputStream("/tmp/foo.out")));
fromDiskLookup.lookup("wa", null, false, 10);
My sample file with six million terms takes about 42MB serialized on disk, about 43% of the original text file with weights.
We’ve been talking a lot about weights from the beginning. This has been our relevancy metric for most of this posts — and we’ll get to the point that this is probably not the best one, but let’s take a step back from a concrete implementation and talk about weights.
Using weights for suggestions
If each search term is associated with a weight, there has to be an automatic way of determining that weight, let’s come up with some suggestions for this, where this weight could be created from.
First, you could log all your searches and if they were successful (more than zero hits) or sort by number of hits and display based on that. Just using the hits in your search is not a good metric though from a business perspective though, especially when you are marketplace. Taking into account if that search ended in a purchase might be a good idea.
Second, using your recent purchase data in combination with the products being bought could be another solution to solve this. This helps to suggest products that really get bought and not just searched often — a common pattern for websites, where folks just check out the luxury items, but do not buy those, for example real estate or holiday destinations.
Third, there are more factors that can be taken into account for a search, that are not static, like previous searches or filtering by category.
Anyway, back to suggests…
Catering for typos
With Lucene in our hands, you get all the full text search capabilities. So
far, typos are not supported. So if you search for wasch instead of wash
no hits are returned with our data set. So what can be done about it?
The most common approach is a fuzzy query, that usually uses something like the Levenshtein distance to find similar terms.
Let’s find out how this can be added to our Lucene search. Lucene features a FuzzySuggester based on the AnalyzingSuggester.
@Test
public void testAnalyzingSuggester() throws Exception {
Directory directory = new NIOFSDirectory(Paths.get("/tmp/"));
FuzzySuggester analyzingSuggester = new FuzzySuggester(directory, "suggest",
new StandardAnalyzer());
// weights and payload omitted
String data = """
wakeboard
washing machine
washington wizards basketball
water glass
wax crayon
werewolf mask
wool socks
""";
FileDictionary fileDictionary = new FileDictionary(new StringReader(data));
analyzingSuggester.build(fileDictionary);
List<Lookup.LookupResult> results =
analyzingSuggester.lookup("wasch", false, 5);
assertThat(results).hasSize(2);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("washing machine/1",
"washington wizards basketball/1");
}
Using the FuzzySuggester allows for typos. At most this suggester will
only for a maximum edit distance for 2. Also, this suggester does not favor
correct terms over fuzzy ones. You could probably have more than one suggest
data structure, one being fuzzy, one being exact and query the correct one
first. As queries are fast, this is usually not much of a problem.
How does this work internally? By using Levenshtein Automata. There is a
great blog post named Damn Cool Algorithms: Levenshtein
Automata
that explains the concept. In short, in case of the
FuzzySuggester the Levenshtein automaton is created for the input when
lookup() is called.
As with full text search queries, fuzziness is often a workaround due to a
proper missing implementation. Usually you do not want to replace arbitrary
characters, but rather characters that are similar. Instead of the
StandardAnalyzer a phonetic analyzer might help — not really for product
names but rather real names, but let’s stick with the example for now.
@Test
public void testPhoneticSuggest() throws Exception {
Map<String, String> args = new HashMap<>();
args.put("encoder", "ColognePhonetic");
CustomAnalyzer analyzer = CustomAnalyzer.builder()
.addTokenFilter(PhoneticFilterFactory.class, args)
.withTokenizer("standard")
.build();
Directory directory = new NIOFSDirectory(Paths.get("/tmp/"));
AnalyzingSuggester suggester =
new AnalyzingSuggester(directory, "lucene-tmp", analyzer);
String input = """
wakeboard\t1
washing machine\t2
washington wizards basketball\t3
water glass\t4
wax crayon\t5
werewolf mask\t6
wool socks\t7
""";
FileDictionary dictionary = new FileDictionary(new StringReader(input));
suggester.build(dictionary);
List<Lookup.LookupResult> results = suggester.lookup("vaschink", false, 5);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("washington wizards basketball/3",
"washing machine/2");
}
As you can see a term like vaschink returns correct results. While this
looks great, I’d rather use this for a second try, if the exact suggester
did not return anything, because a input like voter will also return the
water glass from the suggest data. That might be hard to explain to your
users.
