 Alexander Reelsen
Alexander ReelsenIndexing german Wikipedia articles for fun and vector search
TLDR; This article covers extracting and indexing german Wikipedia articles into Elasticsearch by generating vector embeddings using the Deep Java Library and a Hugging Face model.
Disclaimer: This is my first time venturing into vector search with Hugging Face models, it’s likely I have made a ton of mistakes. Feel free to notify me and point out every little one of them, allowing me to learn.
But why?
My former colleague Karel published a wonderful demo/presentation how to get started with semantic search and vector embeddings creation. Take your time and check it out over here. There is also another wonderful blog post in addition using Elasticsearch from Karel. Thank you!
That gave me the final motivation to also play around with this. But I’d like to try things out in my native language and not another stack overflow dataset. That said, it’s really hard to find any proper dataset. I decided Wikipedia entries in German would be worth a test.
Extracting articles from the Wikipedia XML dump
Wikipedia offers its german dumps as compressed XML - I used the
dewiki-latest-pages-articles[1-5].xml...bz2 files for this. You can take
a look at those on dumps.wikimedia.org.
The XML structure within a single file looks like this
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.10/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd" versi
on="0.10" xml:lang="de">
<siteinfo>
...
</siteinfo>
<page>
<title>Jacques Mbali</title>
<text bytes="1928" xml:space="preserve">'''Jacques Mbali''' (* [[1921]] in [[Aketi|Aketi Port-Chaltin]], [[D
emokratische Republik Kongo|Kongo]]; † [[22. Juni]] [[2007]] in [[Kinshasa]], [[Demokratische Republik Kongo|Kongo
]]) war [[Bischof]] im [[Bistum Buta]] von 1961 bis 1996.
...
</text>
</page>
<page>
...
</page>
...
</mediawiki>
The basic idea is to stream big bzipped XML files, extract each /page/text
and each /page/title into an entity. However there are more things to
check:
- The
textpart should not start with#redirector#WEITERLEITUNG, which marks a redirect (apparently that is also possible in German) - The
titlepart should not start withVorlage:,Wikipedia:,Kategorie:,Datei:orListeas these indicate overview pages and not real articles - turns out there are quite a few of those.
If any of the above cases matches, the article will be skipped and the next article will be processed.
If a valid article is found, then the page and title fields are mapped
to WikiPage record, which is put into an ArrayBlockingQueue<WikiPage>
queue as reading from a XML input stream is absolutely not our bottleneck.
Rendering and cleaning
You may have noticed the above syntax in the <text> element already. It’s
not HTML, it’s not markdown, but it is
wikitext. It’s more powerful
than markdown, when dealing with references, footnotes, tables, redirects or
categorization. All those things required for a full wiki.
Turns out there are not a lot of a up-to-date implementations parsing wikitext. My initial idea of using a parser and trying to extract the text out of that turned more complex than I wanted. Before this I tried pandoc first, which can convert Mediawiki syntax to HTML or text, but it turns out the Wikipedia syntax has additions that were not parsed properly.
I went with sweble-wikitext as
a parser and it took me a lot of staring into the unit test suite to
make sweble parse and render articles in HTML just like in Wikipedia.
My Wikipage record got a new method
public record WikiPage(String title, String content) {
public String toText() {
return Renderer.wiki2html2text(content);
}
}
As usual I am excellent with naming in my Renderer class - not. But at
least I found a way to generate pure text from the wiki entries using
JSoup.
To keep the text for vector embeddings clean I used JSoup to remove the following from the rendered HTML
- Reaching the end of an article that lists sources or literature, the rest of the text can be removed
- Remove all
<h[1-6]>contents - Remove all
<table>s - Strip remaining HTML using the HTMLStripCharFilter from Lucene
Now I have a text to generate vector embeddings on. Let’s take a look at this wikitext input
'''Jacques Mbali''' (* [[1921]] in [[Aketi|Aketi Port-Chaltin]], [[D
emokratische Republik Kongo|Kongo]]; † [[22. Juni]] [[2007]] in [[Kinshasa]], [[Demokratische Republik Kongo|Kongo
]]) war [[Bischof]] im [[Bistum Buta]] von 1961 bis 1996.
== Leben ==
Jacques Mbali empfing 1947 die [[Weihesakrament#Presbyterat|Priesterweihe]]. 1961 wurde er von Papst [[Johannes XX
III.]] in Nachfolge von [[Georges Désiré Raeymaeckers]] zum Bischof im Bistum [[Buta (Stadt)|Buta]] ernannt; von E
rzbischof [[Gastone Mojaisky-Perrelli]] wurde er [[Bischofsweihe#Episkopat|geweiht]]. Von 1978 bis 1980 war er [[A
postolischer Administrator]] des [[Bistum Bondo|Bistums Bondo]].<ref>{{Webarchiv|url=http://www.apostolische
-nachfolge.de/afrika.htm |wayback=20070716083145 |text=„Die Apostolische Nachfolge“ |archiv-bot=2019-09-12 12:45:4
4 InternetArchiveBot }}, Die Apostolische Nachfolge:Afrika</ref>
1996 wurde sein altersbedingter Rücktritt angenommen.
== Quellen ==
<references/>
== Weblinks ==
* {{Catholic-hierarchy|Bischof|bmbali}}
{{Personenleiste|VORGÄNGER=[[Georges Désiré Raeymaeckers]]|NACHFOLGER=[[Joseph Banga Bane]]|AMT=[[Bistum Buta#Ordi
narien|Bischof von Buta]]|ZEIT=1961–1996}}
{{SORTIERUNG:Mbali, Jacques}}
[[Kategorie:Römisch-katholischer Bischof (20. Jahrhundert)]]
[[Kategorie:Römisch-katholischer Bischof (21. Jahrhundert)]]
[[Kategorie:Bischof von Buta]]
[[Kategorie:Römisch-katholischer Theologe (20. Jahrhundert)]]
[[Kategorie:Römisch-katholischer Theologe (21. Jahrhundert)]]
[[Kategorie:Kongolese (Demokratische Republik Kongo)]]
[[Kategorie:Geboren 1921]]
[[Kategorie:Gestorben 2007]]
[[Kategorie:Mann]]
{{Personendaten
|NAME=Mbali, Jacques
|ALTERNATIVNAMEN=
|KURZBESCHREIBUNG=kongolesischer Geistlicher, Bischof von Buta
|GEBURTSDATUM=1921
|GEBURTSORT=[[Aketi|Aketi Port-Chaltin]], Demokratische Republik Kongo
|STERBEDATUM=22. Juni 2007
|STERBEORT=[[Kinshasa]], Demokratische Republik Kongo
}}
which becomes the following output
Jacques Mbali (* 1921 in Aketi Port-Chaltin, Kongo; † 22. Juni 2007 in Kinshasa, Kongo) war Bischof im Bistum Buta von 1961 bis 1996.
Jacques Mbali empfing 1947 die Priesterweihe. 1961 wurde er von Papst Johannes XXIII. in Nachfolge von Georges Désiré Raeymaeckers zum Bischof im Bistum Buta ernannt; von Erzbischof Gastone Mojaisky-Perrelli wurde er geweiht. Von 1978 bis 1980 war er Apostolischer Administrator des Bistums Bondo.
1996 wurde sein altersbedingter Rücktritt angenommen.
Generating vector embeddings with a Hugging Face model
Next step was to find a proper Hugging Face model. Choosing the wrong one and you will end up with a bad search. As I did not have any clue, I picked the first one I found, as this is a fun project. That’s my scientific skills summed up perfectly.
I went with aari1995/German_Semantic_STS_V2, as this maps sentences/paragraphs to a 1024 dimensional vector space, just the number of dimensions I can configure for Elasticsearch.
I want to use Java for this, I need a library to generate the embeddings and Deep Java Library was it. In order to be able to work with a Hugging Face model you need to convert it first by checking out the Deep Java Library repository and run something like
cd extensions/tokenizers
python3 src/main/python/model_zoo_importer.py -m aari1995/German_Semantic_STS_V2
This will result in a zip file, that can be used in the Java code to load the model.
Criteria<String, float[]> criteria = Criteria.builder()
.setTypes(String.class, float[].class)
.optModelPath(Paths.get("/Users/alr/devel/djl/extensions/tokenizers/model/nlp/text_embedding/ai/djl/huggingface/pytorch/aari1995/German_Semantic_STS_V2/0.0.1/German_Semantic_STS_V2.zip"))
.optEngine("PyTorch")
.optTranslatorFactory(new TextEmbeddingTranslatorFactory())
.optProgress(new ProgressBar())
.build();
ZooModel<String, float[]> model = criteria.loadModel();
Predictor<String, float[]> predictor = singleModel.newPredictor();
Running predictor.predict(someTextHere)) returns an array of floats, that
can be used.