In general a phonetic approach does not seem like the best idea. If anyone knows about papers to have some soundex-like functionality for keys next to each other, that might be a good idea to catch and ignore typos, when hitting the wrong key on phone keyboards — coming with all the complexity of different keyboards across the world. An interesting and fast approach to this problem is SymSpell, as it stands out speed wise. There are a few standalone implementations of that library, but few integrations with search engines, except for lnx including a great blog post about the implementation. I also stumbled over a Java implementation with Solr integration.
Infix suggestions
So far all suggestions have been prefix suggestions. However you may want to
search for terms that are within a term like washington wizards basketball. When you search for wiz or bas, you may want to return that
item as well. Lucene has a
AnalyzingInfixSuggester
for this use case.
Check out this example:
@Test
public void testInfixSuggester() throws Exception {
Directory directory = new NIOFSDirectory(Paths.get("/tmp/"));
AnalyzingInfixSuggester suggester =
new AnalyzingInfixSuggester(directory, new StandardAnalyzer());
String input = """
wakeboard\t1
washing machine\t2
washington wizards basketball\t3
water glass\t4
wax crayon\t5
werewolf mask\t6
wool socks\t7
""";
FileDictionary dictionary = new FileDictionary(new StringReader(input));
suggester.build(dictionary);
List<Lookup.LookupResult> results = suggester.lookup("wiz", false, 5);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("washington wizards basketball/3");
results = suggester.lookup("ma", false, 5);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("werewolf mask/6", "washing machine/2");
}
As shown in the last example using ma, highlighting is important to
show which terms of a line matched to provide more context.
Filtering suggestions
Imagine browsing through an e-commerce site, selecting a category and then typing at the search bar at the top. Are you expecting to get suggestions just within that category or from the whole data set? As usually with search there is no correct answer, maybe displaying both makes sense. So, how can this be done using our Lucene suggesters?
There are a couple of possibilities how this could be done. The
AnalyzingInfixSuggester
is backed by an index and supports a context in the lookup() method, which
in turn gets converted to a query, that could filter for results. The other
implementations do not support this though. Two ideas come to mind for those:
- Have an own suggester per category plus one generic
- Each term has a category prepended, that gets automatically prepended when a search is executed
sports/wakeboard 1
electronics/washing machine 2
sports/washington wizards basketball 3
goods/water glass 4
kids/wax crayon 5
carnival/werewolf mask 6
clothes/wool socks 7
In addition you could index each term under an all/ prefix to have a
generic suggester. You may also need to set a payload to contain the
original search term in that case or remove the prefix before returning data
to the customer. Also it leads to duplicate data being created.
This is quite a tedious solution and shows, that once you are used to full text search, a filter would be a nice solution to this problem.
Side note: the Elasticsearch completion suggester supports contexts that could be used for this.