I tried the above code and it was slooooooooow. First rule of java
speed ups: utilize more cores. Instead of a single predictor I created a
thread pool of n size and created a Runnable that kept running on each
core while polling from the earlier mentioned ArrayBlockingQueue
- Poll
ArrayBlockingQueueand wait, if no new element is in there - On new element check if it has already been indexed into Elasticsearch. If already indexed, go to 1
- Create Embeddings, index into Elasticsearch
I tried the above code and it was slooooooooooooooow (again), albeit a little faster. Turns out that my M1 notebook has a GPU, why not use it? After reading a bit, the following code snippet was the way to go:
Criteria<String, float[]> criteria = Criteria.builder()
.optDevice(Device.of("mps", -1))
...
However that returned an exception. After asking on the DJL slack, the author created a Pull Request that fixed my issue in the 0.26-SNAPSHOT version. Thanks for the help.
Now, when running on the GPU, things were much faster.
In order to speed things up a little further, I stopped creating an embedding for every paragraph, but merged two paragraphs together, if they had less than 300 tokens.
Just for the record, these were the dependencies I used for make this work with my M1 GPU
implementation("ai.djl.huggingface:tokenizers:0.26.0-SNAPSHOT")
implementation("ai.djl.pytorch:pytorch-model-zoo:0.26.0-SNAPSHOT")
// GPU support on osx
implementation("ai.djl.pytorch:pytorch-native-cpu:2.1.1:osx-aarch64")
implementation("ai.djl.pytorch:pytorch-jni:2.0.1-0.25.0")
Indexing into Elasticsearch
Before indexing can happen, a mapping needs to be configured
client.indices().create(b -> b
.index("wikipedia-german")
.mappings(mb -> mb
.properties("title", pb -> pb.text(t -> t))
.properties("content", pb -> pb.text(t -> t))
.properties("paragraphs", pb -> pb.nested(nb -> nb
.properties("vector", vb -> vb.denseVector(t -> t.dims(1024)))
.properties("text", tb -> tb.text(t -> t.index(false))))
)
)
);
There is a title and content field for regular full text search and a
paragraphs field that is
nested
as it contains each paragraph as its own document. This strategy is outlined
in the Elasticsearch
docs.
With this in place, the final code to parse, create and index the data looks
like a bunch of Runnables in a thread pool, each doing the following. I
omitted exception handling, logging, statistics collection and more for
readability.
while (!isFinished.get()) {
WikiPage page = blockingQueue.take();
// create ID
byte[] digest = MessageDigest.getInstance("MD5")
.digest(page.title().getBytes(StandardCharsets.UTF_8));
String id = HexFormat.of().formatHex(digest).toLowerCase(Locale.ROOT);
// skip if this page has been indexed already
boolean idExistsAlready = elasticsearchIngester.exists(id);
if (idExistsAlready) {
continue;
}
// create embeddings
String text = page.toText();
Map<String, float[]> paragraphs = embeddings.createEmbeddingsFromInput(text);
WikipediaEntry entry = new WikipediaEntry(page.title(), text, paragraphs);
// add to bulk ingester
bulkIngester.add(op -> op.index(idx -> idx.index("wikipedia-german").id(id).document(entry)));
}
In order to not index every document by itself or write complex code to
regurlarly flush a queue, the Elasticsearch Java Client offers a
BulkIngester class, that is configured like this:
this.ingester = BulkIngester.of(b -> b
.client(client)
.maxSize(10_000_000) // 10 MB
.maxOperations(1000)
.flushInterval(1, TimeUnit.MINUTES)
.maxConcurrentRequests(1)
);
Again, as this is not the bottleneck I decided not to invest a lot of time to tune or test. With the embeddings generation moved to the GPU I could probably reduce the number of threads in my thread pool.
Now I have a component reading XML and indexing into Elasticsearch, which works incrementally. Time to take a look if all this work was worth it.
Adding a small web app
A small web application is nicer to the eye than a CLI in this case. I opted for a single page implementation with Javalin. That single page allows to execute a full text search or a vector search and display results side by side.
Regular search is implemented like this:
// exclude the paragraphs/vectors in the document response
SourceConfig sourceConfigExcludes = new SourceConfig.Builder()
.filter(SourceFilter.of(f -> f.excludes("paragraphs"))).build();
app.post("/search-fts", ctx -> {
String q = ctx.formParam("q");
SearchResponse<Query.WikipediaEntry> response = client.search(s -> s
.query(qb -> qb.match(mq -> mq.field("content").query(q).minimumShouldMatch("80%")))
.source(sourceConfigExcludes),
Query.WikipediaEntry.class);
ctx.result(renderResults(response, q));
});
I would never run such a basic search in production, but for testing it’s acceptable.
The knn search looks like this including to generate the embeddings for
the incoming query:
app.post("/search-vector", ctx -> {
String q = ctx.formParam("q");
float[] vectors = embeddings.createSingleEmbeddingsFromInput(q);
List<Float> embeddingsAsList = IntStream.range(0, vectors.length)
.mapToDouble(i -> vectors[i]).boxed().map(Double::floatValue).toList();
SearchResponse<Query.WikipediaEntry> response = client.search(s -> s
.source(sourceConfigExcludes)
.knn(k -> k.field("paragraphs.vector").k(10).numCandidates(1000).queryVector(embeddingsAsList))
, Query.WikipediaEntry.class);
ctx.html(renderResults(response, q));
})
The k and numCandidates numbers are not representative, I play
around with those a lot. The renderResults() method renders only a snippet
of HTML, as I use htmx to render a part of page
when running a search. This is the whole index.html page:
<!DOCTYPE html>
<html lang="de">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/sakura.css/css/sakura.css" type="text/css">
<script src="https://unpkg.com/htmx.org@1.9.9"></script>
<title>Semantic Search vs. Text Search</title>
</head>
<body>
<h1>FTS vs. Semantic Search</h1>
<p>
<form>
<input type="text" size="40" placeholder="<Search query goes here>" name="q">
<button hx-post="/search-fts" hx-target="#fts">Search FTS</button>
<button hx-post="/search-vector" hx-target="#vector">Search Vector</button>
</form>
</p>
<div style="display: flex;">
<div style="flex: 1; border: 1px solid lightgray; margin-right: 20px;">
<h6>FTS</h6>
<div id="fts">
</div>
</div>
<div style="flex: 1; border: 1px solid lightgray;">
<h6>Vector</h6>
<div id="vector">
</div>
</div>
</div>
</body>
</html>
All right, time for some basic comparison, while also able to change the searches if needed within the web application.
Testing the search
Given the fact that I indexed a really small part of that dump (about 100k documents, total is around 5.5 million, but that includes all pages including redirects, lists, etc) the results cannot be perfect. But let’s try a few searches.
Let’s start with Schnellster Sprinter - roughly translates to fastest
runner.

Now here the semantic search looks like the better results, as almost every hit is a either a runner or a cyclist.
Let’s try Wer hat den Mount Everest bestiegen - who climbed Mount Everest?

Mixed results here for both, between people climbing Mount Everest as well as links to other mountains. Maybe a little better for vector search.
Searching for Schnellstes Auto - fastest car.