Adding synonyms
The only thing we have not talked about so far are synonyms. Let’s see how that works with current Lucene examples:
@Test
public void testSynonyms() throws Exception {
Map<String, String> args = new HashMap<>();
// content:
// merino => wool
args.put("synonyms", "synonyms.txt");
CustomAnalyzer analyzer = CustomAnalyzer.builder()
.addTokenFilter(SynonymGraphFilterFactory.class, args)
.withTokenizer("standard")
.build();
Directory directory = new NIOFSDirectory(Paths.get("/tmp/"));
AnalyzingSuggester suggester = new AnalyzingSuggester(directory, "lucene-tmp",
new StandardAnalyzer(), analyzer);
String input = """
wakeboard\t1
washing machine\t2
washington wizards basketball\t3
water glass\t4
wax crayon\t5
werewolf mask\t6
wool socks\t7
""";
FileDictionary dictionary = new FileDictionary(new StringReader(input));
suggester.build(dictionary);
List<Lookup.LookupResult> results = suggester.lookup("merino", false, 5);
assertThat(results).map(Lookup.LookupResult::toString)
.containsExactly("wool socks/7");
}
By having a synonym from merino to wool in this example, searching for
merino also returns the wool socks suggestions. This is of limited use
here, as it requires the term to be fully typed before the synonym is
applied. Having merino socks in the list of suggestions sounds like the
better plan in this concrete example. I played a little with different query
analyzers to improve the above behavior, but could not come up with
something usable, if you have something up and running that I missed, please
contact me.
Not fully on topic, but I found this paper Unsupervised Synonym Extraction for Document Enhancement in E-commerce Search while searching for this topic. Might be an interesting approach. A little older is Query Rewriting using Automatic Synonym Extraction for E-commerce Search. In general the SIGIR Workshop On eCommerce is a good website to check out papers around E-Commerce.
Where does the suggestion start?
So, this is something from my ask on twitter, and I agree that this is
unsolved often unsolved in search engine suggestions. Sending a query for
washington wiz can be interpreted as a prefix based query, split by
blank where the first term is a complete one and can be looked up as is in
an inverted index. But what happens if someone sends a query for wash wizards —
it’s likely no results will be returned? Why? Because likely the state of
the caret was ignored. Looks like someone had a suggestion like washington wizards and probably moved the cursor to a term an started deleting
characters. This means that the prefix search has to be flipped probably as
wizards is not the term of the focus.
At one of my previous jobs the cursor position was sent along with the queries and the terms were reordered to execute a prefix query. This however required some sort of tokenization before the query was sent, so it was limited to that language.
Please share: What is everyone else doing here? Searching if a term contains any hits and if not consider it a prefix term? Or remove it completely from the query? All of those approaches may lead to unwanted side effects from my perspective.
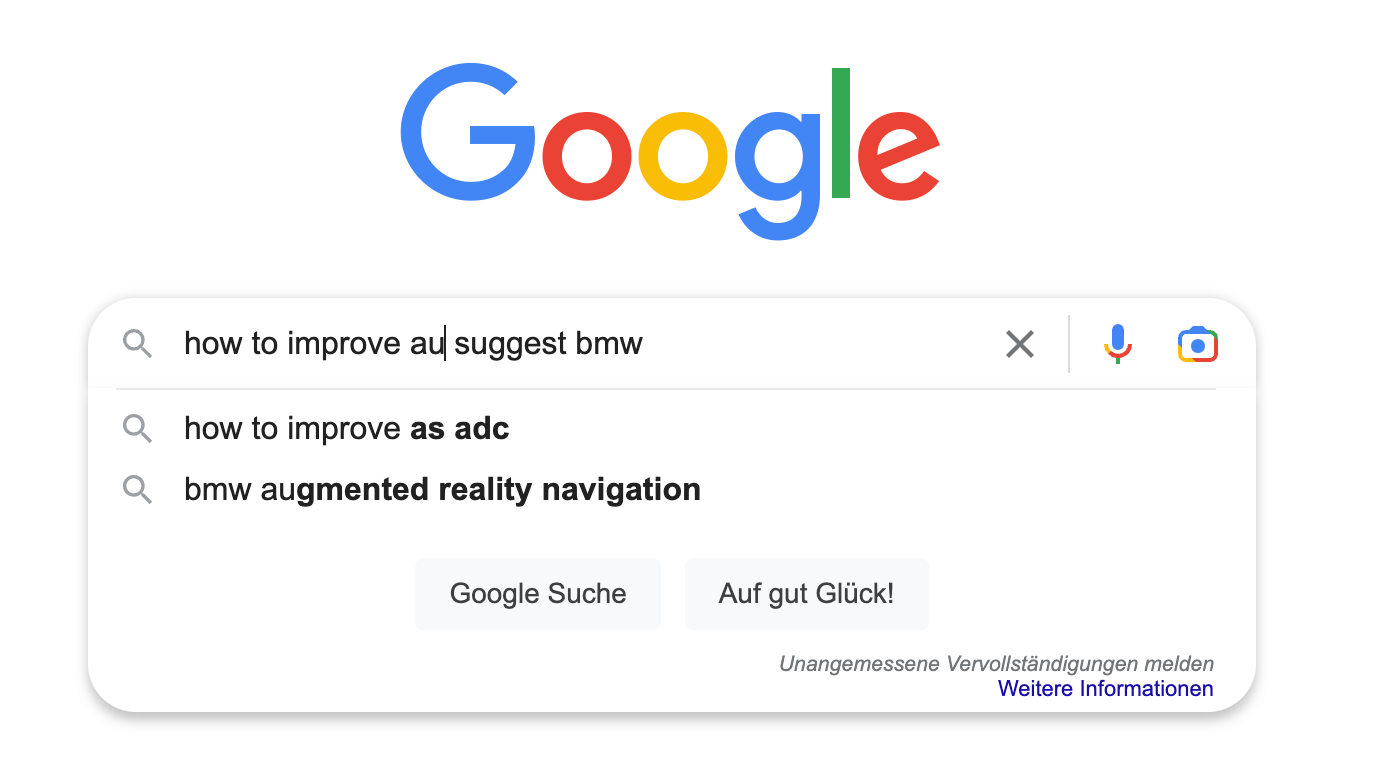
Side note: Take a look at Google, they offer different suggestions. They seem
to use the most common term from the input query regardless of position plus
running another query that just uses everything up until the cursor for a
suggestion, see this screenshot, where the cursor was after au. Play
around with it, and you will find more variants.
Ranking
So far, we only had an integer as the weight for our suggestions. This is an oversimplification in today’s world without telling how this has been calculated, as this is usually not just a number, but has been calculated from several factors - likely including the previous queries from the user or even previous purchases. Which means ranking is useless, when it is precalculated as it needs to be customized for each user. Sometimes folks work around this using clustering, but I think the ultimate goal is the segment of one, as it used to be called in CRM systems, back when I studied. Today it’d just be personalization I guess.
One common pattern is to score previously typed queries higher, as a user might want to revisit a previous search.
Another common pattern here is probably some sort of Learning-to-rank in combination with re-ranking. First, retrieve top-n suggestions via a fast phase, then re-rank against model to have another top-n of the suggestions.
Another re-ranking model could also be a category, as mentioned above already or a recency based approach where the searches of all users are taken into account — think of a steep increase for a new product due to release day.
So, how to combine ranking with retrieval? When it comes to suggestions this is only possible when search engines properly support this. For suggestions this seems rare.
Testing
Despite showing everything as unit tests, the topic of integration testing needs to be covered properly. Once you have a mechanism to create the list of suggestions and you do not run against real product data, you need to ensure that suggestions return data. A suggestion hinting into nowhere is a worst case suggestion.
Performance tests with your full data set are obligatory, otherwise tests are artificial.