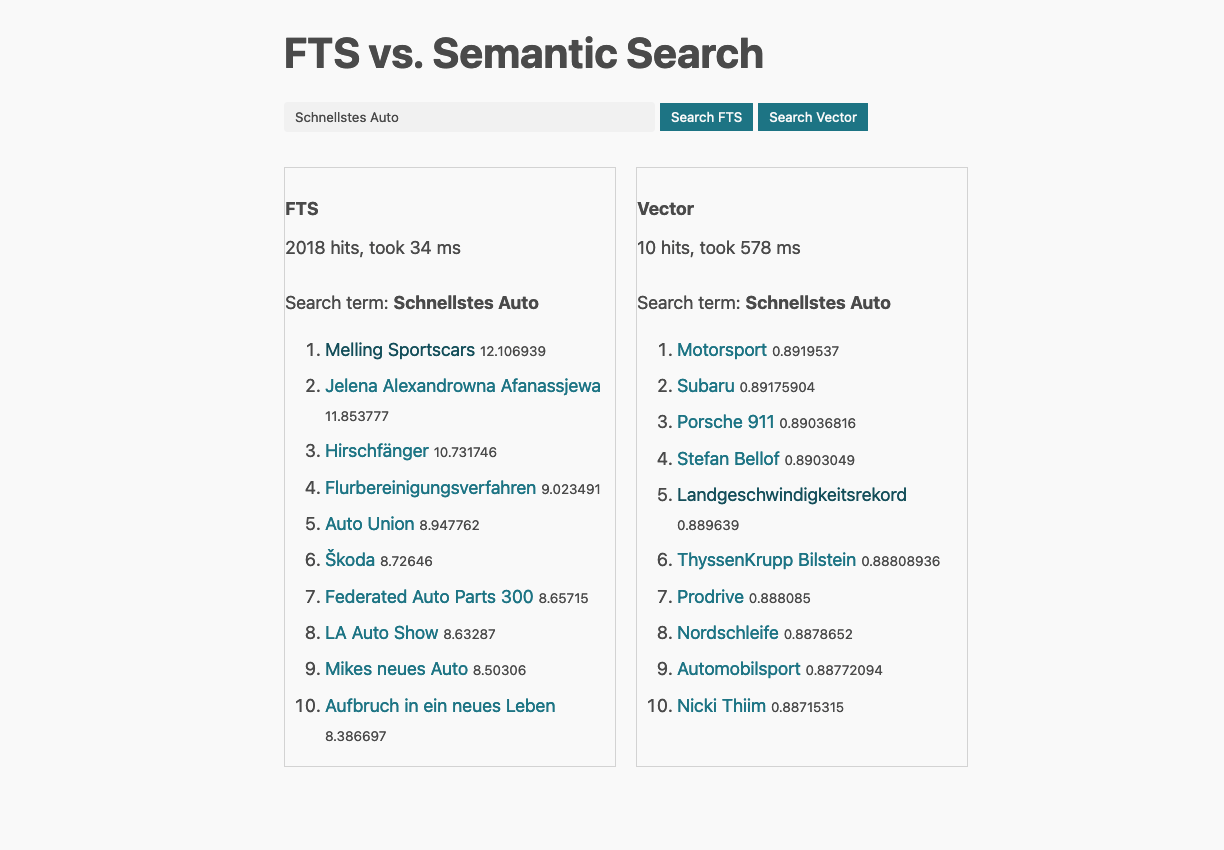
Ok, this result seems confusing to me, not the vector search, but the regular one.
Why is a runner on second spot? Well, if you select minimum_should_match
as 80%, then a single term is sufficient for a valid match. You probably
want to tune this to something like 2<80% to make sure that searches
consisting of two terms are producing more exact results. If the search
gets tweaked however, then a single document is found within my dataset for
the above search term and that is the yearly overview of 1997. Welcome
precision and recall.
One more thing: In case you are wondering about the varying response times like in the screenshot above. I took those screenshots, while indexing, creating embeddings, running Elasticsearch on my local notebook utilizing every core. Most of the searches vector search is slightly slower, but not magnitudes, if the system is not under load.
The regular search shines on searches like Usian Bolt with a lot of speed,
where as the vector search allows more of a browsing experience, showing
different athletes with a focus on sprinters. As usual, it’s always a
question on what you prefer as a search result. That result diversification
might be good for Wikipedia or e-commerce searches, but bad for person
search engine.
I could go on with dozens of results here, not making my little experiment any more scientific or come up with new ideas. Given the above search terms, it is clear that those were made for showing vector search capabilities but may be different compared to your regular searches.
Summary
Biggest learning for me: I have work to do - and learn more.
Indexing speed
Let’s talk about the elephant in the room first: Indexing speed. Even with GPU support it’s still bad. I kept my indexer running in the background the last six hours and indexed 29k additional documents with 193k embeddings. That’s an indexing rate of about less than 10 embeddings per second, which is still abysmal for any use-case with lots of updates (ECommerce for example, even though something like the product description probably gets updated less often). Apparently indexing a lot of documents requires decent hardware with GPU cores somewhere. Maybe my Java integration is just bad either, and in fact it could be much faster, I don’t know yet.
It is hard to test things, it’s hard to validate an assumption without having more indexing speed, which makes it cumbersome to PoC anything around vector search.
My current dataset is 150k documents with 530k nested docs. I have no idea what amount of pages I would exclude, but when you want to index 3 million wiki pages with 10 million embeddings in 24h, you would need to be able to 115 embeddings per second, 10x the speed that I am able to run locally.