Elasticsearch
Elasticsearch has infrastructure to support suggestions. The completion suggester is limited as it is a pure prefix suggester, the term or phrase suggesters are not exactly covering the required functionality. However the search as you type field type is worth a second look. Due to the speed up of block max WAND to retrieve faster top hits in Lucene 8. This also opened the door for rank feature field type and distance feature query to support recency based queries. This allows to execute regular search queries, that are pretty fast. Having a dedicated suggest index would definitely be worth a try with this. As one is executing a regular search, you do have the power of analyzers, synonyms and queries available. This might help as an example:
PUT suggestions
{
"mappings": {
"properties": {
"suggestion": {
"type": "search_as_you_type"
},
"category": {
"type": "keyword"
},
"weight": {
"type": "rank_feature"
}
}
}
}
PUT suggestions/_bulk?refresh
{ "index" : {"_id" : "1" } }
{ "suggestion" : "wakeboard", "category" : "sports", "weight" : 1 }
{ "index" : {"_id" : "2" } }
{ "suggestion" : "washing machine", "category" : "household", "weight" : 2 }
{ "index" : {"_id" : "3" } }
{ "suggestion" : "washington wizards basketball", "category" : "sports", "weight" : 3 }
{ "index" : {"_id" : "4" } }
{ "suggestion" : "water glass", "category" : "household", "weight" : 4 }
{ "index" : {"_id" : "5" } }
{ "suggestion" : "wax crayon", "category" : "kids", "weight" : 5 }
{ "index" : {"_id" : "6" } }
{ "suggestion" : "werewolf mask", "category" : "fun", "weight" : 6 }
{ "index" : {"_id" : "7" } }
{ "suggestion" : "wool socks", "category" : "clothing", "weight" : 7 }
GET suggestions/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase_prefix": {
"suggestion": "wash"
}
}
],
"should": [
{
"rank_feature": {
"field": "weight",
"log" : {
"scaling_factor":1
}
}
}
]
}
}
}
In the above example, the supplied weight is taken into account together
with the bm25 search — which by default would score washing machine over
washington wizards basketball. Also, you could use a filter clause to
filter by category and another should clause to boost previous queries.
On top of that Elasticsearch has a built-in rescore query, if you come up with your own fancy scripting, but do not want to run against all documents.
Now is this enough for ranking suggestions? Well, there is no learning to rank included, but the learning-to-rank plugin from OpenSource connections is there. And that one is powering searches on Wikipedia. In an interview about the implementation there is a hint that the complex part is the tooling named mjolnir that creates the machine learning model from clicks and searches into a relevance metric for queries and articles.
In addition, Elasticsearch now has a vector search, and it allows combining with regular searches since 8.5! However the way I understand the documentation, you cannot run a knn search as part of a rescoring as it is a top level element of a search.
While knn search might not work for this use-case and suggestions, you still
can have really fast searches using the search-as-you-type field type, use
the should clause in a Boolean query to take previous searches into account and
use the distance_feature query to take recency into account or filter by
category.
One of the things that is hard to explain to non-search people (like your data scientists trying to make sense of that suggestion order) can be the score from an explain parameter in the search body.
What if the data scientist could create their model independently of a search? That brings us to…
Rescoring with Vespa
A few weeks ago I saw a demo of a suggest implementation, that used Vespa. I never managed to dive deep into Vespa, but I found a couple of things really nice. First the configuration I saw included the query and so was intuitively to spot, but more importantly the use of XGBoost, so that the data scientists could focus on creating the model. Also, the suggestion data was kept in memory for speed.
So the first search was a regular (imagine Dr. Evil ticks here) search, that then got reranked against the model. All the configuration was in one place and so good to spot and understand as well as the split from model use and creation.
Especially in bigger companies where running and developing a suggestion engine is split from query analysis, this sounds like a useful approach to me.
Challenge - Architect a suggest only solution
So how would I built a suggest solution? The main question is indeed, would I really built a suggest only solution at all? This would require indexing data twice, for document search and suggestions, and maybe there is one system able to do both. Is this useful, especially when your search is a major legacy implementation? The search community may talk a lot about modern search solutions and approaches (thinking of Vectara, which was relatively recently announced and looks interesting). But looking at the big ecommerce companies, you will see legacy search implementations from a 7-8 years and folks being conservative to replace with a modern search, because of all the grown infrastructure around search. That’s when reality kicks in hard! But back to my search implementation. A few things I would consider:
Offline creation: The ability to split serving from creation is important to me. This way this component handles the whole creation process in the background and will not affect live servings. Splitting storage from compute sounds like good plan. So writing to a blob store like S3 and letting the query component pick data up once does sounds like a good idea.