And just for your information, those 150k documents take about 11gb of disk space.
What is the best way to solve this to reach proper prototyping speed nowadays? Answers welcome!
And one more thing: This is not only an indexing problem. As we also need to create embeddings when querying, running at hundreds of queries per second may be a major performance issue.
Configuration
On the one hand I had to jump through a couple of hoops until I had embeddings created, but all in all the work done in two afternoons/evenings of playing around, without ever having done it before or dealing with Mediawiki text or syntax.
Still there are cases where the amount of work to be done is too much. For Elasticsearch: Why can’t I specify a mapping with the number of tokens per paragraph instead of configuring a nested field. This needs to be easier. Why can’t I configure a mapping, and then the inference processor gets to work automatically? I think the simplification on the indexing side can be massive. Also, GPU support natively in Elastic Cloud would probably be a massive win, ditching any local requirements.
One more on the Elasticsearch side: Why do I need some external python tool to import a Hugging Face model? Why isn’t there a CLI tool in my Elasticsearch installation - or even an automatic download, if it is treated as a first class citizen and the model could just be selected in the configuration? I skipped this step due to creating embeddings per paragraph that I had to do locally anyway, but I think in the future all of that will fall into the responsibility of the vector engine.
Ease of use/configuration is a major issue (it’s not just Elasticsearch, but many other systems in that space as well) and I guess this will be one of the deciding factors for all the systems out there in the next months regarding adoption.
Choosing good defaults?
Here I struggle the most due to missing experience. What is a good default of the number of tokens? Should I create embeddings per sentence, per paragraph or try to do this based on length?
Did I strip the correct HTML out of the article? How can I test this at proper scale? With enough data, maybe all that work is not needed and I still get good results?
Again due to indexing speed it’s a lot of work to test out hypotheses.
In addition I am not a domain expert on wiki data, next time it makes more sense to test anything like that with real data from a proper use-case and then test results with a similar setup may be massively different.
Also in general, how do I figure out if I picked the right model? Is there another better model for German articles?
Everyone needs to become a ML engineer now?
It’s one of the things on my map. On top of understanding search I think it is really important to understand machine learning/data scientist foundations as both will probably merge more and more over time.
Understand algorithms, understand the different vector search implementations (HNSW, IVFFlat, DiskANN, SPANN), but also the differences in implementations of different systems, as not every implementation is the same.
Hybrid search
The current trend of search engines adding vector search and vector engines adding search (keyword search & filtering) shows that hybrid search is a requirement. As usual, some thought needs to be spent on how to combine different scores, for example via RRF.
Let’s see who adapts faster in this battle. I picked Elasticsearch mainly because I know that system best and tried to keep moving parts small.
Another complexity is catering for two audiences. There are folks who are using a search engine like you would use a BM25 matching search engine, and there are folks who are searching like vector would be the better match. How do you combine those two? Running both searches and letting the user decide? This is a hard problem to solve.
Also, how is personalization incorporated into this?
Running & monitoring in production
This is something I need to think about more. Measuring vector search quality with a local data set for example. Is there a difference to monitoring regular search applications at all? Can we run A/B tests properly, for example with different models?
This is not part of this blog post, but I am more than open for ideas and experiences regarding that.
Resources
- The Library and the Maze: A fantastic intro into vectors and semantic search based on python notebooks
- Searching for meaning: A fantastic intro to start with semantic search and Elasticsearch
- Multilingual vector search with the E5 embedding model
- Vector Search (kNN) Implementation Guide: Small guide for using kNN with Elasticsearch
- Chunking Large Documents via Ingest pipelines plus nested vectors equals easy passage search: Intro into chunking with Elasticsearch using Painless, but I’m not sure this is a better idea than doing it myself
- Adding passage vector search to Lucene: How using nested documents allows to store and search several paragraphs in a single Lucene document and make it available for vector search
- Elastic Documentation: nested kNN search
Final remarks
If you made it down here, wooow! Thanks for sticking with me. You can follow or contact me on mastodon, GitHub, LinkedIn or reach me via Email (just to tell me, you read this whole thing :-).
If there is anything to correct, drop me a note, and I am happy to fix and append a note to this post!
Same applies for questions. If you have question, go ahead and ask!
If you want me to speak about this, drop me an email!