Incremental updates: Unsure if those are needed, if the index creation process is fast enough or you are good with a daily update.
Synchronization with search engine: If a product is not available for search but it’s suggested for, that may pose a problem and needs to be fixed faster than a daily cron job.
No deserialization overhead: By default the pruning radix tree implementation needs to rebuild the tree when the JVM starts up. Having a proper binary serialized structure of the final tree makes more sense when a dedicated writer creates that data structure.
Reader can be scaled based on load: The reader should have the ability to auto-scale based on load - which means it needs to monitor execution times or utilization of thread pools and their respective queue sizes.
Rescorer: Maybe having a pruning radix tree for initial lookup of the top-n followed by a rescoring face using a library like Tribuo in order to properly split model generation and maintenance from use.
While all of this would probably end up in a sizable solution, the question remains if this is really worth all the work instead of going with Elasticsearch, Vespa, Solr or a hosted solution like Algolia. Also tools like typesense incorporate some way of lightweight personalization and even Meilisearch announced in their series A announcement that this is something on the commercial roadmap.
Pick your battles, having a good search might be more important for your revenue than having suggestions with fancy ranking behind it. Pro tip: Come up with numbers to prove this!
Summary
I hope you enjoyed a few basics about suggestions here across with some
implementation details, so that you can take away some code examples as well.
I have not even started about non-western languages in here, as that would
likely warrant another blog post of the same length. Same for specialties
like decompounding in German like languages — ensuring to suggest
blumentopf (flower pot), when blumen topf is typed.
From what I see Hybrid search will continue to evolve, converging vector search as well model based search (not your own models) as well as BM25 based searches.
With large language models like ChatGPT there might be proof that a proper description what you are searching for (or even voice input) might be able to give you exactly what you are after. Maybe this makes suggestions less useful, as searches itself will evolve.
The appearance of humongous models as well as zero shot models that require no training we may enter an era that does not need any complex training component. Also the question remains, if those are fast enough for suggestions. Keep in mind that suggestions are not authoritative but should only help the user as a guidance to the correct results.
Buying models that others create may become a thing in the next generation of search engines.
Search will see major changes in the next three years, and I think so will suggestions. Let’s see who rises, who keeps up and who evolves into something completely new. Keep looking at research results, and following academic projects like Terrier or anserini is a good strategy to stay up-to-date.
Thanks to Torsten, Tobias, Jo, Paul and Tom for providing some feedback what should be in here based on my initial tweet. As usual I am sure you had different things in mind 😀.
Resources
- GitHub repository: concurrent-trees: Java implementation of a radix and a suffix tree
- Blog post: The Pruning Radix Trie — a Radix Trie on steroids
- GitHub repository: PruningRadixTrie - 1000x faster Radix trie for prefix search & auto-complete
- GitHub repository: Java port of wolfgarbe/PruningRadixTrie
- GitHub repository: PyPruningRadixTrie - Python version of super fast Radix trie for prefix search & auto-complete
- Blog post: Damn Cool Algorithms: Levenshtein Automata
- Paper: Fast string correction with Levenshtein automata
- Spelling: Hunspell
- Spelling: JamSpell, a fast C++ implementation
- Music from the past: From First to Last - Failure by designer jeans
- Multi series blog post: Improving product search with Learning to Rank
- Blog post: Distance Metrics in Vector Search
- Paper: An Efficient Word Lookup System by using Improved Trie Algorithm, a trie trying to remove as much redundancy as possible, also for suffixes and infixes
- Paper: START – Self-Tuning Adaptive Radix Tree
- Paper: The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases
- GitHub repository: ML Papers Explained
- Blog post: Implementing a Modern E-Commerce Search
- Blog post: Implementing A Linkedin Like Search As You Type With Elasticsearch
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or contact me on twitter, GitHub or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to do so and append to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!